目录
1.集合类 set
0.引入
1.set 介绍
1. 构造
2.Insert 插入
3.find 查找
4.count 判断是否在
5.erase 删除
6.lower_bound 和 upper_bound 区间查找
拓展:lower_bound 函数底层实现
equal_range 值区间
2.multiset 类
0.引入:不去重的 set
1.增删查改
1.集合类 set
0.引入
首先要知道的是序列式容器,这种容器我们之前接触过,比如vector,list,deque等等。
序列式容器:
底层为线性的数据结果(物理上或者逻辑上),容器中的元素储存的是元素本身。
而且我们之前在使用序列式容器的时候,插入数据和删除数据只管操作就行,不用考虑其他因素。
关联式容器:
存储的是<key,value>结构的键对值,在数据检索时比序列式容器效率更高。
插入和删除数据时,要考虑该数据和它前后数据之间的关联性。
总的来说,关联式容器存放的数据不同,而且数据前后有一点的关联性。
1.set 介绍
通过插入新的元素来扩展容器,有效地通过插入的元素数量增加容器的大小。
因为集合中的元素是唯一的,插入操作检查每个插入的元素是否等同于已经在容器中的元素。
如果是,则不插入该元素,返回一个到这个现有元素的迭代器(如果该函数返回一个值)。

头文件:#include <set>
set和之前学习的容器一样,也是一个模板类,但是它的底层是关联式容器,也就是二叉搜索树,并且有很多的成员函数
1. 构造

构造函数有三个,分别是默认构造函数、使用迭代器区间的构造函数、拷贝构造函数。
因为底层是二叉搜索树,所有就会涉及到比较,构造函数参数就是比较方式,是一个仿函数,但是默认情况下是有缺省值的。
#include<iostream>#include<set>using namespace std;int main(){int arr[] = { 9,5,1,4,7,6,2,3,5,5,5,5,5 };set<int> s2(arr, arr + sizeof(arr) / sizeof(arr[0]));//迭代器区间构造for (auto& e : s2)//取别名{cout << e << " ";}cout << endl;return 0;}

