第一章 XML概述
1.1 XML介绍
1.1.1 什么是XML
XML 指可扩展标记语言(EXtensible Markup Language)
XML 是一种标记语言,很类似 HTML,HTML文件也是XML文档
XML 的设计宗旨是传输数据,而非显示数据
XML 标签没有被预定义。您需要自行定义标签。
XML 被设计为具有自我描述性(就是易于阅读)。
XML 是 W3C 的推荐标准
W3C在1988年2月发布1.0版本,2004年2月又发布1.1版本,单因为1.1版本不能向下兼容1.0版本,所以1.1没有人用。同时,在2004年2月W3C又发布了1.0版本的第三版。我们要学习的还是1.0版本。
1.1.2 XML 与 HTML 的主要差异
XML 不是 HTML 的替代。XML 和 HTML 为不同的目的而设计。XML 被设计为传输和存储数据,其焦点是数据的内容。HTML 被设计用来显示数据,其焦点是数据的外观。HTML 旨在显示信息,而 XML 旨在传输信息。1.1.3 XML文件案例编写person.xml文件
1.1.3.1 需求
编写xml文档,用于描述人员信息,person代表一个人员,id是人员的属性代表人员编号。人员信息包括age年龄、name姓名、sex性别信息。
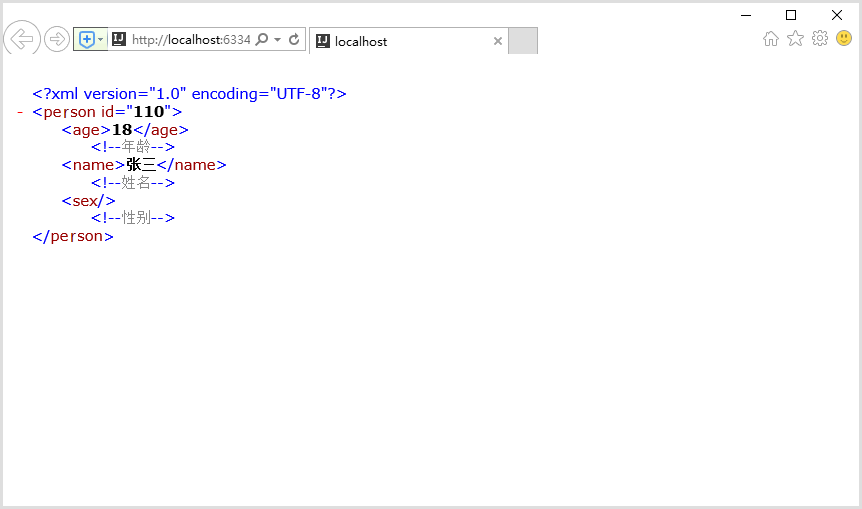
1.1.3.2 效果
使用浏览器运行person.xml文件效果如下
1.1.3.3 实现步骤
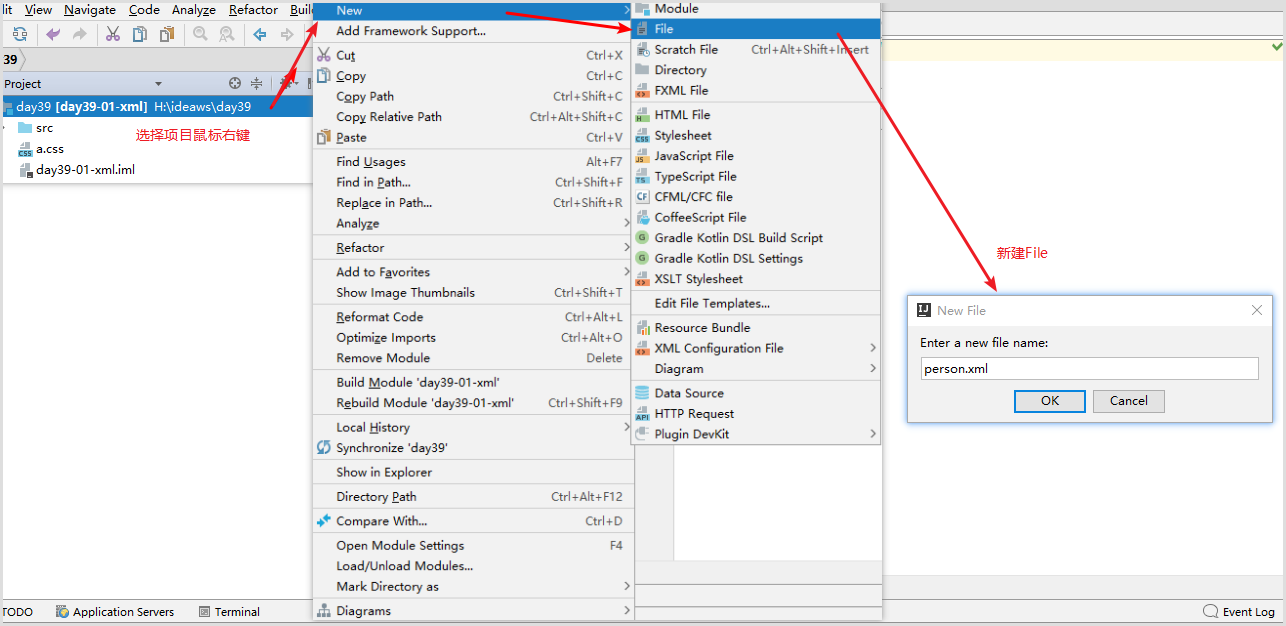
步骤1:使用idea开发工具,选择当前项目鼠标右键新建“”,如图
步骤2:编写文件person.xml文件,内容如下:
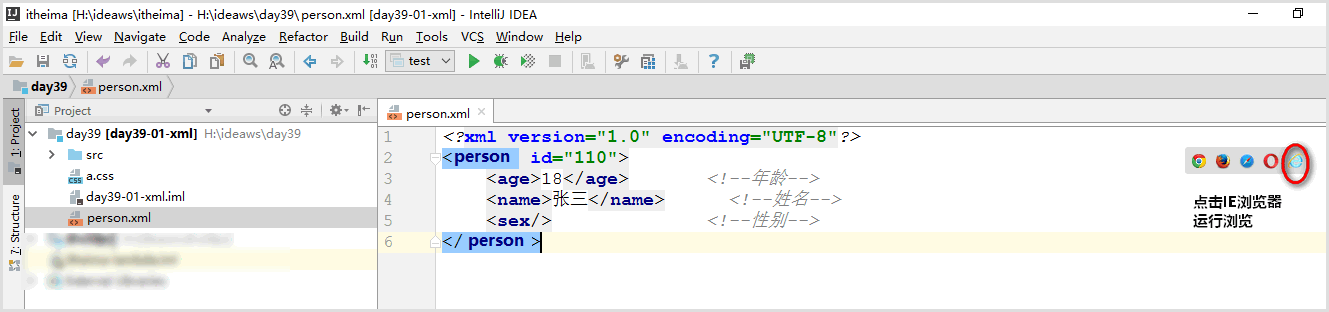
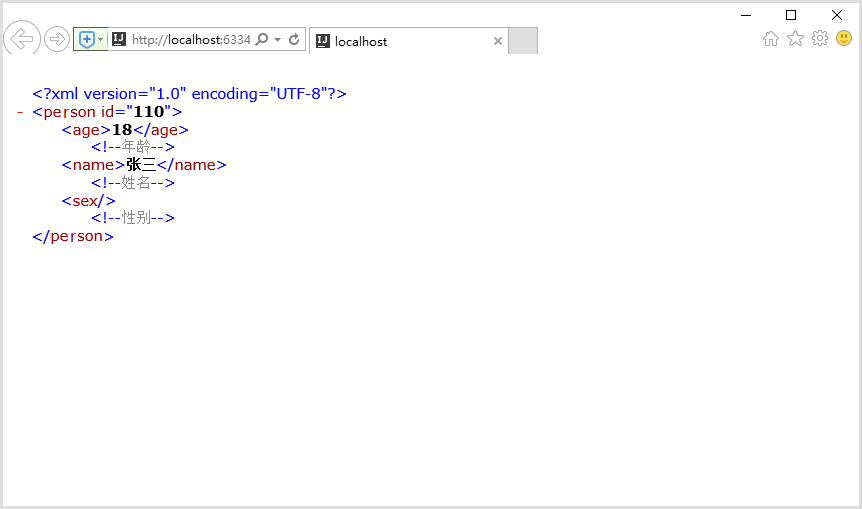
<?xml version="1.0" encoding="UTF-8"?><person id="110"><age>18</age><!--年龄--><name>张三</name> <!--姓名--><sex/><!--性别--></person>步骤3:如图点击浏览器运行
步骤4:浏览器运行效果如下
1.2 XML作用
XML在企业开发中主要有两种应用场景:
1)XML可以存储数据 , 作为数据交换的载体(使用XML格式进行数据的传输)。
2)XML也可以作为配置文件,例如后面框架阶段我们学习的Spring框架的配置(applicationContext.xml)都是通过XML进行配置的(企业开发中经常使用的)
1.3 XML的组成元素
XML文件中常见的组成元素有:文档声明、元素、属性、注释、转义字符、字符区。
1.3.1 文档声明
