找往期文章包括但不限于本期文章中不懂的知识点:
个人主页:我要学编程(ಥ_ಥ)-CSDN博客
所属专栏:数据结构(Java版)
数据结构之八大排序(上)-CSDN博客
上面博客讲述了另外六中排序算法。
目录
快速排序
归并排序
快速排序
快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法,其基本思想为:任取待排序元素序列中的某元素作为基准值,按照该排序码将待排序集合分割成两子序列,左子序列中所有元素均小于基准值,右子序列中所有元素均大于基准值,然后最左右子序列重复该过程,直到所有元素都排列在相应位置上为止。
总共有三个实现版本:
1、Hoare法版:
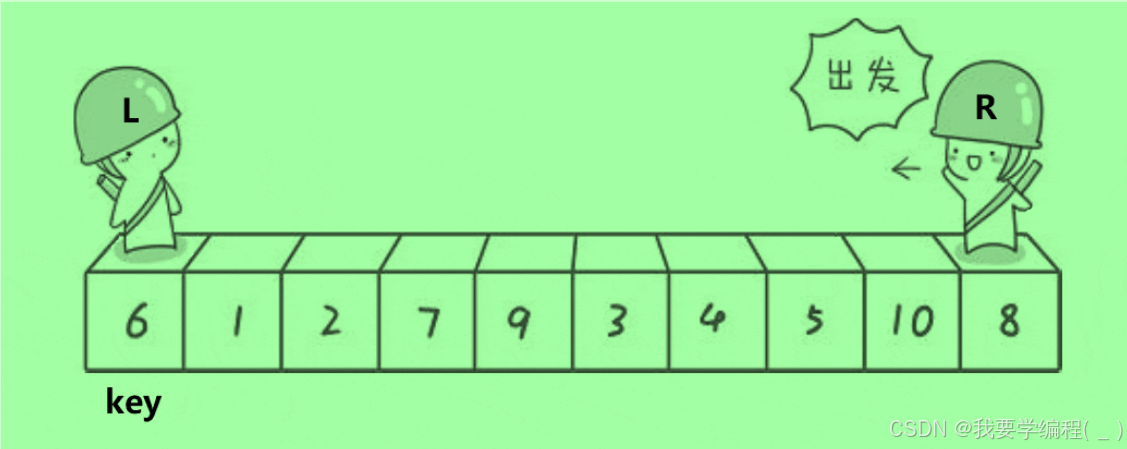
思路:取key作为基准,右边找比基准小的,左边找比基准大的,进行交换,一直重复上述步骤,直至两者相遇,相遇后再交换相遇值和基准值,接着就以相遇的值为界,划分为左右两边,继续重复上述步骤。
代码实现:
public static void quickSort(int[] array) { quick_sort(array, 0, array.length-1); } private static void quick_sort(int[] array, int start, int end) { // 限制条件 if (start >= end) { return; } // 分区并进行交换 int div = partion(array, start, end); // 递归左子树 quick_sort(array, start, div-1); // 递归右子树 quick_sort(array, div+1, end); } private static int partion(int[] array, int left, int right) { int key = array[left]; // 指定基准 int keyIndex = left; // 记录基准的下标,用于交换 while (left < right) { // 右边找到比基准小的 while (left < right && array[right] >= key) { right--; } // 左边找到比基准大的 while (left < right && array[left] <= key) { left++; } swap(array, left, right); } // 相遇后交换 swap(array, left, keyIndex); // 返回相遇点 return left; }注意:
1、限制条件。我们在递归的时候,如果只有一个元素时, 说明此时一定是有序的,就不需要再继续进行递归了。即 start == end。如果在递归过程中 start > end了说明也不需要交换了。
2、在左右找比基准大或者小时,一定要先找右边,再找左边。否则达不到我们的目的(左边全小于边界值,右边全大于边界值)。如下图所示:
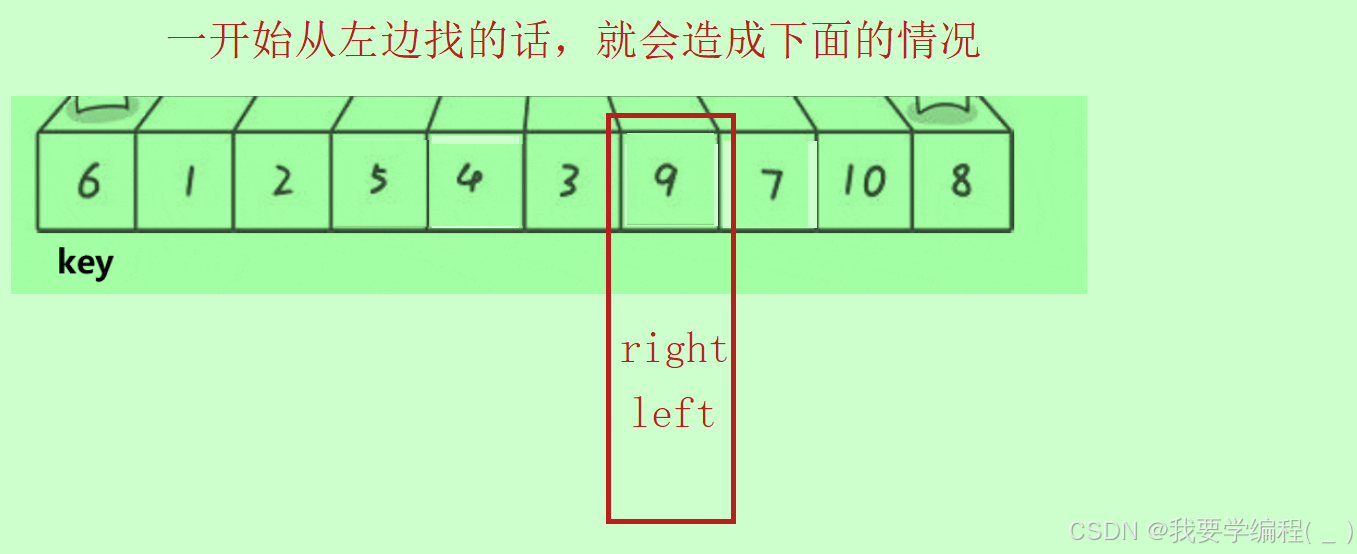
这样再去交换相遇值和基准值就不能实现相遇值(边界值)全大于其左边,小于其右边。
3、相遇交换基准值和相遇值时,一定要先把基准值对应的下标储存起来。
4、时间复杂度:最坏情况:O(N^2):当数据已经有序的情况下;最好情况:O(N*logN):数据刚好可以组成满二叉树,每次都是N个数据,递归了logN层,即N*logN。
5、空间复杂度:最坏情况:O(N):当数据已经有序的情况下;最好情况:O(logN):数据刚好可以组成满二叉树,递归了logN层。
6、稳定性:不稳定。

2、挖坑法版:
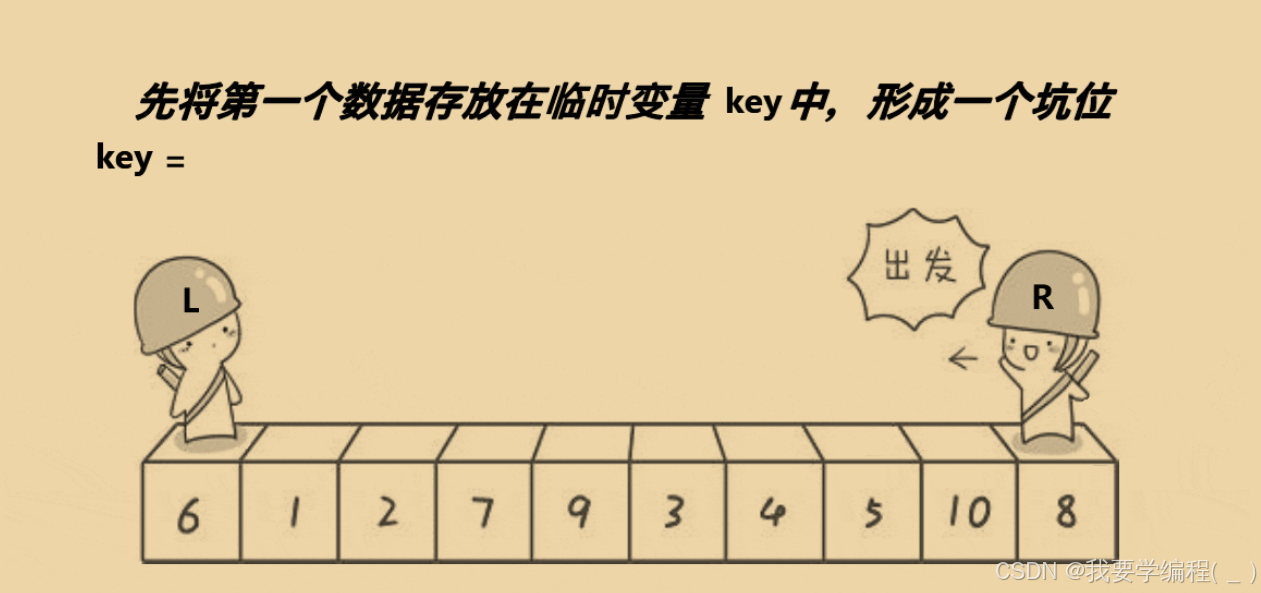
思路:同样是取左边的第一个数据为 key,形成一个坑位,在右边找到比key小的放到左边的坑位中(这就意味着右边形成了坑位),再从左边找到比 key 大的放到坑位中。一直重复上面的操作直至两者相遇,就把 key 放到坑位中,那么这个坑位(相遇点)就是划分标准,然后我们继续从两棵子树开始上述操作。
代码实现:
private static int partion(int[] array, int left, int right) { int key = array[left]; while (left < right) { // 右边找小于坑的值 while (left < right && array[right] >= key) { right--; } // 开始填坑 array[left] = array[right]; // 左边找大于坑的值 while (left < right && array[left] <= key) { left++; } // 继续填坑 array[right] = array[left]; } array[left] = key; return left; }注意:整体代码和上述代码一致,只是改变了partion的代码部分,也就是划分标准改变了。
