【C++初阶】:C++入门篇(一)
文章目录
前言一、C++命名空间1.1 命名空间的定义1.2 命名空间的使用 二、C++的输入和输出2.1 cin和cout的使用 三、缺省参数3.1 缺省参数的分类 四、函数重载4.1 函数重载概念及其条件4.2 C++支持函数重载原理 -- 名字修饰
前言
C++是在C语言的基础之上,增加了一些面向对象的编程思想,增加了一些有用的库,所以有了学习C语言的经验,学习C++其实很容易的。至于C++初阶,我们可以认为C++的出现其实就是为了弥补C语言在某些方面的不足之处。所以从这篇开始,一起来学习C++,以及C++到底弥补了C语言的哪些不足。
一、C++命名空间
学过C++的人都知道,在学习C++的过程中,比如在某些视频教程中,教我们写的第一个程序往往都是打印hello world,但是每次在写的过程中,老师们都叫我们去忽略一些东西,比如using namespace std; 那这句话到底有什么用呢?
无论是C语言还是C++,在同一个局部域里面是不允许出现相同的变量名的,在同一个作用域下定义了两个相同变量名的变量会导致访问冲突,编译器不知道该使用哪个变量,从而导致报错。不仅仅是变量名,函数名相同也是一样的(C++函数重载除外)。这也导致在一群人写同一个项目时,写完在合并之后可能导致函数名或变量名冲突的问题,为解决这个问题,C++的命名空间孕育而生。
命名空间的目的就是对标识符的名称进行本地化,避免命名冲突或名字污染,namespace关键字就是为了解决这样的问题。
1.1 命名空间的定义
定义命名空间时,需要用到namespace这个关键字,后面紧跟命名空间的名字,再接一队 {},{} 中为命名空间的成员。
一个命名空间就是定义了一个新的作用域,命名空间的所有内容都局限于这个命名空间中。