<?xml version="1.0" encoding="utf-8" ?>1.3.2 元素element
格式1:<person></person>格式2:<person/><person><name>张三</name></person>空元素:空元素只有标签,而没有结束标签,但元素必须自己闭合,例如:<sex/>元素命名 区分大小写不能使用空格,不能使用冒号不建议以XML、xml、Xml开头 格式化良好的XML文档,有且仅有一个根元素。 1.3.3 属性
<person id="110">1.3.4 注释
<!--注释内容-->XML的注释与HTML相同,既以<!--开始,-->结束。
1.3.5 转义字符
XML中的转义字符与HTML一样。因为很多符号已经被文档结构所使用,所以在元素体或属性值中想使用这些符号就必须使用转义字符(也叫实体字符),例如:“>”、“<”、“'”、“”“、”&"。
| 字符 | 预定义的转义字符 | 说明 |
|---|---|---|
| < | < | 小于 |
| > | > | 大于 |
| " | " | 双引号 |
| ’ | ' | 单引号 |
| & | & | 和号 |
注意:严格地讲,在 XML 中仅有字符 “<“和”&” 是非法的。省略号、引号和大于号是合法的,但是把它们替换为实体引用是个好的习惯。
转义字符应用示例:
假如您在 XML 文档中放置了一个类似 “<” 字符,那么这个文档会产生一个错误,这是因为解析器会把它解释为新元素的开始。因此你不能这样写:
<message>if salary < 1000 then</message>为了避免此类错误,需要把字符 “<” 替换为实体引用,就像这样:
<message>if salary < 1000 then</message>1.3.6 字符区(了解)
<![CDATA[文本数据]]>注意:
CDATA 部分不能包含字符串 “]]>”。也不允许嵌套的 CDATA 部分。
标记 CDATA 部分结尾的 “]]>” 不能包含空格或折行。
1.4 XML文件的约束
在XML技术里,可以编写一个文档来约束一个XML文档的书写规范,这称之为XML约束。
常见的xml约束:DTD、Schema
注意:对于约束的要求是能通过已写好的约束文件编写xml文档.了解即可
1.4.1 DTD约束
1.4.1.1 概念
DTD是文档类型定义(Document Type Definition)。DTD 可以定义在 XML 文档中出现的元素、这些元素出现的次序、它们如何相互嵌套以及XML文档结构的其它详细信息。
1.4.1.2 约束体验
步骤1:新建bookshelf.dtd文件,选择项目鼠标右键“NEW->File",文件名为“bookshelf.dtd”
步骤2:bookshelf.dtd文件内容如下