3、前后指针法版:
思路:定义一个指针 prev 和一个指针 cur,分别指向 start 和 start+1 的位置,开始遍历数组,如果 cur指向的数据小于 left 指向的数据,并且prev指向的下一个数据不是 cur 指向的数据,那么就交换两者的值,并同时往后走;如果 cur指向的数据大于 left 指向的数据,就让 cur 继续往后走,直至cur 遇到end就停止。并交换prev和left的值。
代码实现:
private static int partion(int[] array, int left, int right) { int prev = left; int cur = prev+1; while (cur <= right) { if (array[cur] < array[left] && array[++prev] != array[cur]) { swap(array, prev, cur); } cur++; } swap(array, left, prev); return prev; }上面遇到了是单分支的树的情况,就导致快速排序变得类似冒泡排序一样了。针对上述情况,我们就要来优化代码。
思路一:既然我们拿到的数组是单分支的情况,那么我们只要把这棵树的中间节点(就是类似这组数据的中位数)的给找出来,然后再交换0位置的值即可,这就铸造了最开始的情况(图中数据所示)。
找根节点这里用到的是:三数取中法。即得到 left 、left+right 和 right 的中位数。
代码实现:
// 三数取中法找到key,使单分支的树接近满二叉树 private static int getIndex(int[] array, int left, int right) { int mid = (left+right) / 2; if (array[left] < array[right]) { if (array[mid] < array[left]) { return left; } else if (array[mid] > array[right]){ return right; } else { return mid; } } else { if (array[mid] < array[right]) { return right; } else if (array[mid] > array[left]) { return left; } else { return mid; } } }注意:这里得到的只是一个近似值,不一定是准确的中位数。