namespace N1 // 命名空间N1{int a = 10;void test(){printf("test() a = 10\n");}}namespace N2 // 命名空间N2{int a = 20;void test(){printf("test() a = 20\n");}namespace N3 // 命名空间N3, 命名空间的嵌套{struct Node{struct Node* next;int data;};}}1.2 命名空间的使用
要使用命名空间的内容有三种方法,第一种就是命名空间名称加作用域限定符。
格式:命名空间名称::命名空间成员
int main(){printf("%d\n", N1::a); // :: 是作用域限定符N1::test();printf("%d\n", N2::a);N2::test();N2::N3::Node node;node.data = 123;printf("%d\n", node.data);return 0;}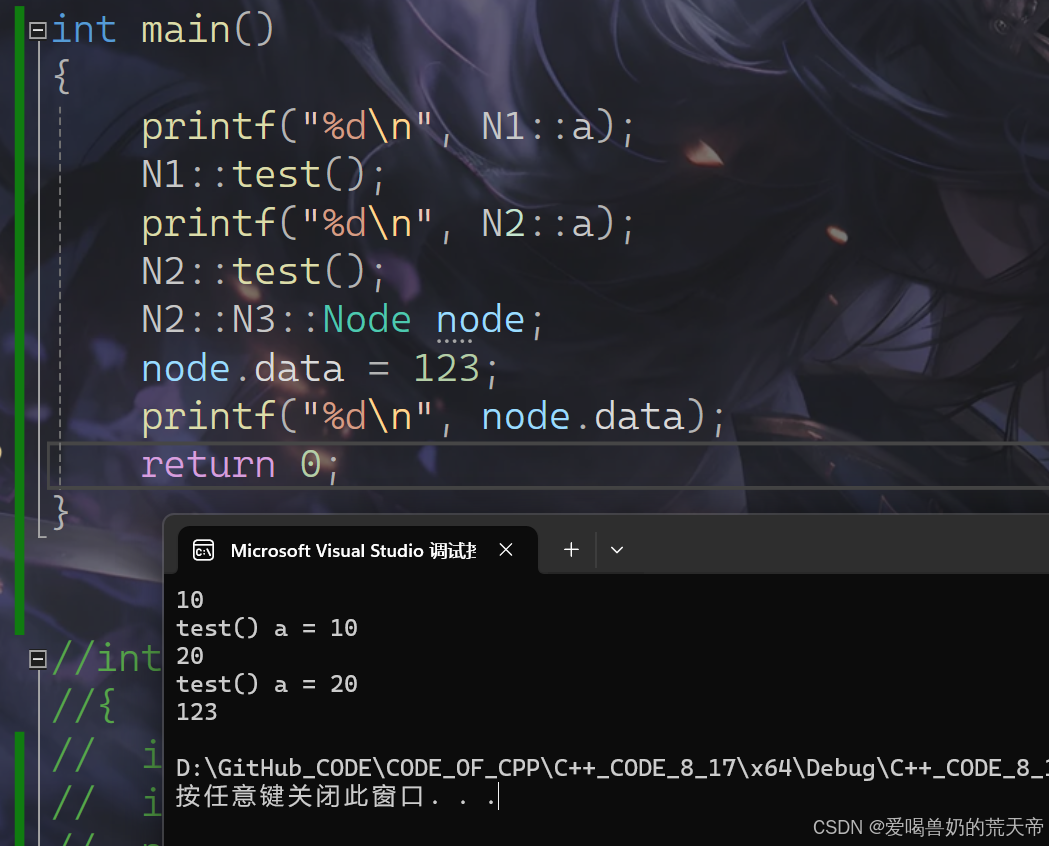
方法二:使用using将某个命名空间的某个成员引入。
格式:using 命名空间名称::命名空间成员
using N1::a; // using N2::N3::Node;int main(){printf("%d\n", a);printf("%d\n", N2::a);Node node;node.data = 456;printf("%d\n", node.data);return 0;}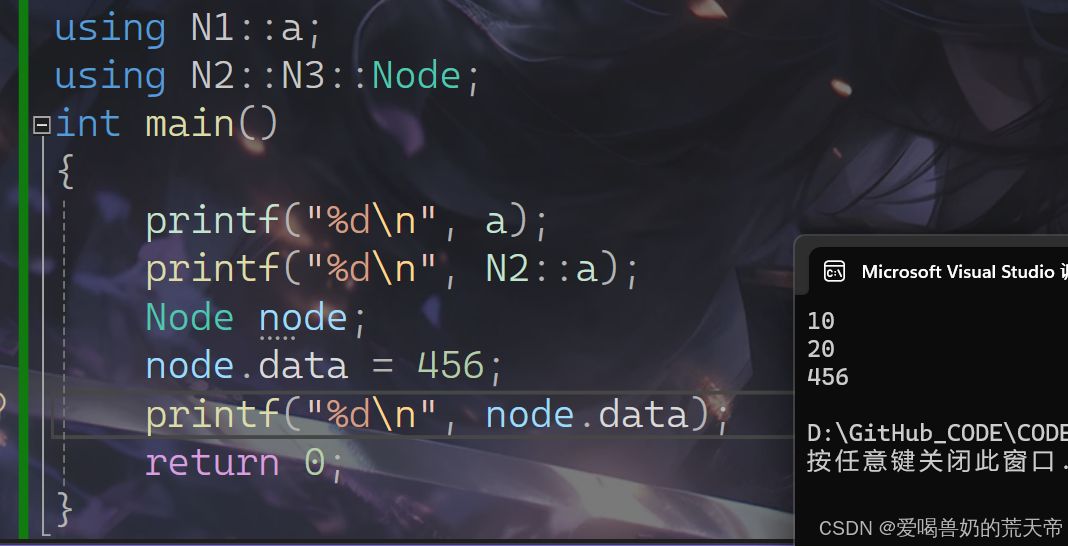
方法三:使用using namespace 命名空间名称引入。(不推荐)
格式:using namespace 命名空间名称;
