C++中的map是一个关联容器,它存储键值对,其中每个键唯一,并且每个键映射到一个值。map通过键自动排序,并提供快速检索能力。它主要用于快速查找、插入和删除键值对。
如何定义map
// 一般定义 键的类型为string,值的类型为int,排序方式为值升序排序 map<string, int> map1;// 使用自定义比较函数对象作为第三个参数,这个之后会详细说明 map<string, int, CustomCompare> map1;插入值,两种方法
//第一种:用insert函数插入pair数据:map<int,string> map1;map1.insert(pair<int,string>(1,"first"));map1.insert(pair<int,string>(2,"second"));//第二种:用insert函数插入value_type数据:map<int,string> map1;map1.insert(map<int,string>::value_type(1,"first"));map1.insert(map<int,string>::value_type(2,"second")); //第三种:用数组的方式直接赋值:map<int,string> map1;map1[1]="first";map1[2]="second";遍历输出map中的值,也有两种方法
这里我们先介绍迭代器的定义
map<int,string>::iterator it;//这句话定义了一个名为`it`的迭代器//用于遍历或访问`std::map<int, string>`类型的元素。//迭代器`it`可以用来指向`map`中的任何一个键值对,并通过它可以访问键值对的键和值。然后适用于迭代器的遍历
for(it=map1.begin();it!=map1.end();it++) cout<<it->first<<it->second<<endl;//it->first 一组map的键//it->second是一组map的值//也可以有以下定义法auto it = map1.find(2);区别
区别: map<int, string>::iterator it; 仅仅声明了一个类型为std::map<int, string>::iterator 的变量it,但没有初始化。it可以用来遍历map或指向map中的特定元素,但在使用之前需要被赋值或初始化。auto it = ma.find(2); 不仅声明了迭代器it,还通过ma.find(2)初始化了它。这里的auto关键字使得编译器自动推断it的类型,避免了手动书写长类型名。这种方式更为简洁且能直接使用it进行后续操作。对于
for(it=map1.begin();it!=map1.end();it++)中的it++
在C++中,尽管map的内部结构是基于红黑树实现的,但它提供了迭代器(Iterator)机制来遍历容器。迭代器是一种抽象的指针,支持++操作符来移动到容器的下一个元素。因此,即使map的物理存储不是连续的,通过迭代器的抽象,我们可以像操作指针一样,使用++来遍历map中的所有元素,而不需要关心其内部是如何组织的。这就是为什么可以使用for(i = mymap.begin(); i != mymap.end(); i++)这种方式遍历`map`的原因。也有一种更方便的方法
for (const auto& pair : map1) { cout << pair.first << " " << pair.second << endl; }for ( auto pair : map1) { cout << pair.first << " " << pair.second << endl; }/*两个循环遍历`map`并打印每个键值对的结果是一样的,但它们在处理元素时的效率和内存使用上有所不同:1. `for (const auto& pair : ma)`: 在这个循环中,`pair`是对`map`中元素的引用,并且因为它是`const`的,所以不能通过`pair`修改元素的值。使用引用避免了不必要的复制,使得这种方式更加高效和节省内存。2. `for (auto pair : ma)`: 在这个循环中,`map`中的每个元素都会被复制到`pair`中。这意味着对于大型对象或结构体,这种方式会消耗更多的内存和时间,因为它涉及到复制操作。总结:虽然最终结果一样,但第一个方式(使用`const auto&`)更优,因为它避免了不必要的复制,提高了效率。*/一些其他的操作
