点一下关注吧!!!非常感谢!!持续更新!!!
目前已经更新到了:
Hadoop(已更完)HDFS(已更完)MapReduce(已更完)Hive(已更完)Flume(已更完)Sqoop(已更完)Zookeeper(已更完)HBase(已更完)Redis (已更完)Kafka(正在更新…)章节内容
上节我们完成了如下内容:
Kafka 一致性保证LogAndOffset(LEO)HightWatermark(HW)Leader和Follower何时更新 LEOLeader和Follower何时更新 HW
基本介绍
消息重复和丢失是Kafka中很常见的问题,主要发生在以下三个阶段:
生产者阶段Broke阶段消费者阶段生产者阶段丢失
出现场景
生产者发送消息没有收到正确Broke的响应,导致生产者重试。
生产者发送出一条消息,Broker落盘以后因为网络等种种原因发送端得到一个发送失败的响应或者网络中断,然后生产者收到一个可恢复的Exception重试消息导致消息重复。
重试过程
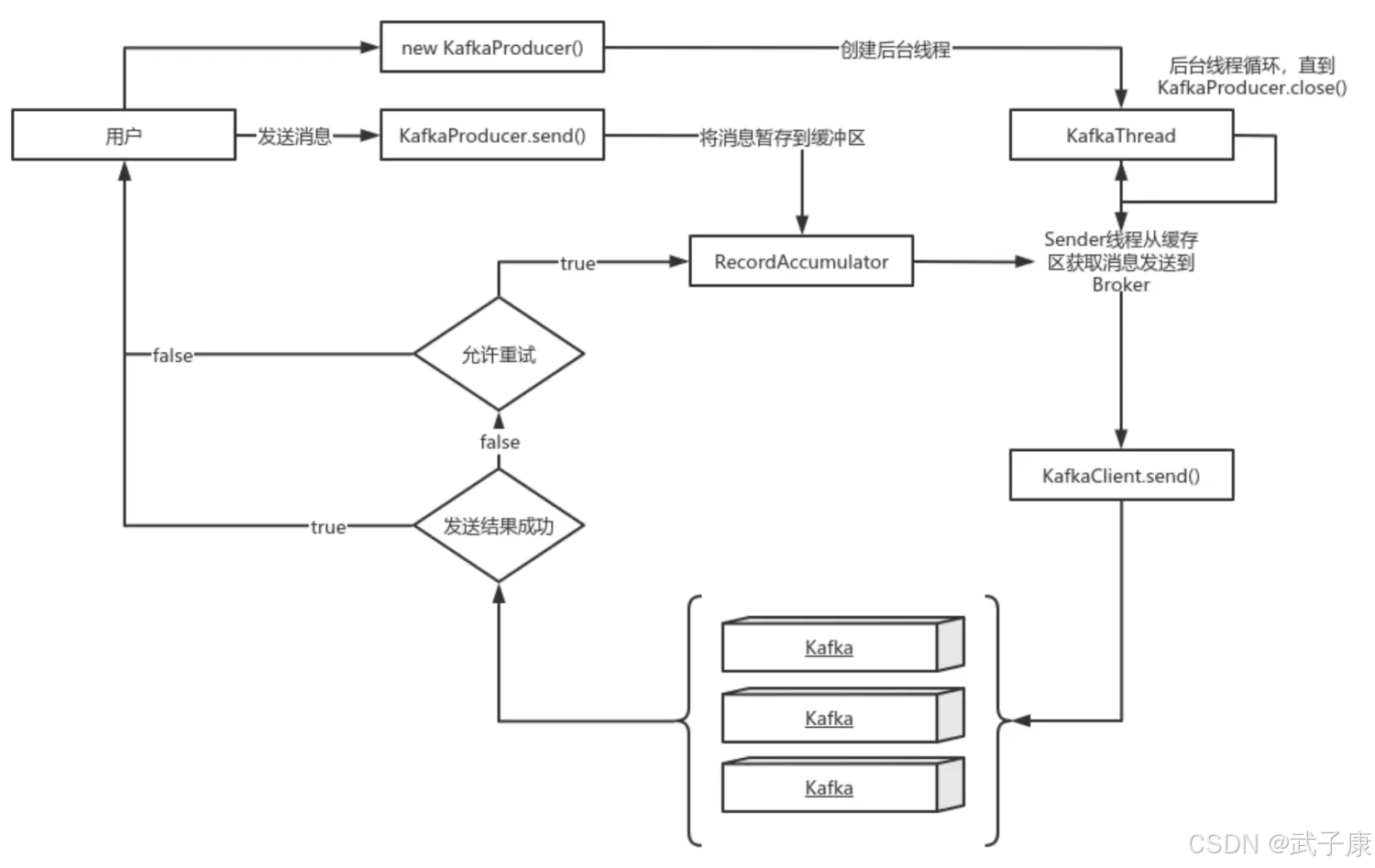
上图说明:
可恢复异常
异常是 RetriableException类型 或者 TransactionManager允许重试,RetriableException类集成关系如下:
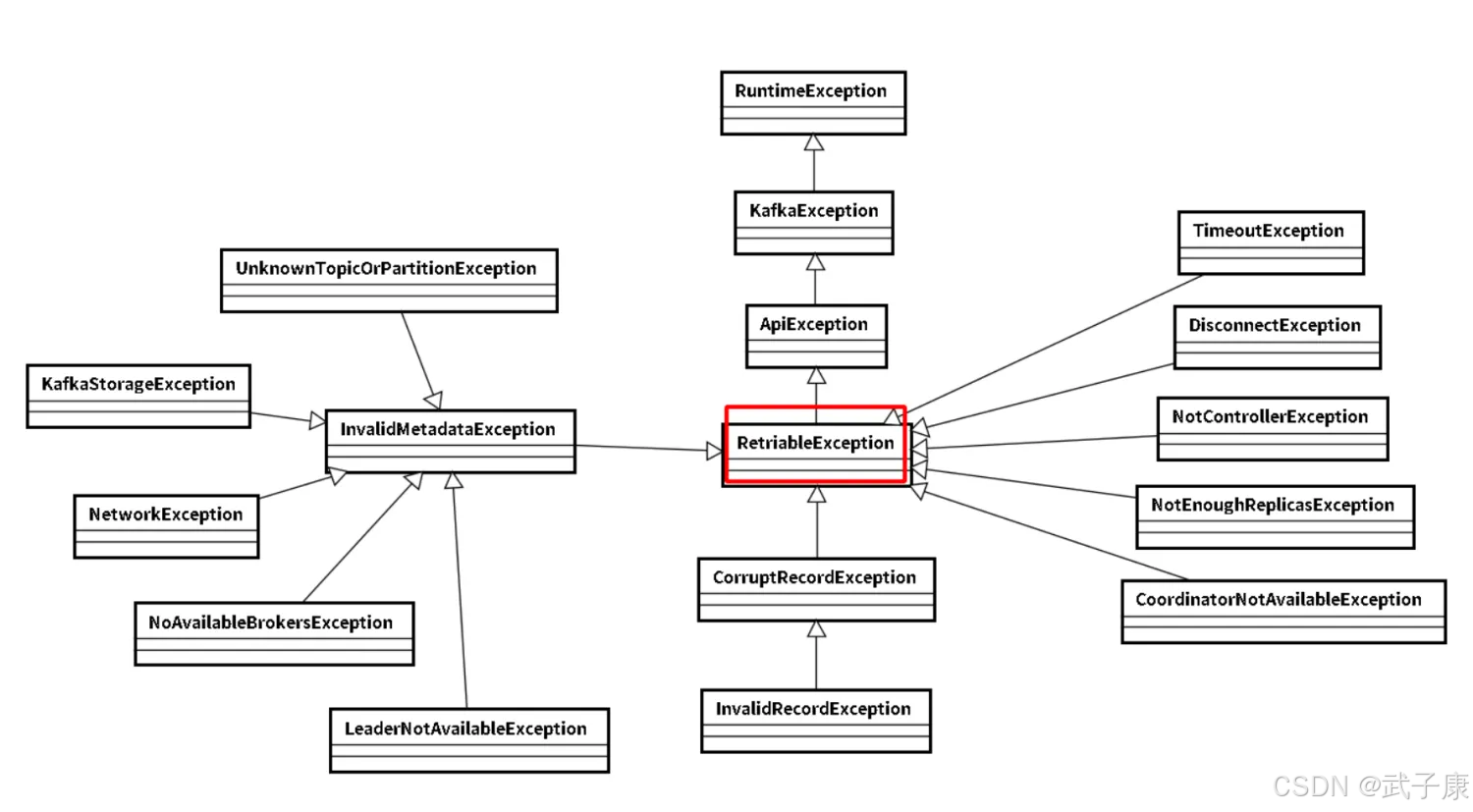
消息顺序问题
如果设置max.in.flight.requests.per.connection大于1(默认5,单个连接上发送的未确认的请求的最大数量,表示上一个发出的请求没有确认下一个请求又发出去了)。大于1可能会改变记录的顺序,因为如果将两个Batch发送到单个分区,第一个batch处理失败并重试,但是第二个batch处理成功,那么第二个batch处理中的记录可能先出现被消费掉。