using namespace N2;int main(){printf("%d\n", a);test();printf("%d\n", N1::a);N1::test();N3::Node node;node.data = 789;printf("%d\n", node.data);return 0;}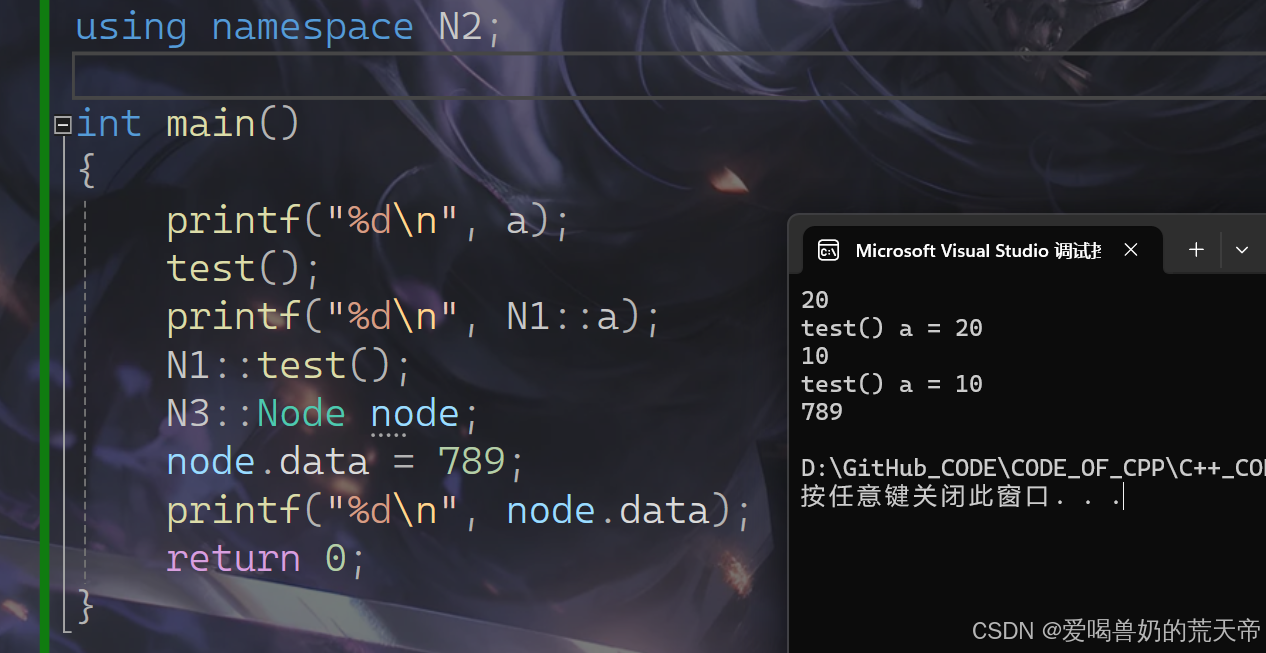
注意:使用 using namespace 命名空间名称; 就相当于破坏了作用域之间的封闭性,将命名空间中的成员全部暴露出来了。在日常练习中,建议直接using namespace std即可,这样就很方便。
了解完命名空间后,我们也算知道了为什么每次写C++程序时总要写一句using namespace std; std::是个名称空间标识符,C++标准库中的函数或者对象都是在命名空间std中定义的,所以我们要使用标准库中的函数或者对象都要用std来限定。
C++标准库,C++ Standard Library,是类库和函数的集合,其使用核心语言写成,由c++标准委员会制定,并不断维护更新。
using std::cout; // 分别将cout和endl释放出来using std::endl;int main(){cout << N1::a << endl;cout << N2::a << endl;N2::N3::Node node;node.data = 111;cout << node.data << endl;return 0;}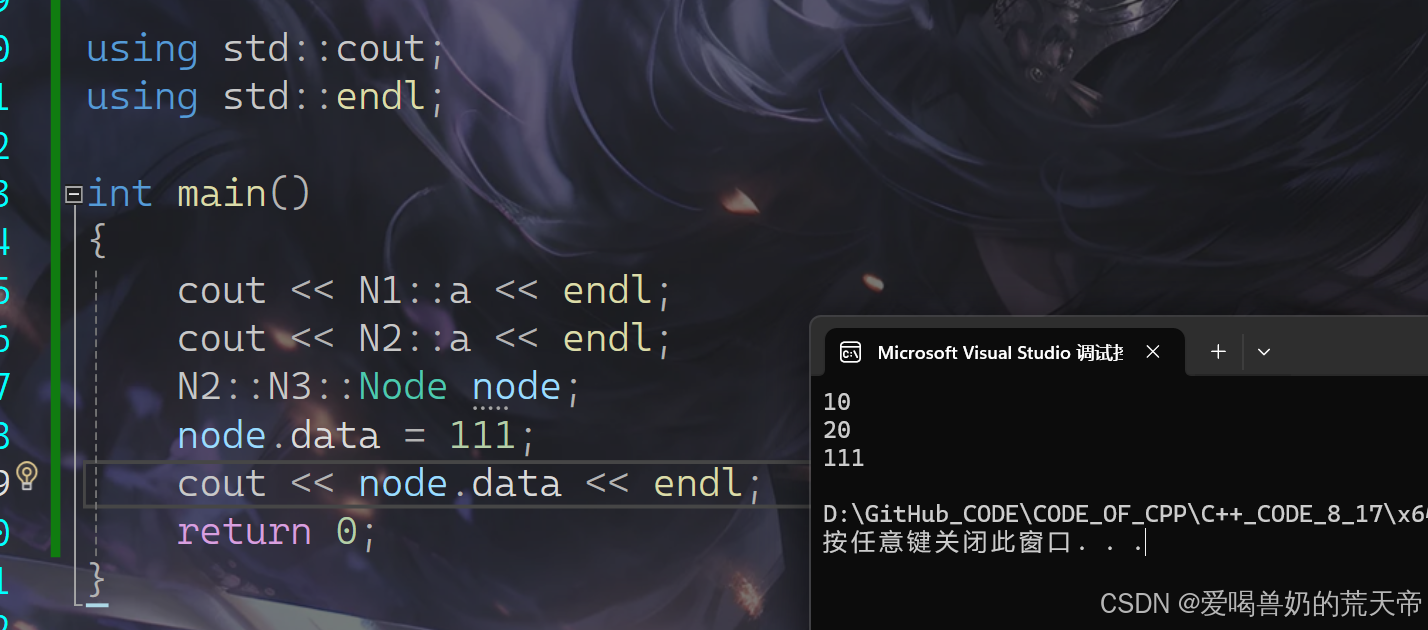
二、C++的输入和输出
C++作为一门新的语言,不但可以兼容C语言,C++自己也有属于自己的独有语法,最典型的就是C++不仅可以使用C语言中的printf和scanf,也可以使用自己的输入输出语句,cout(输出) 和 cin(输入),这两个都是全局的流对象,endl是特殊的C++符号,表示换行。
