一、ollama如何保持模型加载在内存中或立即卸载?
默认情况下,模型在生成响应后会在内存中保留 5 分钟。这允许在您多次请求 LLM 时获得更快的响应时间。然而,您可能希望在 5 分钟内释放内存,或者希望模型无限期地保留在内存中。使用 keep_alive 参数与 /api/generate 或 /api/chat API 端点,可以控制模型在内存中保留的时间。
keep_alive 参数可以设置为:
例如,要预加载模型并使其保留在内存中,请使用:
curl http://localhost:11434/api/generate -d '{"model": "llama3", "keep_alive": -1}'要卸载模型并释放内存,请使用:
curl http://localhost:11434/api/generate -d '{"model": "llama3", "keep_alive": 0}'或者,可以通过在启动 Ollama 服务器时设置环境变量 OLLAMA_KEEP_ALIVE 来更改所有模型在内存中保留的时间。OLLAMA_KEEP_ALIVE 变量使用与上述 keep_alive 参数相同的参数类型。
如果希望覆盖 OLLAMA_KEEP_ALIVE 设置,请使用 keep_alive API 参数与 /api/generate 或 /api/chat API 端点。
二、在启动时添加OLLAMA_KEEP_ALIVE环境参数
1. 停止ollama服务
docker stop ollama2.移除ollama服务
docker rm ollama3.加上参数进行启动
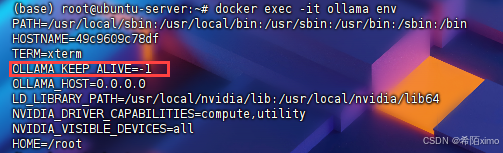
docker run -d --gpus=all -e OLLAMA_KEEP_ALIVE=-1 --restart=always -v /home/docker/ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama三、查看是否设置成功
docker exec -it ollama env