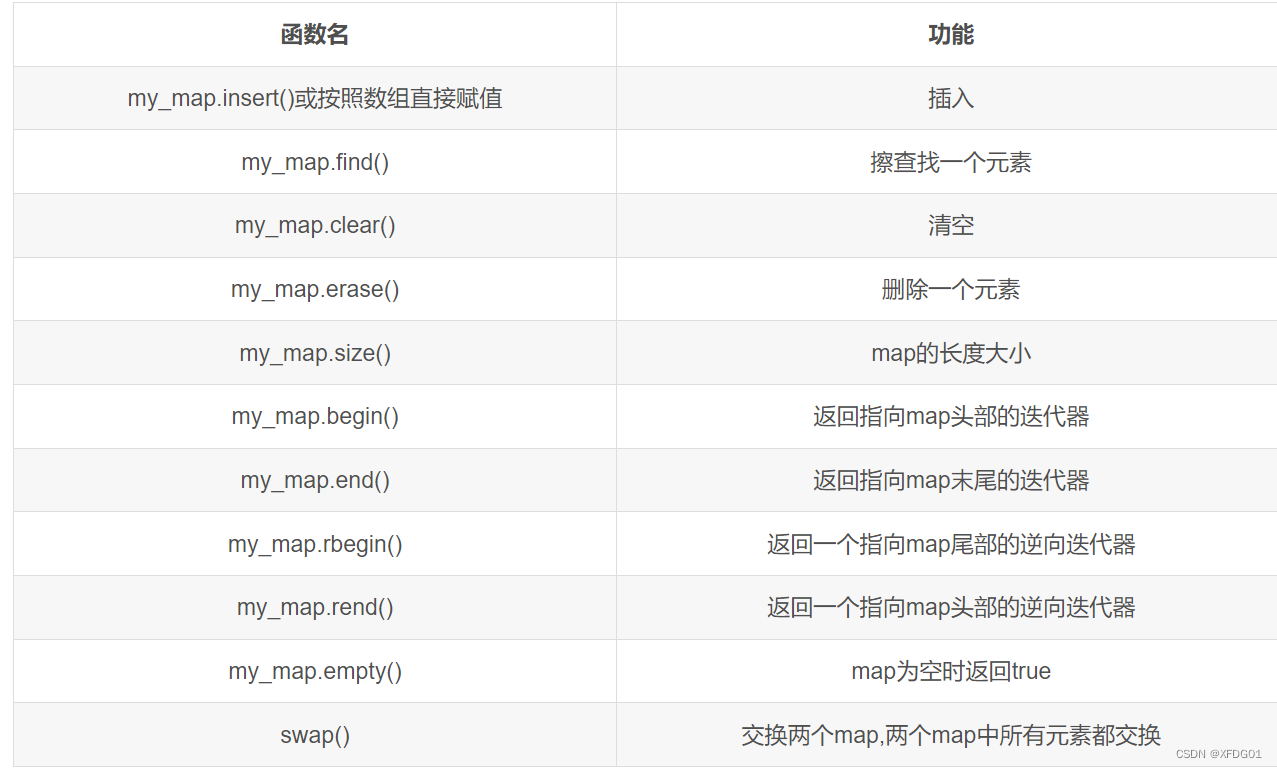
下面讲讲 .find() 和.count()函数
查找数据有两种办法,一个使用find函数还有一个是用count函数(当然了,你查找数据,很明显要查找的肯定是键吧,没有查找值的吧,哈哈哈)(1)find函数find函数查找成功会返回指向它的迭代器,没有找到的话,返回的是end这个迭代器 - 使用`find()`时,如果找到了键,你可以直接访问该键对应的值。`find()`更适合在找到键时需要对值进行操作的场景。(2)count函数count函数的意思就是查找这个键的出现次数,map中键是唯一的,所以它的值要么是0要么是1,是1不就是查找成功吗,不过它的缺点也可以知道,它可以确定是否存在这个键,可是却不能确定这个键的位置- 使用`count()`可以快速检查键是否存在,但它不提供对找到的元素的直接访问。`count()`适用于仅需要检查键存在性的场景。//使用find来找到指定map元素#include <iostream>#include <map>using namespace std;int main() { map<int, string> ma = {{1, "one"}, {2, "two"}, {3, "three"}}; auto it = ma.find(2); if (it != ma.end()) { cout << "Found: " << it->first << " => " << it->second << endl; } else { cout << "Key not found." << endl; } return 0;}//使用count来找到特定的元素#include <iostream>#include <map>using namespace std;int main() { map<int, string> ma = {{1, "one"}, {2, "two"}, {3, "three"}}; if (ma.count(2) > 0) { cout << "Key found." << endl; } else { cout << "Key not found." << endl; } return 0;}总结
- 使用`find()`时,如果找到了键,你可以直接访问该键对应的值。`find()`更适合在找到键时需要对值进行操作的场景。- 使用`count()`可以快速检查键是否存在,但它不提供对找到的元素的直接访问。`count()`适用于仅需要检查键存在性的场景。map元素的删除
//erase里的参数可以直接写键,也可以写迭代器。 map<int, string>::iterator it; it = map1.find(1); map1.erase(it); //如果要删除1,用关键字删除 int n = map1.erase(1); //如果删除了会返回1,否则返回0 //用迭代器,成片的删除,一下代码把整个map清空 map1.erase( map1.begin(), map1.end() ); //成片删除要注意的是,也是STL的特性,删除区间是一个前闭后开的集合map元素的排序
方法一:
map中元素是自动按key升序排序(从小到大)的;按照value排序时,想直接使用sort函数是做不到的sort函数只支持数组、vector、list、queue等的排序,无法对map排序那么就需要把map放在vector中,再对vector进行排序。#include <iostream>#include <string>#include <map>#include <algorithm>#include <vector>using namespace std; bool cmp(pair<string,int> a, pair<string,int> b) {return a.first> b.first;} int main(){ map<string, int> map1; map1["Alice"] = 86; map1["Bob"] = 78; map1["Zip"] = 92; map1["Stdevn"] = 