cout标准输出对象(控制台)和cin标准输入对象(键盘)都必须包含iostream头文件以及按照命名空间使用方法使用std。
cout和cin分别是ostream和istream类型的对象,<< 和 >> 分别是流插入运算符和流提取运算符,实际是运算符重载过来的。
2.1 cin和cout的使用
#include<iostream>using std::cout;using std::cin;using std::endl;int main(){int a = 0;cin >> a; // cin和cout可以自动识别类型cout << a << endl;return 0;}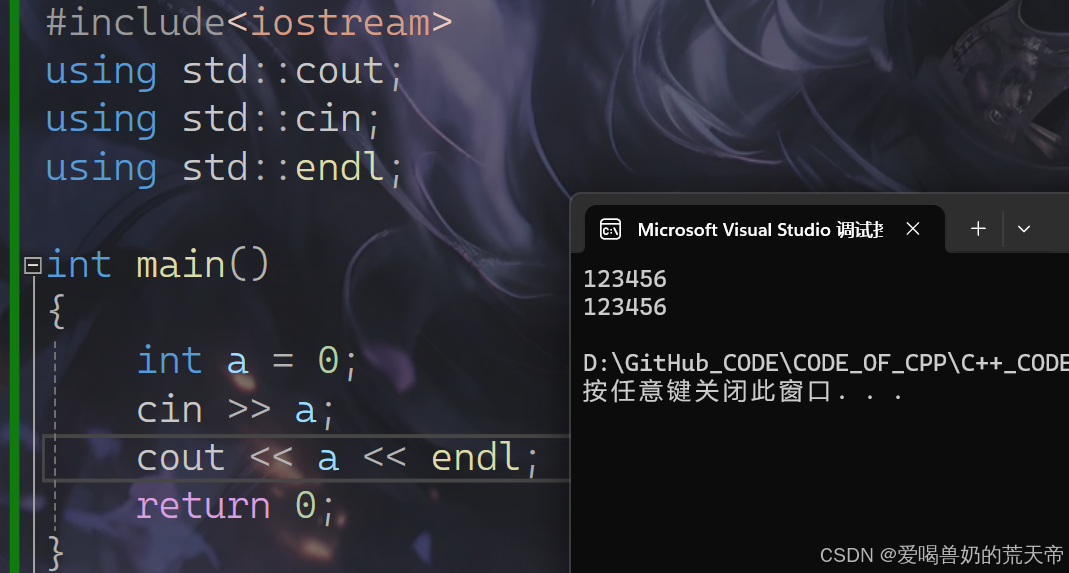
三、缺省参数
缺省参数就是在给函数声明或定义时给函数的参数一个默认的值,在调用该函数时,如果没有给函数传递实参的话,该函数调用时就会采用该形参的缺省值,如果调用时传递了实参,就采用指定的实参。
void test1(int a = 20){cout << a << endl;}int main(){int a = 10;test1(); // 没有传参时,使用参数的默认值test1(a); // 有参数传递时,使用指定的实参return 0;}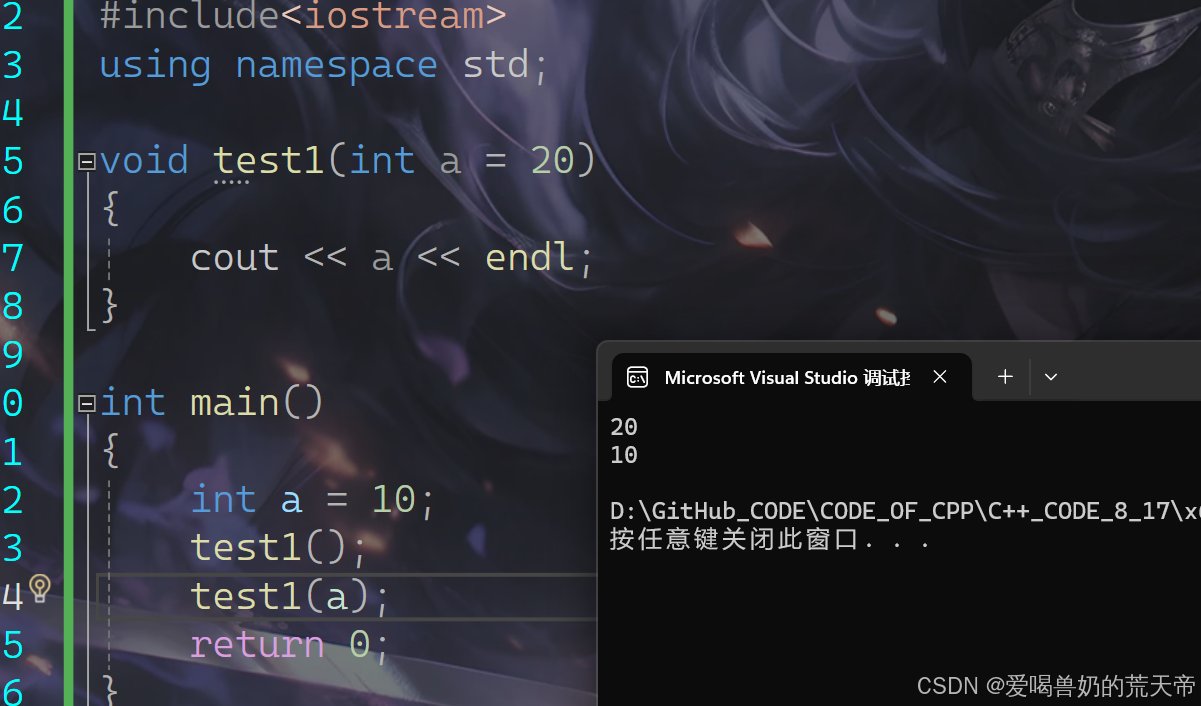
3.1 缺省参数的分类
全缺省参数函数的每个参数都有自己的默认值,这样的参数就是全缺省参数。
void test2(int a = 10, int b = 20, int c = 30){}函数的部分参数有默认值,其余参数没有参数值。
void test3(int a, int b = 10, int c = 20){}半缺省参数必须从右往左依次给,中间不能间隔,传参时也无法指定传参。另外,函数的缺省值不能再声明和定义中同时出现。那么,函数的缺省值是在函数的声明给还是在函数的定义时给呢?