<!ELEMENT 书架 (书+)><!ELEMENT 书 (书名,作者,售价)><!ELEMENT 书名 (#PCDATA)><!ELEMENT 作者 (#PCDATA)><!ELEMENT 售价 (#PCDATA)>步骤3:新建books.xml,代码如下
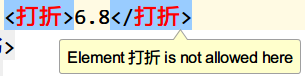
<?xml version="1.0" encoding="UTF-8" ?><!DOCTYPE 书架 SYSTEM "bookshelf.dtd"><书架> <书> <书名>JavaEE SSM</书名> <作者>NewBoy</作者> <售价>30</售价> </书> <书> <书名>人鬼情喂鸟</书名> <作者>李四</作者> <售价>300</售价> </书></书架>步骤4:idea开发工具books.xml的dtd约束验证不通过的效果
1.4.2 schema约束
1.4.2.1 概念
Schema 语言也可作为 XSD(XML Schema Definition)。
Schema 比DTD强大,是DTD代替者。
Schema 本身也是XML文档,单Schema文档扩展名为xsd,而不是xml。
Schema 功能更强大,数据类型约束更完善。
1.4.2.2 使用
步骤1:新建schema约束文件bookshelf.xsd,对售价约束数据类型,代码如下:<?xml version="1.0" encoding="UTF-8" ?><xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itcast.cn" > <xs:element name='书架'> <xs:complexType> <xs:sequence maxOccurs='unbounded'> <xs:element name='书'> <xs:complexType> <xs:sequence> <xs:element name='书名' type='xs:string'/> <xs:element name='作者' type='xs:string'/> <xs:element name='售价' type='xs:double'/> </xs:sequence> </xs:complexType> </xs:element> </xs:sequence> </xs:complexType> </xs:element></xs:schema>bookshelf.xsd
<根元素 xmlns="命名空间" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="命名空间 xsd约束文件名"></根元素>book2.xml