迭代器区间构造s2的时候,会发现其有 排序+去重
数组中有多个重复数字,用这些数字构造出来的set,里面每个数字只存在一个,重复的都被去除了。(如果想知道去重次数 map)迭代器的中序移动:在打印set中的数据时,我们发现打印出来的结果是升序的,在学习二叉搜索树的时候我们知道,采用中序遍历的方式打印出来的结果就是升序的。接下来让我们来学习一下 set 的各种接口
2.Insert 插入
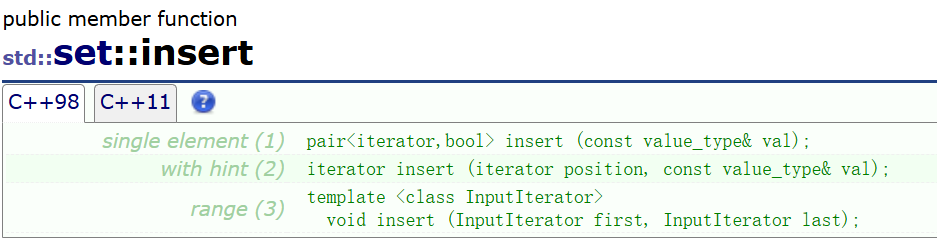
下面我们来简单来一下 ??? 的插入,调用的 insert 接口:
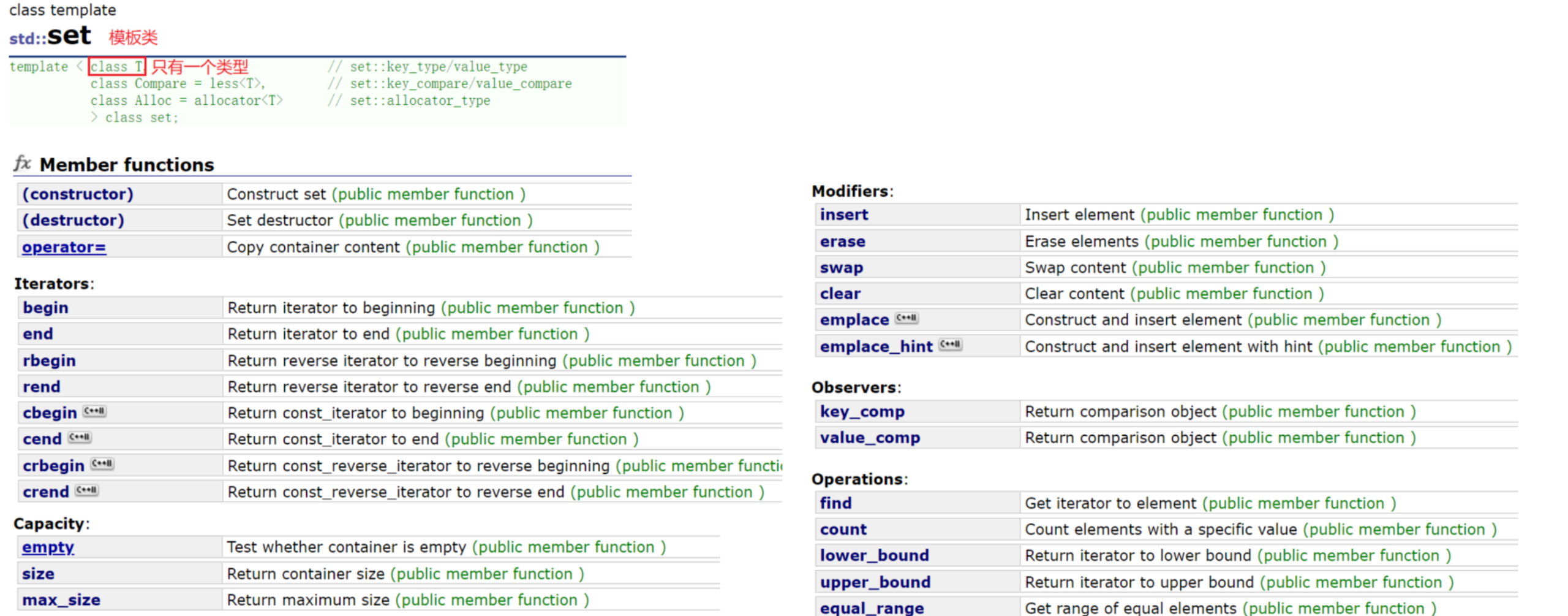
pair<iterator,bool> insert (const value_type& val);iterator insert (iterator position, const value_type& val); template <class InputIterator> void insert (InputIterator first, InputIterator last);测试:
void test_set1() { set<int> s; s.insert(4); s.insert(5); s.insert(2); s.insert(1); s.insert(3); s.insert(3); // 排序 + 去重 set<int>::iterator it = s.begin(); while (it != s.end()) { cout << *it << " "; ++it; } cout << endl;} int main(void){ test_set1(); return 0;}
再次验证了 ??? 是 "排序 + 去重" 的!
3.find 查找
下面再介绍一下 find 接口,如果这个元素被找到就会返回 val 的迭代器,否则返回 end。