88; vector< pair<string,int> > vec(map1.begin(),map1.end()); //或者: //vector< pair<string,int> > vec; //for(map<string,int>::iterator it = map1.begin(); it != map1.end(); it++) // vec.push_back( pair<string,int>(it->first,it->second) ); sort(vec.begin(),vec.end(),cmp); for (vector< pair<string,int> >::iterator it = vec.begin(); it != vec.end(); ++it) { cout << it->first << " " << it->second << endl; } return 0;}方法二:
#include <iostream>#include <map>#include <string>using namespace std;// 自定义比较函数对象struct CustomCompare { bool operator()(const int& a, const int& b) const { return a > b; // 定义值(int类型)的降序排序规则 }};int main() { // 使用自定义比较函数对象作为第三个参数 map<string, int, CustomCompare> map1; map1["Alice"] = 86; map1["Bob"] = 78; map1["Zip"] = 92; map1["Steven"] = 88; // 遍历map,它会按照自定义的降序规则进行排序 for (const auto& pair : map1) { cout << pair.first << " " << pair.second << endl; } return 0;}对于自定义比较函数
struct CustomCompare { bool operator()(const int& a, const int& b) const { return a > b; // 定义值(int类型)的降序排序规则 }};有以下解释
这段代码定义了一个重载的`operator()`函数,它是`CustomCompare`结构体的成员函数。这个函数是一个比较函数对象(也称为仿函数),用于定义两个`string`对象`a`和`b`之间的排序规则。在这个特定的例子中,它被用来定义一个降序排序规则。函数解释- `bool`:这是函数的返回类型,表示函数返回一个布尔值。`true`表示第一个参数应该排在第二个参数之前,`false`则相反。- `operator()`:这是所谓的函数调用运算符的重载。当你创建了`CustomCompare`的一个实例并像函数一样调用它时,这个重载的运算符就会被调用。例如,如果你有`CustomCompare comp;`,那么`comp(a, b)`会调用这个重载的`operator()`。- `const string& a, const string& b`:这是函数的参数,它们是对`string`对象的常量引用,这意味着函数不会修改这些字符串,并且使用引用可以避免不必要的拷贝,提高效率。- `const`:这个关键字在函数声明的最后表示这个函数不会修改它所属的对象的任何成员变量。这是因为在比较操作中通常不需要也不应该修改比较的对象。操作逻辑`return a > b;`:这行代码是函数的核心,它定义了比较的逻辑。在这里,它检查`a`是否大于`b`。如果是,函数返回`true`,表示在排序顺序中`a`应该排在`b`之前。这是一种降序排序规则,因为在常规的升序排序中,如果`a`小于`b`,我们会期望返回`true`。通过这种方式,`CustomCompare`定义了一种特定的排序准则,即在任何使用到它的排序操作中,字符串会按照值的逆序排列。使用场景当你将`CustomCompare`作为`std::map`的第三个模板参数时,`std::map`会使用这个比较函数对象来决定键的顺序。这意味着在这个`map`中,值会按照降序排列,而不是默认的升序排列。这对于需要特定排序规则的场景非常有用。
总结完毕