<?xml version="1.0" encoding="UTF-8" ?><书架 xmlns="http://www.itcast.cn" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://www.itcast.cn bookshelf.xsd" > <书> <书名>JavaEE</书名> <作者>张三</作者> <售价>39</售价> </书> <it:书> <书名>西游记</书名> <作者>吴承恩</作者> <售价>3000</售价> </it:书></书架>步骤3:违反约束,开发工具提示效果

第二章 xml解析
2.1 XML解析
2.1.1 解析概述
当将数据存储在XML后,我们就希望通过程序获取XML的内容。如果我们使用Java基础所学的IO知识是可以完成的,不过你学要非常繁琐的操作才可以完成,且开发中会遇到不同问题(只读、读写)。人们为不同问题提供不同的解析方式,使用不同的解析器进行解析,方便开发人员操作XML。
2.1.2 解析方式和解析器
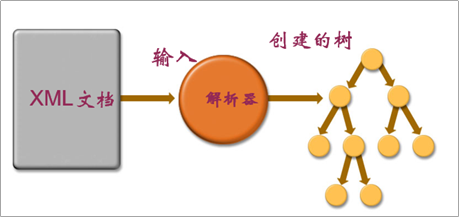
开发中比较常见的解析方式有三种,如下:
DOM:要求解析器把整个XML文档装载到内存,并解析成一个Document对象
a)优点:元素与元素之间保留结构关系,故可以进行增删改查操作。
b)缺点:XML文档过大,可能出现内存溢出
SAX:是一种速度更快,更有效的方法。她逐行扫描文档,一边扫描一边解析。并以事件驱动的方式进行具体解析,没执行一行,都触发对应的事件。(了解)
a)优点:处理速度快,可以处理大文件
b)缺点:只能读,逐行后将释放资源,解析操作繁琐。
PULL:Android内置的XML解析方式,类似SAX。(了解)
解析器,就是根据不同的解析方式提供具体实现。有的解析器操作过于繁琐,为了方便开发人员,有提供易于操作的解析开发包
常见的解析开发包
JAXP:sun公司提供支持DOM和SAX开发包Dom4j:比较简单的的解析开发包(常用)JDom:与Dom4j类似Jsoup:功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便(项目中讲解)2.2 XML文档生成DOM树原理
2.2.1 介绍
XML DOM 和 HTML DOM一样,XML DOM 将整个XML文档加载到内存,生成一个DOM树,并获得一个Document对象,通过Document对象就可以对DOM进行操作。以下面books.xml文档为例。
2.2.2 XML文件