set<int>::iterator pos = s.find(2);//要用迭代器接收
void test_set2() { set<int> s; s.insert(4); s.insert(5); s.insert(2); s.insert(1); s.insert(3); s.insert(3); set<int>::iterator pos = s.find(2);//要用迭代器接收 if (pos != s.end()) { cout << "找到了" << endl; }}
我们现在用下算法中的 find 接口,看看和 ??? 中的 find 的写法有什么区别?哪个更好:
pos = find(s.begin(), s.end(), 2);if (pos != s.end()) { cout << "找到了" << endl;}algorithm 中的 find 是暴力查找的方式实现的,从 begin 查到 end,其时间复杂度为 O(n),set 的时间复杂度是 o(log N)
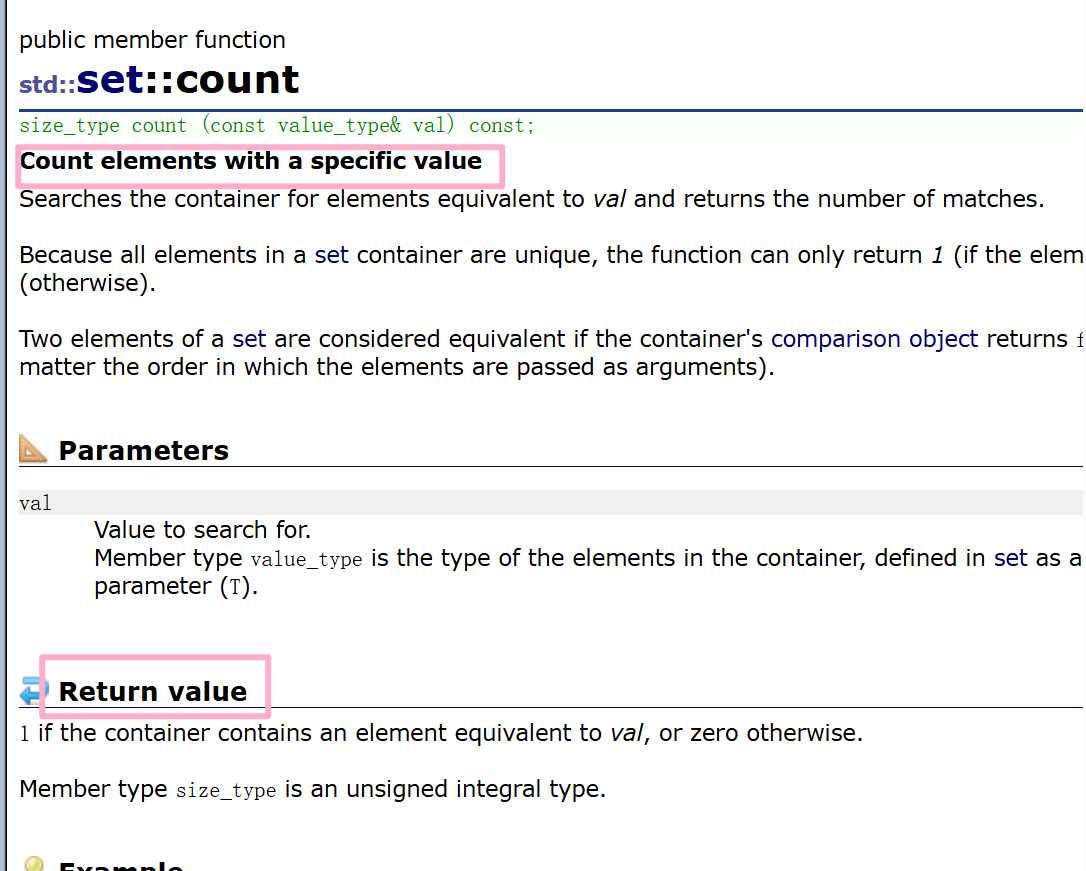
4.count 判断是否在
介绍一下 count 接口,有时我们需要判断元素在不在集合中,使用 count 往往比使用 find 方便。
count 非常的简单粗暴,如果在集合中则返回1,不在则返回 0。
测试:
void test_set3() { set<int> s; s.insert(4); s.insert(5); s.insert(2); s.insert(1); s.insert(3); s.insert(3); if (s.count(3)) { cout << "3在" << endl; }}
这里如果用 find 就没这么方便了,你还需要做一个判断:
if (s.find(3) != s.end()) { cout << "3在" << endl;}5.erase 删除
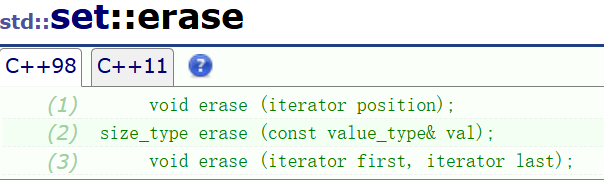
有三个重载函数,第一个删除指定迭代器的值,第二个返回删除指定值的个数,第三个删除迭代器区间中所有数据。
利用 find 返回迭代器测试第一种:

第二种--直接删除:

思考:那迭代器的方式删除和直接删除有什么区别呢?
? 解答:迭代器 find + erase(pos) 的是找到了再删,我们一般和 find 搭配使用,因为如果这个元素不存在我们还强硬调用 erase 删除就会引发报错。而 erase(x) 就比较好了,直接删不存在不会报错。
6.lower_bound 和 upper_bound 区间查找
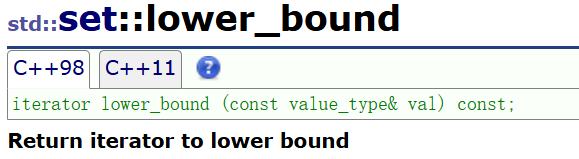
lower_bound() 用于在指定区域内查找 >= 目标值的第一个元素。
return 一个指向集合中第一个大于等于给定值的元素的迭代器,如果找不到,则返回 end。
即获取集合中任意元素的下界:
[x,+∞)
测试:

对返回的迭代器,解引用打印
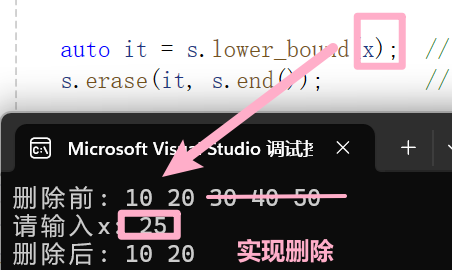
如果我们需要删除大于等于 x 的所有元素,我们就可以用到这个接口了。
所以说返回迭代器 都是有妙用的~

还有一个 upper_bound 接口,在指定范围内查找大于目标值的第一个元素,不包含等于。
(x,+∞)
这两个接口就是为了迎合迭代器 erase 的 "左闭右开" 而配备的,因为要是右开,所以是大于的第一个数,没带等号了
? 代码演示:删除区间 [x,y]
#include <iostream>#include <set>using namespace std;int main(void){set<int> myset;set<int>::iterator itlow, itup;//auto的快乐就体现啦for (int i = 1; i < 10; i++)myset.insert(i * 10); // 10 20 30 40 50 60 70 80 90 myset.insert(35);for (auto e : myset) {cout << e << " ";} cout << endl; //删除[30 60]itlow = myset.lower_bound(30); // >= 30itup = myset.upper_bound(60); // > 70myset.erase(itlow,itup);cout << "删除后: ";for (auto e : myset) {cout << e << " ";} cout << endl;return 0;}

