要实现从评价中提取高频关键词,并判别其正负面性,其实是通过人工智能领域中的一个分支:自然语言处理。
在了解自然语言处理之前,我们先来说说,什么是自然语言(Natural Language)?
自然语言,即人们日常使用的语言,也就是每天包围着我们的文本信息和语音信息。
了解自然语言
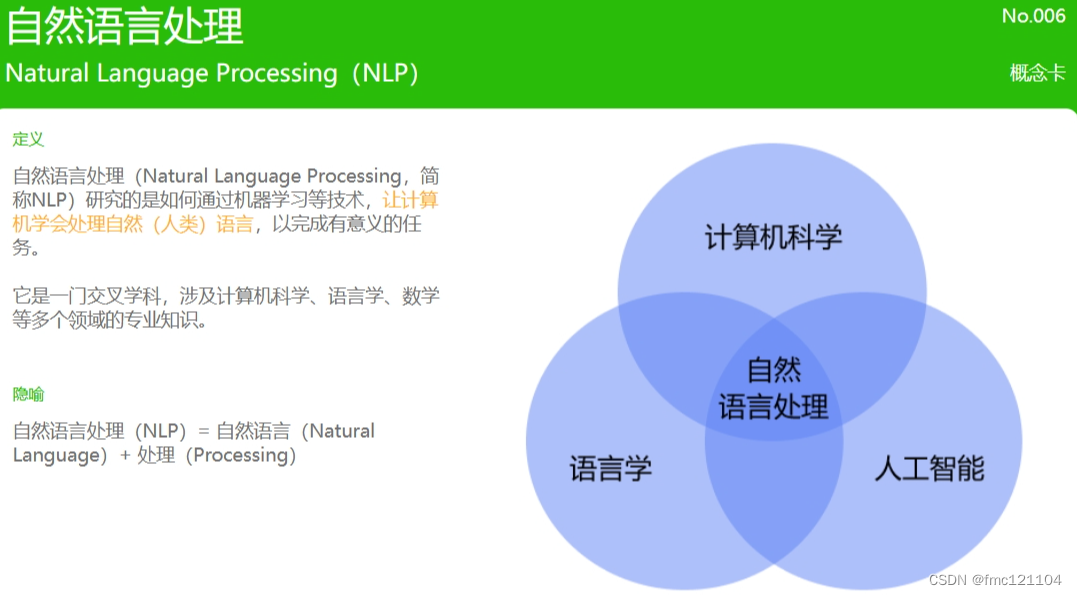
这样或许还不太能知道到底什么是自然语言处理,我们简单看一些它的应用,来帮助理解为什么要让计算机去处理自然语言吧~
1.邮件过滤:
系统会根据电子邮件的内容识别电子邮件是否属于三个类别(重要、社交或广告)之一,或者判断一封邮件是否是垃圾邮件。
此时就是通过NLP来对这些邮件进行一系列的分类。
2. 搜索引擎,如百度、谷歌等。
在我们输入2-3个字后,搜索引擎会显示可能的搜索词。或者如果输入了错别字,搜索引擎会自动进行更正。
这就是通过NLP技术来实现的搜索自动完成和自动更正功能,帮助我们更有效地找到准确的结果。
3. 机器翻译,比如Google、有道翻译。
目前所追求的翻译,不再仅仅是通过计算机直接将一种语言转换为另一种语言,而是需要像人类一样能够理解世界知识和上下文。
要让电脑像人类一样理解自然语言,必然离不开NLP技术。
4. 语音助理,比如Siri、智能音箱等。
现在的语音助理,与人类之间的交流不再是简单的你问我答,不少语音助手甚至能和人类进行深度交谈。
同样在这背后离不开NLP技术,使得语音助理能够将人类语言转换为机器语言,然后执行相应的操作。
通过这些例子大概可以感受到,我们每天都会产出大量的自然语言信息。在面对自然语言时,除了单纯地阅读和倾听外,往往会进行更多复杂的操作和处理。
但人工处理的代价过于高昂,因此会期望训练计算机来代替人类,这就是自然语言处理的意义。
然而,自然语言并没有想象中那么容易处理。
与人工语言(编程语言或数学语言等)相比,自然语言有着多变、非结构化等各种特殊和复杂的特点。
例如:
编程语言中的关键词数量是固定的,而自然语言中能使用的词汇量是无限的,甚至还在不断创造新词;
编程语言具有结构性,如类和对象,但显然自然语言不具有这样的结构。

总结一下,广义上来讲任何处理自然语言的计算机操作都可以被理解为NLP。
它可以实现一些简单的功能,比如短语之间的翻译。
同时,NLP也致力于完成一些具有挑战性的任务,比如完全“理解”人类话语。
了解完自然语言处理(NLP)的基本概念、应用和面临的一些挑战后,我们来思考一下:
在自然语言这个复杂的系统里,是否存在一个基本单位呢?