<?xml version="1.0" encoding="UTF-8"?><books> <book id="0001"> <name>JavaWeb开发教程</name> <author>张孝祥</author> <sale>100.00元</sale> </book> <book id="0002"> <name>三国演义</name> <author>罗贯中</author> <sale>100.00元</sale> </book></books>XML文件document文档对象树DOM树
2.2.3 生成的DOM树
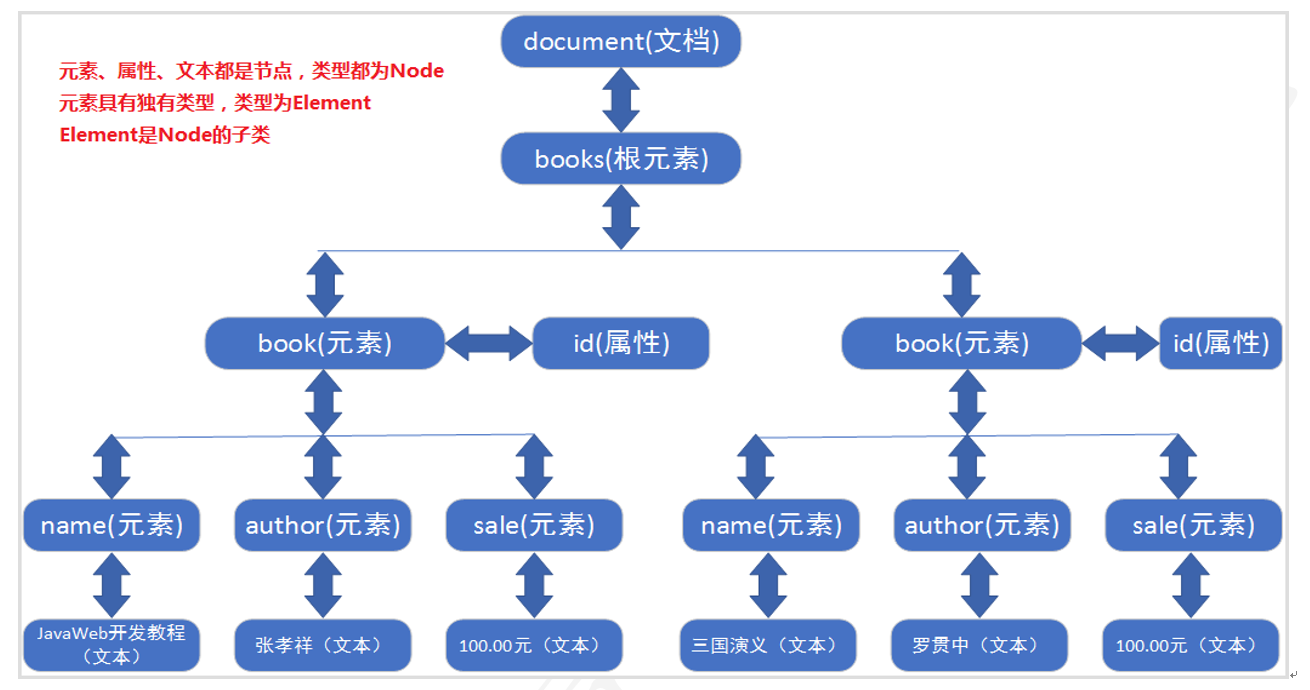
由于DOM方式解析XML文档所有都是节点Node,所有节点又都被封装到Document对象中,所以解析的重点就是获取Document对象。
第三章 Java中的XML解析
3.1 Dom4j的基本使用
3.1.2 常用的方法
SaxReader对象
| 方法 | 作用 |
|---|---|
| new SaxReader() | 构造器 |
| Document read(String url) | 加载执行xml文档 |
Document对象
| 方法 | 作用 |
|---|---|
| Element getRootElement() | 获得根元素 |
Element对象
| 方法 | 作用 |
|---|---|
| List elements([String ele] ) | 获得指定名称的所有子元素。可以不指定名称 |
| Element element([String ele]) | 获得指定名称第一个子元素。可以不指定名称 |
| String getName() | 获得当前元素的元素名 |
| String attributeValue(String attrName) | 获得指定属性名的属性值 |
| String elementText(Sting ele) | 获得指定名称子元素的文本值 |
| String getText() | 获得当前元素的文本内容 |
3.1.3方法演示
注意引入jar
https://github.com/shixiaochuangjob/markdownfile/tree/main/20240812/lib
“books.xml”,内容如下:
<?xml version="1.0" encoding="UTF-8"?><books> <book id="0001"> <name>JavaWeb开发教程</name> <author>张孝祥</author> <sale>100.00元</sale> </book> <book id="0002"> <name>三国演义</name> <author>罗贯中</author> <sale>100.00元</sale> </book></books>注意:为了便于解析,此xml中没有添加约束
解析此文件,获取每本书的id值,以及书本名称,作者名称和价格.