拓展:lower_bound 函数底层实现
这个模板函数 lower_bound 在一个有序区间 [first, last) 中查找第一个不小于给定值 val 的位置。它是一个通用的二分查找算法,适用于任何支持随机访问迭代器的容器,如 vector, deque, array 等。
template <class ForwardIterator, class T>ForwardIterator lower_bound ( ForwardIterator first, ForwardIterator last, const T& val ){ ForwardIterator it; iterator_traits<ForwardIterator>::difference_type count, step; count = distance(first,last); while (count>0) { it = first; step=count/2; advance (it,step); if (*it<val) { first=++it; count-=step+1; } else count=step; } return first;}代码分解
template <class ForwardIterator, class T>ForwardIterator lower_bound ( ForwardIterator first, ForwardIterator last, const T& val)模板参数
ForwardIterator:一种迭代器类型,必须支持前向迭代(ForwardIterator)。
T:要查找的值的类型。
参数
first:指向序列起始位置的迭代器。
last:指向序列结束位置的迭代器(不包含在范围内)。
val:要查找的值。
函数体
ForwardIterator it;iterator_traits<ForwardIterator>::difference_type count, step;count = distance(first, last);it:一个中间迭代器,用于在查找过程中指向当前检查的元素。
count:序列中元素的数量,由 distance 函数计算得到。
step:步长,用于二分查找过程中每次查找的中间位置。
while (count > 0){ it = first; step = count / 2; advance(it, step); if (*it < val) { first = ++it; count -= step + 1; } else count = step;}这个 while 循环实现了二分查找:
初始化中间迭代器和步长:
it = first:将中间迭代器 it 初始化为 first。step = count / 2:步长为当前范围的一半。advance(it, step):将 it 向前移动 step 步。 比较中间值与目标值:
if (*it < val):如果中间值小于目标值 val,则说明目标值在 it 的右侧。 first = ++it:将 first 移动到 it 的下一个位置。count -= step + 1:更新剩余元素的数量。else:否则目标值在 it 的左侧或正好是 it。 count = step:更新剩余元素的数量。 这个过程会不断缩小查找范围,直到找到第一个不小于 val 的位置或者范围为空。
返回值
return first;最终返回 first,它指向第一个不小于 val 的位置,如果所有元素都小于 val,则返回 last。
总结
lower_bound 函数利用二分查找法在有序序列中找到第一个不小于给定值 val 的位置。通过逐步缩小查找范围,这种方法可以在对数时间复杂度 O(log n) 内完成查找,是一种高效的算法。
equal_range 值区间
equal_range 是 C++ 标准库中的一个函数模板,主要用于在有序容器(如 set, map, vector 等)中查找一个值的范围。它返回一对迭代器,表示要查找值在容器中第一次出现的位置和最后一次出现的位置。
template <class ForwardIterator, class T>std::pair<ForwardIterator, ForwardIterator>equal_range(ForwardIterator first, ForwardIterator last, const T& val);first:指向容器起始位置的迭代器。last:指向容器结束位置的迭代器。val:要查找的值。 返回值:
std::pair<ForwardIterator, ForwardIterator>:包含两个迭代器,第一个迭代器指向第一个不小于 val 的位置,第二个迭代器指向第一个大于 val 的位置。 完善的代码
下面是使用 std::set 进行 equal_range 操作的示例代码,包括对 equal_range 返回值的解释和结果的输出。
#include <iostream>#include <set>int main() { std::set<int> myset = { 10, 20, 30, 40, 50 }; // 使用 equal_range 查找 30 的范围 auto ret = myset.equal_range(30); std::set<int>::const_iterator itlow = ret.first; // 第一个不小于 30 的位置 std::set<int>::const_iterator itup = ret.second; // 第一个大于 30 的位置 // 输出区间 [itlow, itup) std::cout << "Range: "; for (auto it = itlow; it != itup; ++it) { std::cout << *it << " "; } std::cout << std::endl; return 0;}测试和结果
运行上述代码后,你会得到如下输出:
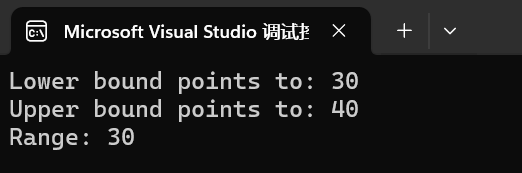
这表明在集合 myset 中,值为 30 的元素的范围起始于第一个不小于 30 的位置(即 30 本身),结束于第一个大于 30 的位置(即 40)。因此,区间 [itlow, itup) 只包含 30。