其实只要我们仔细想一下就应该知道缺省值应该在函数的声明时给,因为函数往往都是先声明后使用,如果我们在声明函数时没有缺省值,但定义时又给了缺省值,就容易导致声明与定义不一致,另外,修改函数的声明比修改函数的定义要方便。
注意:函数的缺省值必须要是常量或则是全局变量,C语言不支持缺省参数其实就是C语言的编译器不支持。
四、函数重载
4.1 函数重载概念及其条件
自然语言中存在一词多义的现象,其意思需要人去结合上下文去判断,这就是词的重载,所以函数重载就是C++中允许同一个作用域中拥有功能相似的同名函数,同名函数之间的形参列表(形参类型、个数、类型顺序)不同,来处理一些功能类似数据类型不同的问题。
以下四个test01函数都构成函数重载。
// 参数个数不同void test01(){cout << "test01()" << endl;}// 参数类型不同void test01(int a){cout << "test01(int a)" << endl;}// 参数类型顺序不同void test01(int a, double b){cout << "test01(int a, double b)" << endl;}void test01(double a, int b){cout << "test01(double a, int b)" << endl;}注意:函数的返回值不构成函数重载,因为只有返回值相同的话会造成调用歧义,编译器不知道该调用哪个函数,从而编译报错。
4.2 C++支持函数重载原理 – 名字修饰
C++为什么可以支持函数重载,而C语言为什么不可以支持?
学习C语言的时候,可以知道,一个程序要运行起来,需要经历四个阶段:预处理、编译、汇编、链接。