如果设置max.in.flight.requests.per.connection等于1,则可能会影响吞吐量,可以解决单个生产者发送顺序问题,如果多个生产者,生产者1先发送一个请求,生产者2后发送请求,此时生产者1返回可恢复异常,且重试成功,此时虽然1先发送,但是2是先被消费的。解决方案
幂等性
启动Kafka幂等性:
enable.idempotence=trueack=allretries>=1ack=0且不重试
可能会丢失消息,适用于吞吐量指标重要性高于数据丢失,比如:日志采集。
生产者-Broker阶段丢失
出现场景
ack=0且不重试
生产者发送消息完,不管结果了,如果发送失败也就丢失了
ack=1, Leader宕机
生产者发送完消息,只等待Leader写入成功就返回了,Leader分区丢失了,此时Follower没来得及同步,消息丢失。
unclean.leader.election.enable配置为true
允许选举ISR以外的副本作为Leader,会导致数据丢失,默认为False。生产者发送异步消息,只等待Leader写入成功就返回,Leader分区丢失,此时ISR中就没有Follower,Leader从OSR中选举,因为OSR中本来就落后于Leader,造成了消息的丢失。
解决方案
禁用unclean选举 ACK=ALL
ack=all 或者 -1tries > 1unclean.leader.election.enable = false生产者发送完消息后,等待Follower同步完再返回,如果异常则重试。副本的数量可能影响吞吐量,不超过5个,一般是3个。
不允许unclean的Leader参与选举。
min.insync.replicas > 1