思路二:二叉树的节点主要是集中在接近叶子结点的层数。既然如此,那直接把接近叶子节点的层树的节点全部采用直接插入排序即可。
直接插入排序部分的代码实现:
private static void insertSortRange(int[] array, int start, int end) { for (int i = start+1; i <= end; i++) { int tmp = array[i]; int j = i-1; while (j >= 0) { if (array[j] > tmp) { array[j+1] = array[j]; j--; } else { break; } } array[j+1] = tmp; } }核心代码部分:
// 递归到接近叶子结点时,采用直接插入排序更有效if (end - start <= 7) { //这个数是随机取的,只要是接近叶子节点层树即可 insertSortRange(array, start, end); return;}前面都是递归实现的代码,下面我们就来学习使用迭代的方式实现快速排序:
private static void quickSortNor(int[] array, int start, int end) { Stack<Integer> stack = new Stack<>(); stack.push(start); stack.push(end); while (!stack.isEmpty()) { end = stack.pop(); start = stack.pop(); int div = partion(array, start, end); // 判断是否区间中是否只剩下一个元素 if (div > start+1) { stack.push(start); stack.push(div-1); } if (div < end-1) { stack.push(div+1); stack.push(end); } } }其实非递归也就是大体结构发生了变化,在核心代码部分还是并未发生变化(交换数据)。