2.multiset 类
0.引入:不去重的 set
std::set
std::set存储的是不重复的元素,每个元素的键值必须是唯一的。插入重复的元素时,std::set只保留一个副本。元素根据其键值排序,通常使用红黑树作为底层数据结构实现,这意味着查找、插入和删除的时间复杂度通常是O(log n)。 std::multiset
std::multiset与std::set类似,但它允许存储重复的元素,也就是说,相同的键值可以出现多次。插入重复的元素时,std::multiset会保留所有副本。和std::set一样,std::multiset也保持元素排序,且具有相同的底层数据结构和时间复杂度特征 1.增删查改

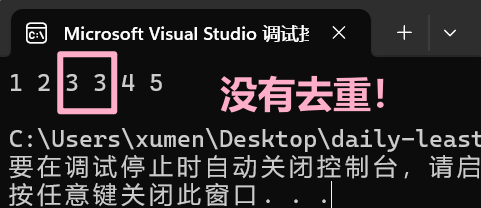
insert 插入:
#include <iostream>#include <set>using namespace std; void test() { multiset<int> s; s.insert(4); s.insert(5); s.insert(2); s.insert(1); s.insert(3); s.insert(3); // 支持范围 for for (auto e : s) { cout << e << " "; } cout << endl;}
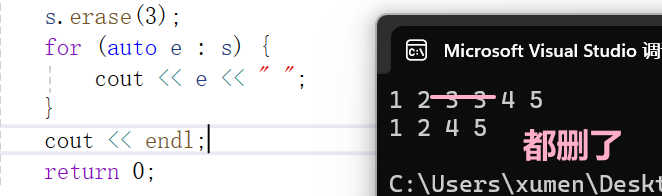
erase 删除:
multiset 的 erase 接口会把所有指定元素删掉:
find 查找:
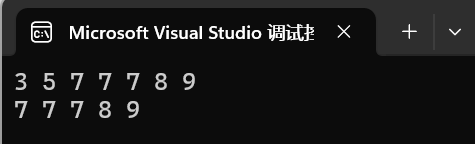
multiset 的 find 如果要查找的元素在集合中有多个,会返回中序的第一个,假设我们要 find(3):
#include <iostream>#include <set>using namespace std;int main() {multiset<int> s;s.insert(3);s.insert(5);s.insert(8);s.insert(7);s.insert(7);s.insert(9);s.insert(7);for (auto e : s){cout << e << " ";}cout << endl;// 返回中序第一个7auto pos = s.find(7);while (pos != s.end()){//*pos = 10;cout << *pos << " ";++pos;}cout << endl;return 0;}
set和multiset都有这三个接口,以前我们也没学过,这里说一下,但是用的很少。

根据下面一段来说一说
int main(){ std::multiset<int> mymultiset; std::multiset<int>::iterator itlow, itup; for (int i = 1; i < 8; i++) mymultiset.insert(i * 10); // 10 20 30 40 50 60 70 itlow = mymultiset.lower_bound(30); itup = mymultiset.upper_bound(40); mymultiset.erase(itlow, itup); // 10 20 50 60 70 std::cout << "mymultiset contains:"; for (std::multiset<int>::iterator it = mymultiset.begin(); it != mymultiset.end(); ++it) std::cout << ' ' << *it; std::cout << '\n'; return 0;}
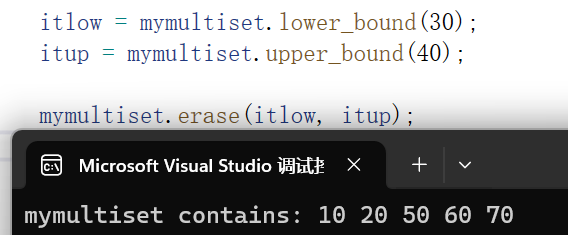
上面就是删掉一段区间。
lower_bound(30);返回大于等于这个值的边界
upper_bound(40);返回大于这个值的边界
所以说这两个接口是为了方便或者左闭右开的区间的。
equal_range(30);是获得这个值的边界。
map 下节预告~
set 都是 const 迭代器不允许被修改,map 可以