这样便可以把无规律的文本信息降维处理后,再来完成后续的NLP任务。
拆解文本
1.一篇文本是由无数句话组成,而一句话又是由一个个词语组成,因此可以将词语看作是自然语言的基本单位。
那么在进行NLP时,就需要先将句子中的词语分开。
对于英文,只需要按照空格和标点符号就可以将词语分开。但在中文文本里,所有的字都连在一起,计算机并不知道一个字应该与其前后的字连成词语,还是应该自己形成一个词语。
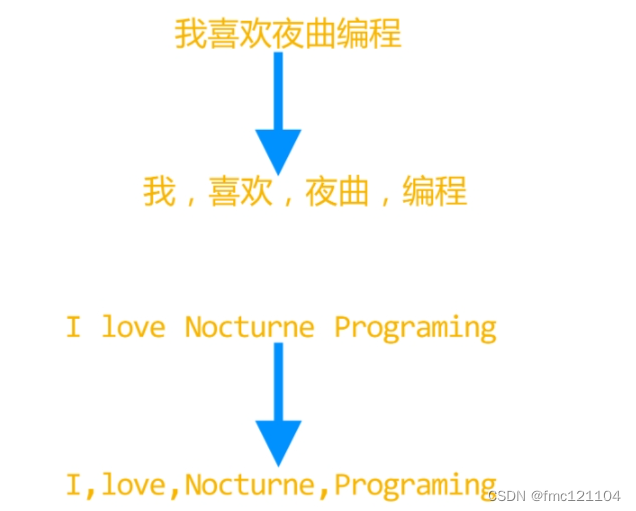
因此,需要借助额外的工具将中文文本中的词语分隔开。这项技术被称为中文的分词,具体的操作我们会在下节课进行学习。
2.分词完成后,就可以根据这些词语找到属于这个文本的特点,也就是常说的特征(feature)。对于文本而言,词语出现的频率就可以作为一项特征。那么,词频这个特征就能帮我们提取出关键词。在进行NLP时,构造词袋模型(Bag-of-Words Model)是一种常用的用于统计词频的技术。





可以看到,通过词袋模型生成的结果,词的顺序和语法都被忽略了,变成了一些词语间的组合,但又在一定程度上保留了主题信息。
我们根据词袋中“物流”、“屏幕”等词语,仍然可以知道这三条评价与物流和屏幕有关。同时,根据词频,我们也获取了关于这三条评价的关键词:“满意”、“物流”和“屏幕”。
将复杂的词句结构降维成体现主题的词语计数,以便计算机进行后续的处理。这就是词袋模型的基本思想。
分析商品评价:
根据刚才的思路分析,我们就得到了如下解题步骤:
1. 寻找、读取,并处理数据集
2. 统计词频,提取关键词
3. 构造模型,预测评价的正负面性
今天我们会先学习第一个步骤:寻找、读取和处理数据集。


什么是CSV文件呢?