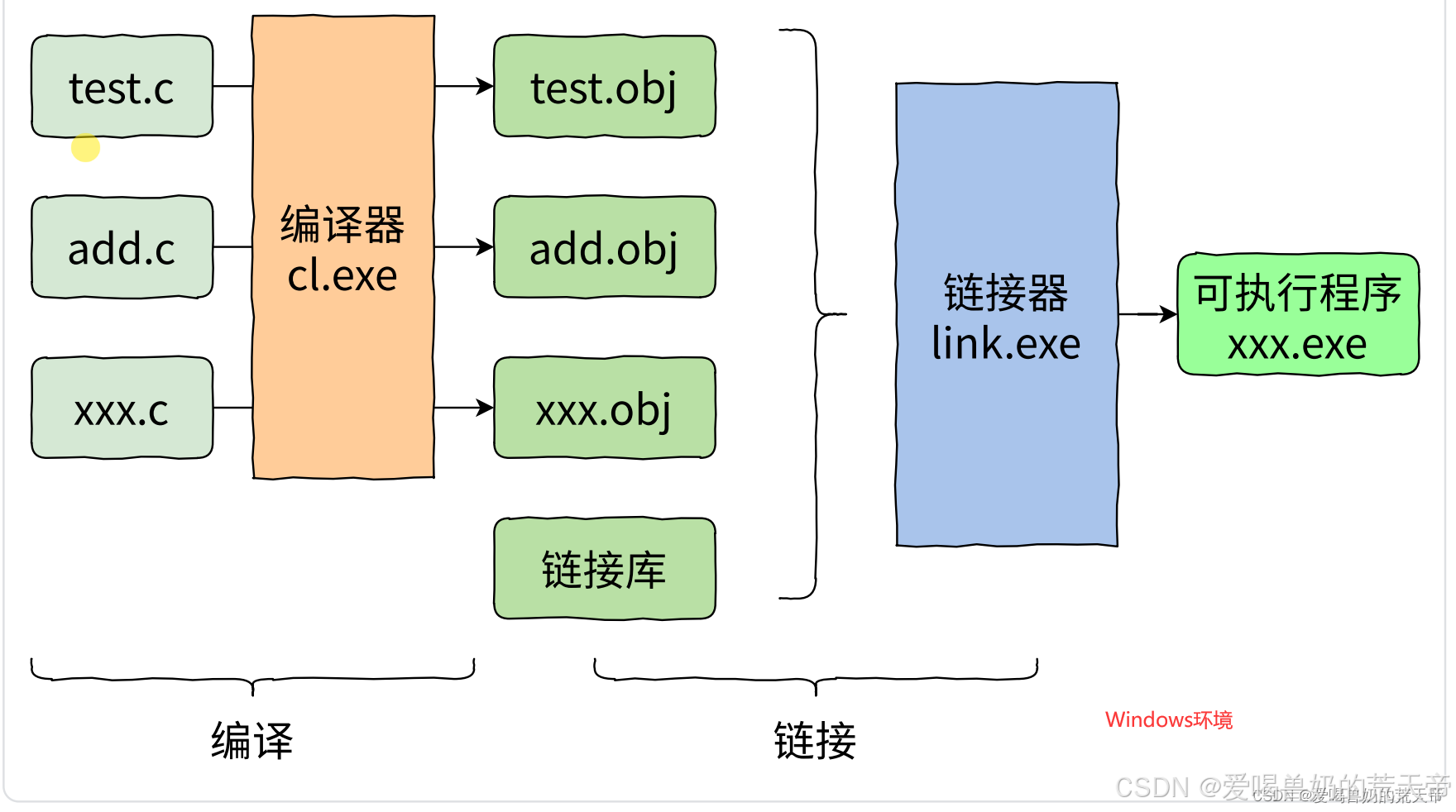
编译之后,会有一个符号表,函数会有自己的名字修饰,像Windows中VS的函数名修饰规则有点复杂,我们可以通过Linux下的gcc来查看函数名修饰规则。
在Linux下我们可以先用gcc编译一下C语言代码,然后通过objdump -S 可执行文件来查看这个汇编代码,从而看C语言下的函数名修饰规则。
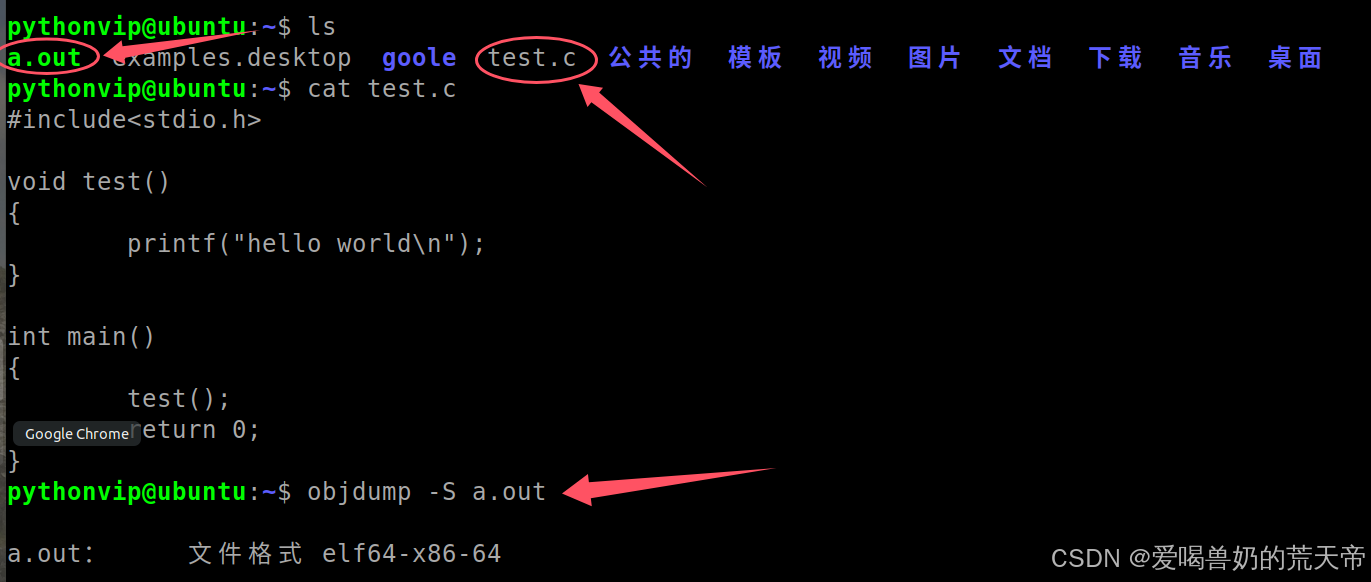
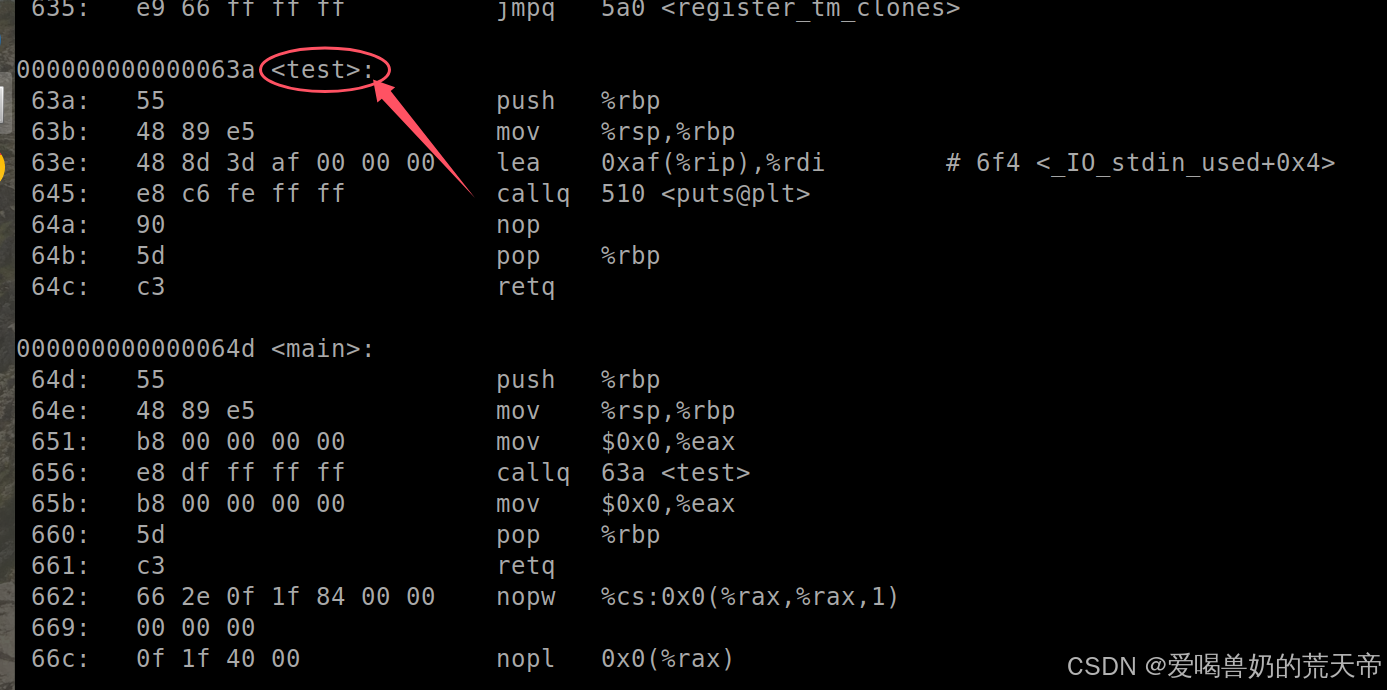
通过汇编代码,可以看到C语言下函数名就是修饰后的名字。所以如果C语言中有两个名字相同的函数,那么修饰后的名字也是一样的,编译器不知道该调用哪一个,导致编译报错。