package com.xml.dom4j;import org.dom4j.Document;import org.dom4j.DocumentException;import org.dom4j.Element;import org.dom4j.io.SAXReader;import java.util.List;public class Demo { public static void main(String[] args) throws DocumentException { SAXReader reader = new SAXReader(); Document document = reader.read(Demo.class.getResourceAsStream("/books.xml")); // 获取根元素 books Element elemRoot = document.getRootElement(); // 获取根元素的所有子元素 book List<Element> list = elemRoot.elements(); // 遍历集合 获取每一个book for (Element element : list) { // 获取book的id属性 String id = element.attributeValue("id"); System.out.println("id : " + id); // 获取book下的所有子元素 name,author,sale List<Element> listElem = element.elements(); // 遍历集合 获取每一个子元素 for (Element elem : listElem) { // 元素名 String name = elem.getName(); // 文本值 String text = elem.getText(); System.out.println("--- " + name + " : " + text); } } }}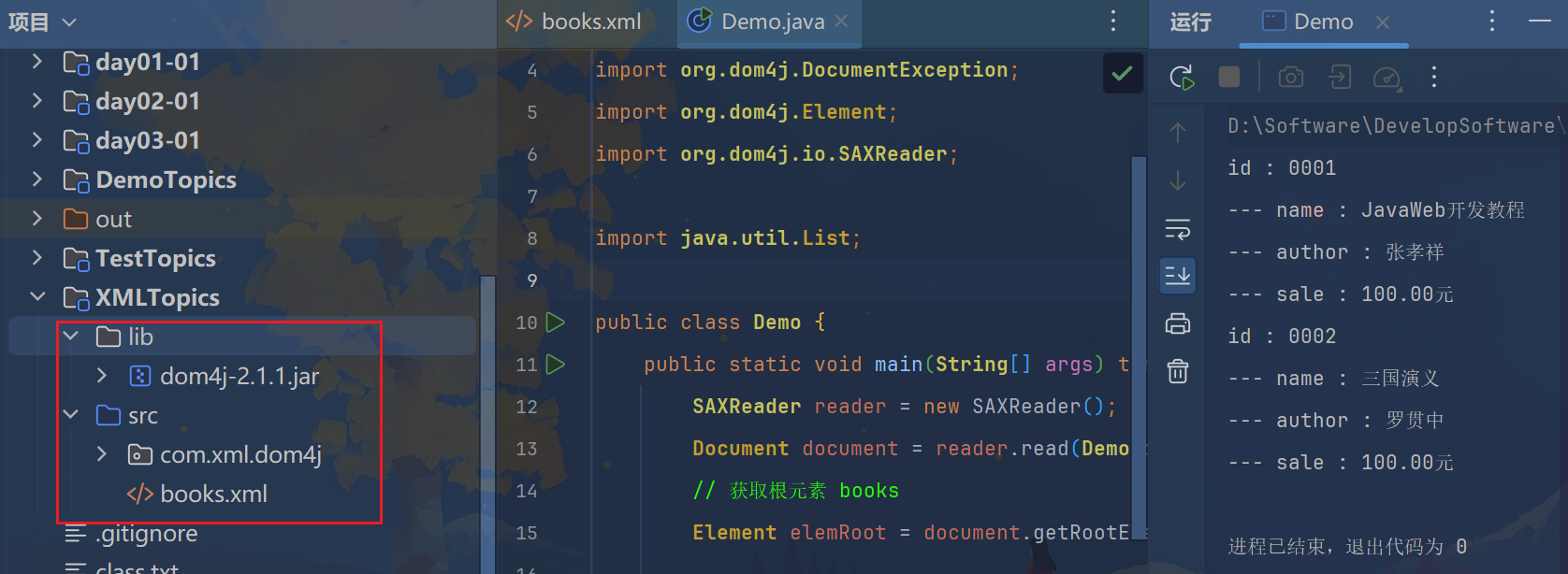
3.2 DOM的基本使用
<?xml version="1.0" encoding="UTF-8"?><persons> <person id="1"> <name>张三</name> <sex>男</sex> <age>30</age> <birthday>2000-12-12</birthday> </person> <person id="2"> <name>李四</name> <sex>男</sex> <age>35</age> <birthday>2001-12-12</birthday> </person> <person id="3"> <name>王五</name> <sex>男</sex> <age>33</age> <birthday>2008-12-12</birthday> </person> <person id="4"> <name>老六</name> <sex>男</sex> <age>50</age> <birthday>2010-12-12</birthday> </person> <person id="5"> <name>田七</name> <sex>女</sex> <age>30</age> <birthday>2002-12-12</birthday> </person></persons>package com.xml.dom;import java.io.InputStream;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import org.w3c.dom.Document;import org.w3c.dom.Element;import org.w3c.dom.NamedNodeMap;import org.w3c.dom.Node;import org.w3c.dom.NodeList;public class DomTest { public static void main(String[] args) { try { // 定义了一个DocumentBuilder工厂实例。 DocumentBuilderFactory factory = DocumentBuilderFactory .newInstance(); // 利用这个工厂,生产DocumentBuilder实例。 DocumentBuilder documentBuilder = factory.newDocumentBuilder(); // 指定xml文件, 并绑定一个流。 InputStream inputStream = Thread.currentThread() .getContextClassLoader().getResourceAsStream("persons.xml"); // 调用parse的方法,来指定xml文件。 Document document = documentBuilder.parse(inputStream); // 通过document对象获取到根元素。 