总结:虽然快速排序在不优化的情况下,时间复杂度确实能够达到O(N^2),但是我们平时都是说优化情况下的时间复杂度,即O(N*logN)。
归并排序
归并排序 是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。归并排序核心步骤: 第一步分解数据,第二步分组进行合并。
思路:先将一组数据进行分解,分解成只有一组数据的时候,就可以开始合并了。
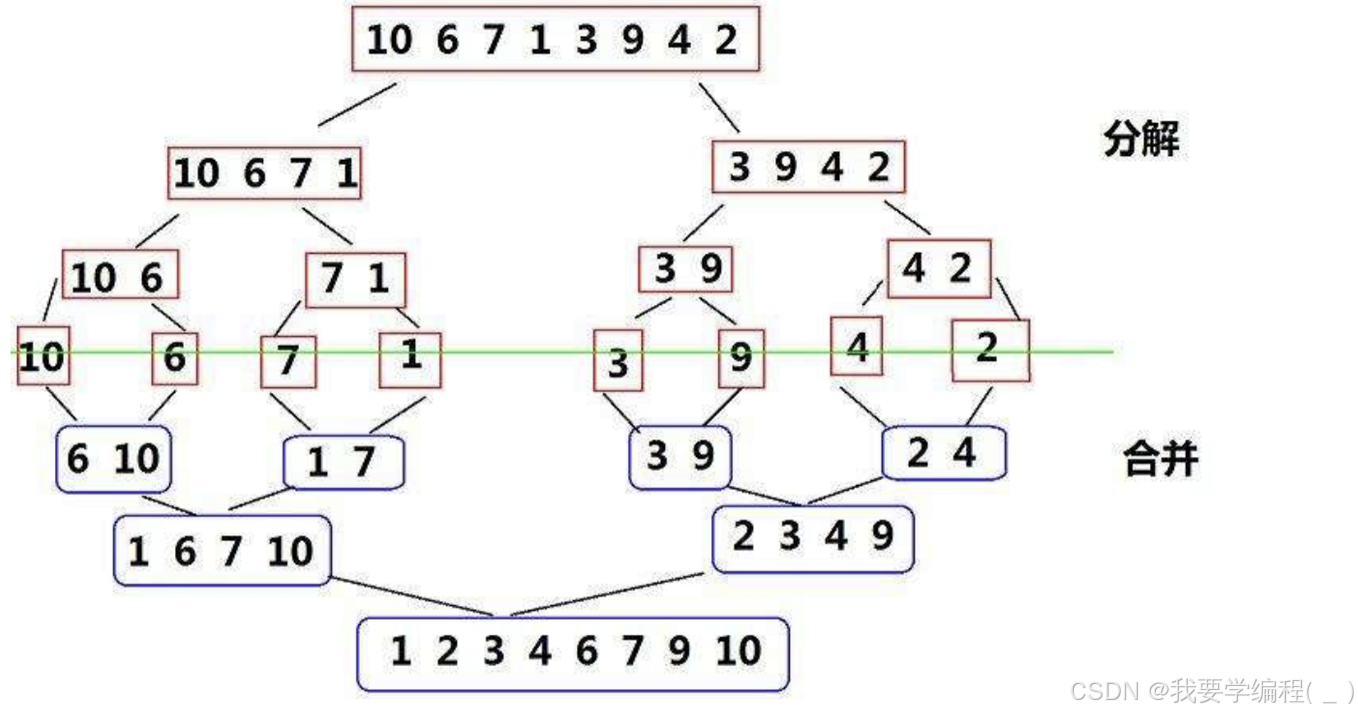
分解代码实现:
public static void mergeSort(int[] array) { merge_sort(array, 0, array.length-1); } private static void merge_sort(int[] array, int start, int end) { // 限制条件 if (start >= end) { return; } int mid = (start+end)/2; // 分解 merge_sort(array, start, mid); // 左子树 merge_sort(array, mid+1, end); // 右子树 // 合并(类似合并两个有序数组) merge(array, start, mid, end); }合并的思路:类似合并两个数组。
代码实现:
private static void merge(int[] array, int start, int mid, int end) { int s1 = start; int e1 = mid; int s2 = mid+1; int e2 = end; // 申请一个新的数组来排序数据 int[] tmp = new int[end-start+1]; int k = 0; while (s1 <= e1 && s2 <= e2) { if (array[s1] < array[s2]) { tmp[k++] = array[s1++]; } else { tmp[k++] = array[s2++]; } } // 把剩下的数据全部放到数组中 while (s1 <= e1) { tmp[k++] = array[s1++]; } while (s2 <= e2) { tmp[k++] = array[s2++]; } // 