现在我们用g++去编译C++的代码,然后去看一下汇编后函数名会修饰成什么样子。
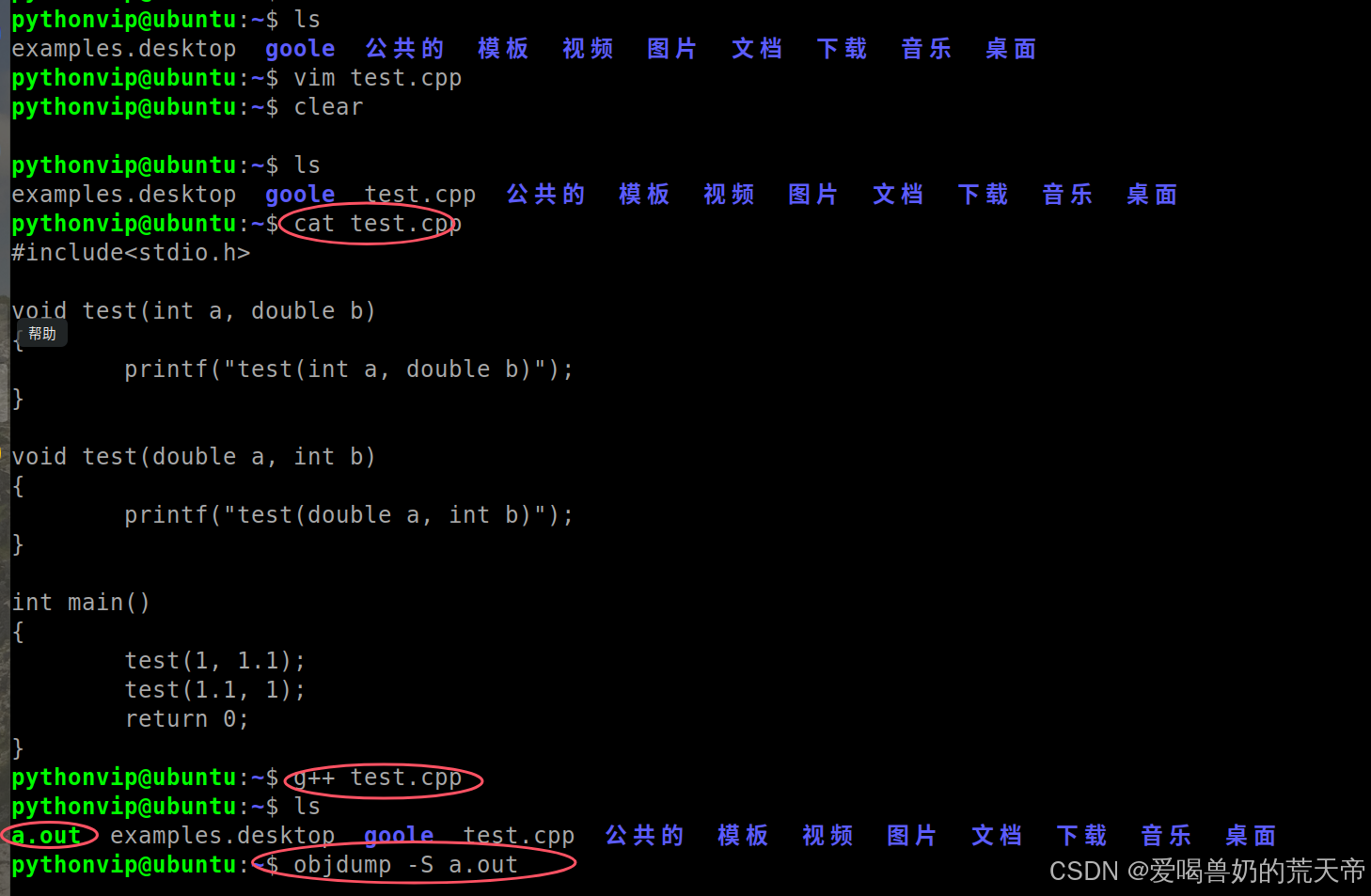
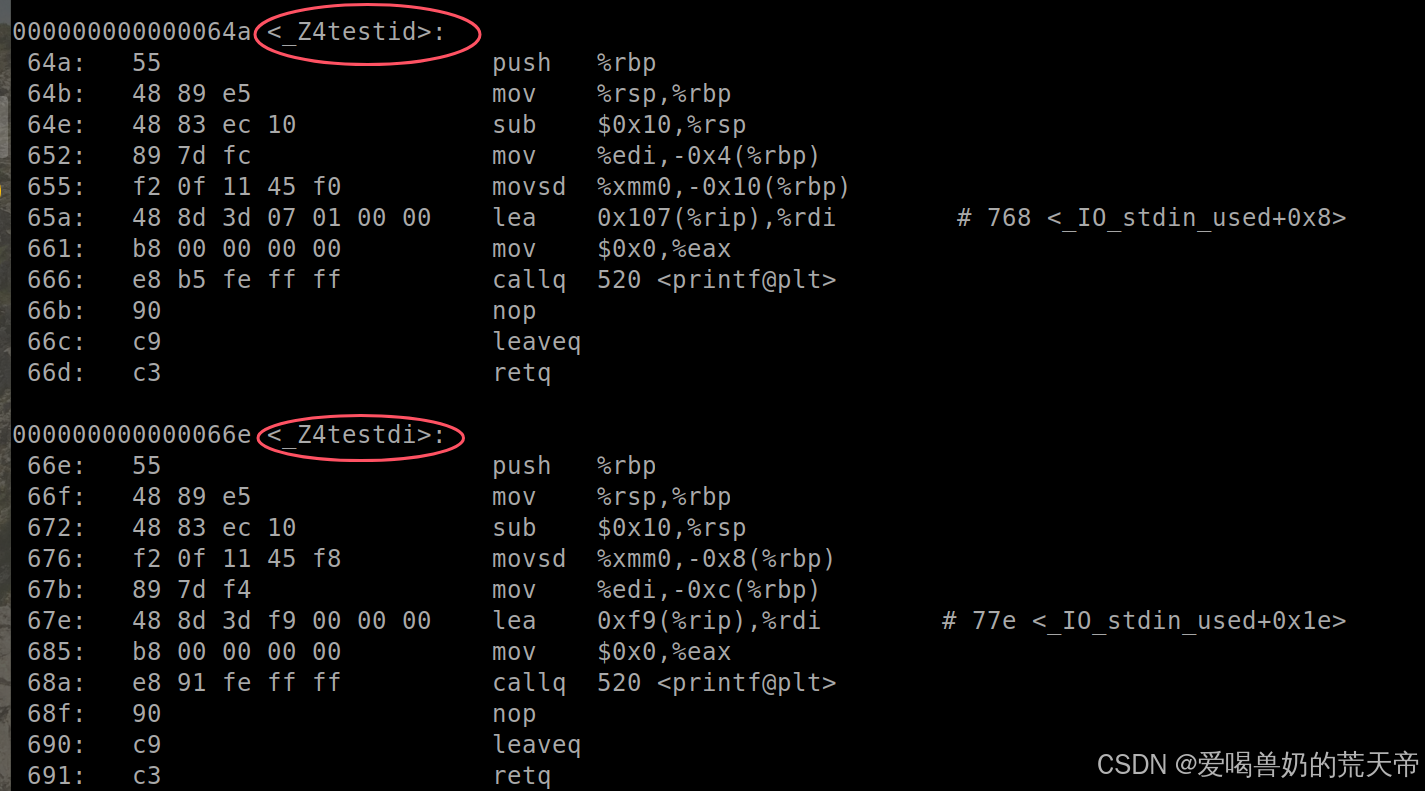
通过汇编代码可以看到C++不是单纯的用函数名进行修饰的,在函数名的前面加了一个 _Z 的前缀,函数名的后面是函数参数类型的缩写,id就表示该函数的参数类型是int和double类型,而di就表示该函数的参数类型是double和int类型,通过函数调用时传递的实参类型,决定调用哪一个函数。不会存在调用冲突的问题。
这也就是为什么C语言为什么不能支持函数重载的原因(同名函数编译后无法区分),而C++通过函数名修饰规则来区分,只要参数不一样,修饰出来的名字就不一样,也就支持了函数重载。
登录后可发表评论
点击登录