Element rootElement = document.getDocumentElement(); // 根元素---->persons元素 // 获取persons下的所有的person元素。 5个person的Node节点。 NodeList personsNodeList = rootElement.getElementsByTagName("person"); for (int i = 0; i < personsNodeList.getLength(); i++) { // 这是一个person节点。 Node personNode = personsNodeList.item(i); // 通过节点Node获取这个节点中所有的属性集合。 NamedNodeMap attrs = personNode.getAttributes(); for (int j = 0; j < attrs.getLength(); j++) { Node attrNode = attrs.item(j); String attrName = attrNode.getNodeName(); String attrValue = attrNode.getNodeValue(); System.out.println(attrName + "=" + attrValue); } // 解决person节点下的所有的子元素|子节点。 NodeList childsNodeList = personNode.getChildNodes(); // 在childsNodeList中存在元素节点(4)和 5个空文本节点。 for (int k = 0; k < childsNodeList.getLength(); k++) { Node childNode = childsNodeList.item(k); // 过滤其中的元素节点。 if (childNode.getNodeType() == Node.ELEMENT_NODE) { // 既然是元素节点,我们就可以将node强制转换为element对象。 Element childElement = (Element) childNode; // Element对象可以比较方便的获取到标签的名称和标签中的文本内容。 String name = childElement.getTagName(); String value = childElement.getTextContent(); System.out.println(name + "------" + value); } } } } catch (Exception e) { e.printStackTrace(); } }}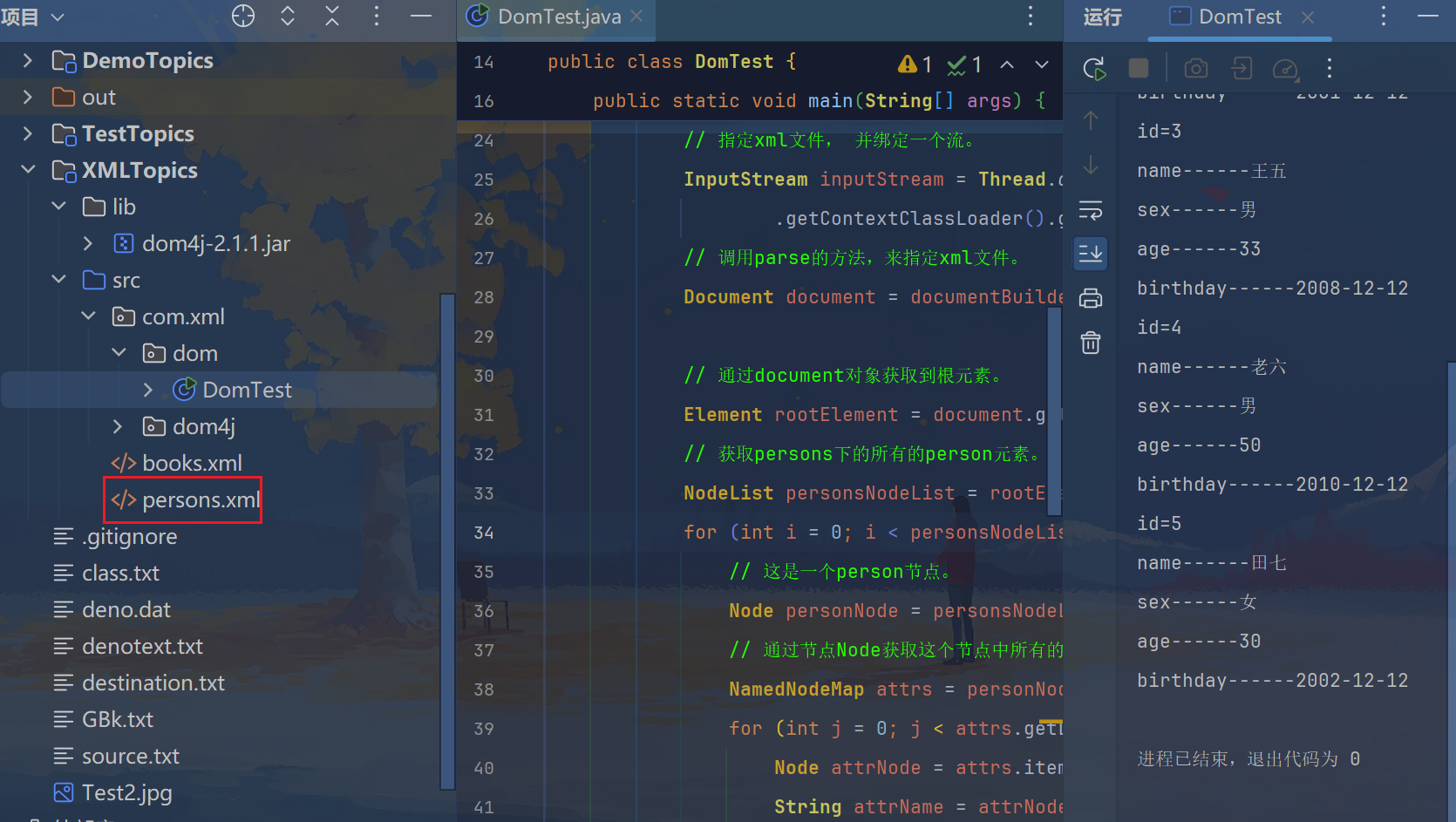
3.3 jdom的基本使用
https://github.com/shixiaochuangjob/markdownfile/tree/main/20240812/lib
package com.xml.jdom;import java.io.InputStream;import java.util.List;import org.jdom.Attribute;import org.jdom.Document;import org.jdom.Element;import org.jdom.input.SAXBuilder;public class JdomTest { /** * JDOM解析xml的运用: * <p> * 1、JDOM是第三方的开源组件,就意味着需要导入jar包。 * 2、JDOM仅仅只能是运用于java的开发平台下。 * 3、内部有关元素和属性的处理都是基于Collection的结构。 */ public static void main(String[] args) { try { SAXBuilder saxBuilder = new SAXBuilder(); // 创建一个流并绑定xml文件。 InputStream in = Thread.currentThread().getContextClassLoader() .getResourceAsStream("persons.xml"); // 获得xml所对应的document文档结构。 xml文件----->Dom树 Document document = saxBuilder.build(in); // 首先获取到根元素。 Element rootElement = document.getRootElement(); // persons元素。 // 获取根元素中的子元素。 List<Element> personsElementList = rootElement.getChildren(); // persons元素下的子元素person。 System.out.println(personsElementList.size()); for (Element personElement : personsElementList) { // 针对personElement获取内部的属性。 