把排好序的数组数据存放到原数组中 for (int i = start; i < start+k; i++) { array[i] = tmp[i-start]; } /*// 或者写成下面这样 for (int i = 0; i < k; i++) { array[i+start] = tmp[i]; }*/ }注意:
1、时间复杂度:O(N*logN):每次进行分解的数据都是N个,总共会递归logN次,即N*logN。
2、空间复杂度:O(N):最后在合并的时候,会申请一个大小为N的数组,即N。
3、稳定性:稳定。既可以实现为稳定的排序,也可以实现为不稳定的排序。
同样归并排序也有非递归的实现方式。
思路:类似希尔排序的逆过程。就是把数据一个一个分成一组,使其有序,再把数据两个两个分成一组使其有序。直至一组的个数等于数据长度时,这个数据就有序了。
代码实现:
public static void mergeSortNor(int[] array, int start, int end) { // 把数据每次分为两组,进行比较-排序 int gap = 1; while (gap < array.length) { // 每次排序两组有效数据(因此i每次要跳过两组) for (int i = 0; i < array.length; i+=gap*2) { int left = i; int mid = left+gap-1; int right = mid+gap; // 要确保,mid和right是有效的 if (mid >= array.length) { mid = array.length-1; } if (right >= array.length) { right = array.length-1; } merge(array, left, mid, right); } gap *= 2; } }由于归并排序需要O(N)的空间复杂度,因此其主要是解决外部排序的问题。
外部排序:排序过程需要在磁盘等外部存储进行的排序
前提:内存只有 1G,需要排序的数据有 100G
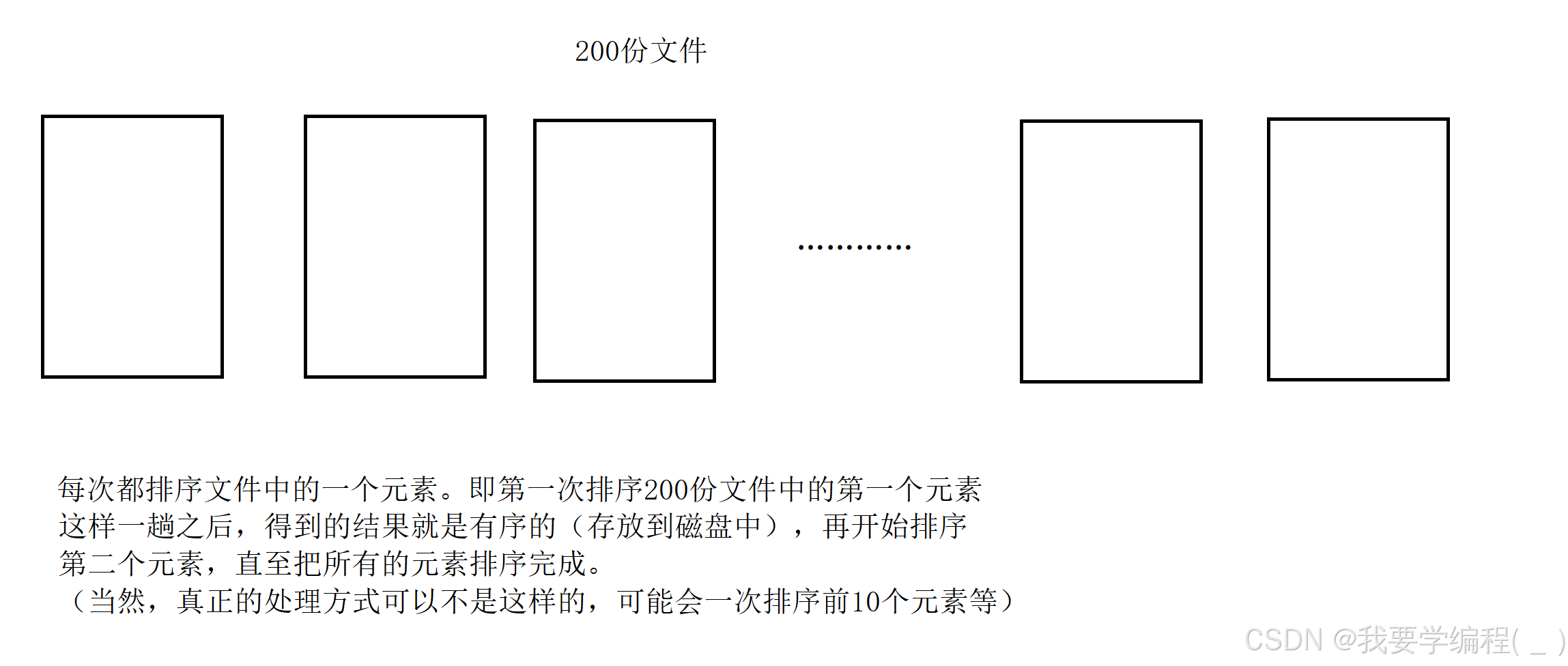
因为内存中因为无法把所有数据全部放下,所以需要外部排序,而归并排序是最常用的外部排序: 1. 先把文件切分成 200 份,每个 512 M
2. 分别对 512 M 排序,因为内存已经可以放的下,所以任意排序方式都可以