当生产者acks设置all(或-1)时,min.insync.replicas > 1。指定确认消息写成功需要的最小副本数量。达不到这个最小值,生产者将引发一个异常。(可能是NotEnoughReplicas,可能是NotEnoughReplicasAfterAppend)。
当一起使用时,min.insync.replicas和ack允许执行更大的持久性保证。一个典型的场景是创建一个复制因子为3的主题,设置min.insync复制到2个,用all配置发送。将确保如果大多数副本没有收到写操作,则生产者将引发异常。
失败的offset单独记录
生产者发送消息,会自动重试,遇到不可能恢复异常会跳出。这是可以捕获异常记录到数据库或者缓存,进行单独的处理。
消费者数据重复场景
出现场景
数据消费完没有及时的提交offset到Broker。
消费消息端在消费过程中挂掉没有及时的提交offset到Broker,另一个消费端启动之后拿到之前的offset记录开始消费,由于offset的滞后性可能会导致启动的客户端有少量的重复消费。
解决方案
取消自动提交
每次消费完或者程序退出时手动提交,这可能也没法保证一条重复。
下游做幂等
一般是让下游做幂等或者尽量每消费一条消息都记录offset,对于少数严格的场景可能需要把offset或唯一ID(例如订单ID)和下游状态更新放在同一个数据库里做事务来保证精确的一次更新。
或在下游数据表里同时记录消费offset,然后更新下游数据时用消费位移做乐观锁拒绝旧位移的数据更新
__Consumer_offsets
ZooKeeper不适合大批量的频繁写入操作
Kafka1.0.2将Consumer的位移信息保存在Kafka内部的topic中,即__consumer_offsets主题,并且默认提供了kafka-consumer-groups.sh脚本供用户查看consumer的信息。