List<Attribute> attrsList = personElement.getAttributes(); for (Attribute attr : attrsList) { String attrName = attr.getName(); String attrValue = attr.getValue(); System.out.println(attrName + "=" + attrValue); } // 再解决personElement下的所有的子元素的内容。 List<Element> childsElementList = personElement.getChildren(); for (Element childElement : childsElementList) { String tagName = childElement.getName(); String tagValue = childElement.getValue(); System.out.println(tagName + "-----" + tagValue); } } } catch (Exception e) { e.printStackTrace(); } }}3.4 sax的基本使用
package com.xml.sax;import java.io.InputStream;import javax.xml.parsers.SAXParser;import javax.xml.parsers.SAXParserFactory;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;public class SaxTest { public static void main(String[] args) { try { // 创建一个Sax解析器的工厂。 SAXParserFactory factory = SAXParserFactory.newInstance(); // 通过工厂产生一个Sax解析器对象。 SAXParser saxParser = factory.newSAXParser(); // 指定xml文件,并获取相应的流。 InputStream inputStream = Thread.currentThread().getContextClassLoader().getResourceAsStream("persons.xml"); // 创建一个DefaultHandler对象。 MyHandler dh = new MyHandler(); // 执行解析。 saxParser.parse(inputStream, dh); // 在加载xml文件的过程中,dh对象中的那些事件方法都会一一的被触发。 } catch (Exception e) { e.printStackTrace(); } }}// 自定义一个类,继承DefaultHandler类。重写其中的5个方法。class MyHandler extends DefaultHandler { @Override public void startDocument() throws SAXException { super.startDocument(); System.out.println("----xml文档的开始-----"); } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { if ("person".equals(qName)) { // 取出person元素中的属性的值。--------使用attributes对象处理当前这个元素中的属性。 int len = attributes.getLength(); for (int i = 0; i < len; i++) { String attName = attributes.getQName(i); String attValue = attributes.getValue(i); System.out.println(attName + "=" + attValue); } } } @Override public void characters(char[] ch, int start, int length) throws SAXException { // 获取元素中所包含的内容信息。 String content = new String(ch, start, length); System.out.println(content.trim()); } @Override public void endElement(String uri, String localName, String qName) throws SAXException { System.out.println("----xml中任意的一个元素的结束-----"); } @Override public void endDocument() throws SAXException { super.endDocument(); System.out.println("----xml文档的结束-----"); }}