3. 进行 2路归并,同时对 200 份有序文件做归并过程,最终结果就有序了。
注意:归并是下面这样处理的。
计数排序
思想:计数排序又称为鸽巢原理,是对哈希直接定址法的变形应用。
操作步骤:
1.统计相同元素出现次数
2.根据统计的结果将序列回收到原来的序列中。
思路:先创建一个数组来记录元素出现的次数,再按照顺序去遍历这个新数组,把其中不为0的树记录到原来的数组中。
代码实现:
public static void countSort(int[] array) { // 先找到计数数组的长度范围 int[] ret = findVal(array); int[] count = new int[ret[0]-ret[1]+1]; // 遍历数组记录数值 for (int i = 0; i < array.length; i++) { // 遇到就++(小技巧:减去最小值) count[array[i]-ret[1]]++; } // 开始进行排序 int k = 0; for (int i = 0; i < count.length; i++) { while (count[i] > 0) { array[k++] = i+ret[1]; count[i]--; } } } // 找到数组的最值,即找到计数数组的长度 private static int[] findVal(int[] array) { int[] ret = new int[2]; int max = array[0]; int min = array[0]; for (int i = 1; i < array.length ; i++) { if (array[i] > max) { max = array[i]; } if (array[i] < min) { min = array[i]; } } ret[0] = max; ret[1] = min; return ret; }计数排序在外面平时做题时,也是经常遇见了。例如:去掉数组中重复的元素、找出数组中只出现一次的元素等。
总结:常见的八大排序的情况:
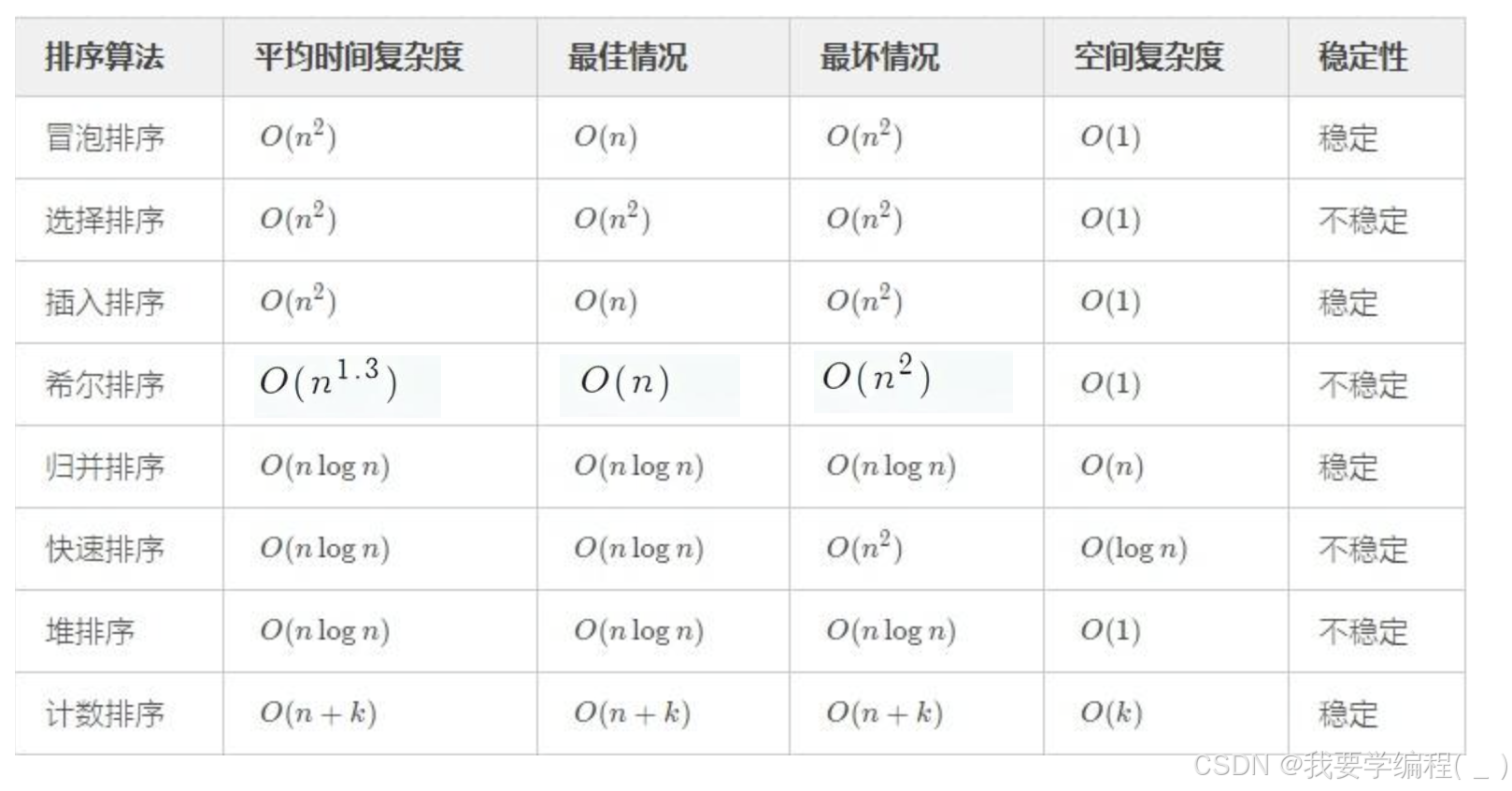
这里的希尔排序可以是1.3-1.5,也可以是1-2。由于没有研究证明因此不能得出确切的答案。
好啦!本期 数据结构之八大排序(下)的学习之旅就到此结束啦!我们下一期再一起学习吧!