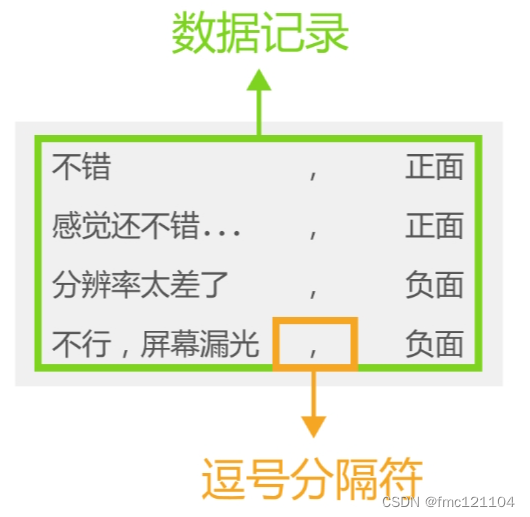
CSV(Comma-Separated Values)(逗号分隔值)文件以纯文本的形式储存数字、文本等表格数据。它的数据格式如图所示,文件中多个数据之间通常用逗号分隔,每一行的数据都是相同的结构。
读取CSV文件
代码的作用
这段代码展示了使用csv模块来读取存储了电视评价的CSV文件。
STEP1. 导入csv模块
STEP2. 打开文件
STEP3. 读取文件
# 导入csv模块
import csv
# 使用open()函数打开数据集,并将返回的文件对象存储在变量file中
file = open("/Users/yequ/TVComments.csv", "r")
# 使用csv.reader()函数读取数据集,并赋值给变量reader
reader = csv.reader(file)
解析代码
1. 导入模块
Python提供了一个用于处理CSV文件的模块:csv 模块。由于是内置模块,所以不需要安装,直接使用import导入即可。
2. 打开文件:open()
在使用csv模块读取文件前,得先通过open()函数打开需要被读取的文件。该函数用于打开一个文件,并返回对应的文件对象。
open()函数:第一个参数
第一个参数是文件路径(path),也是必选参数。本例中,将存储了电视评价的数据集的路径:"/Users/yequ/TVComments.csv",作为必选参数传入到open()函数中。
open()函数:第二个参数
第二个参数代表打开方式,用特定的字符串表示。我们只需要读取该文件,所以使用 r ,表示以只读的方式读取文件。
文本对象
open()函数返回一个文件对象,我们将它存储在变量file中。
3. 读取文件:csv.reader()
打开数据集后,我们就可以使用csv.reader()函数读取CSV文件,只需将文件对象file作为参数传入其中。
reader对象
使用csv.reader()函数时,返回的是一个reader对象,我们将它存储在了变量reader中。
逐步修改
什么是reader对象?
读取文件后,获取到的是一个reader对象。
reader对象存储的是CSV文件里所有行数据,相当于每一行数据都作为字符串列表返回。
我们可以使用for循环遍历它,输出每一次遍历结果进行查看。
查看提取信息
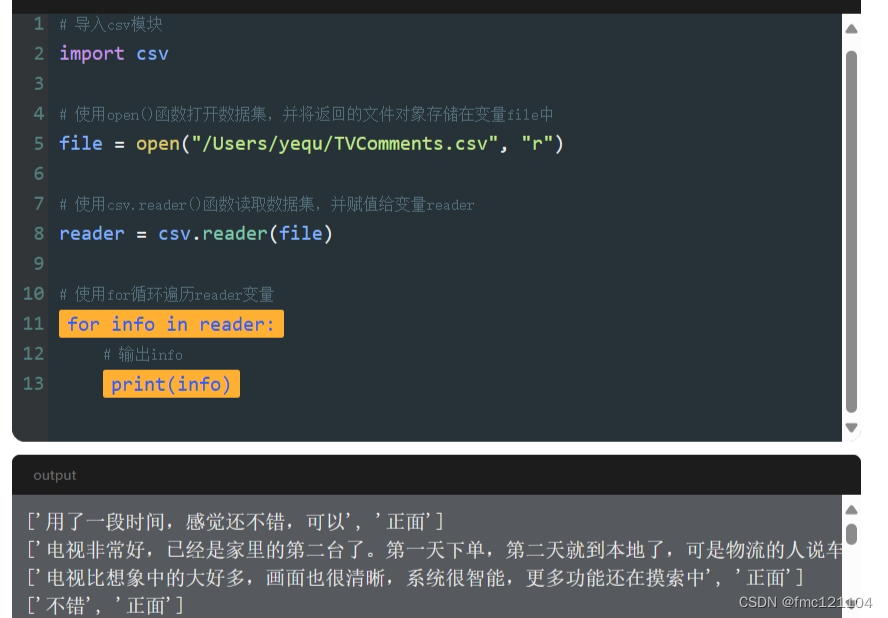
根据输出可以看到,CSV文件里的每一行都被读作成了一个字符串列表。由于CSV文件有两列数据,所以对应的每个列表里都有两个元素:
第一个元素是评价;
第二个元素是该评价对应的正负面性。
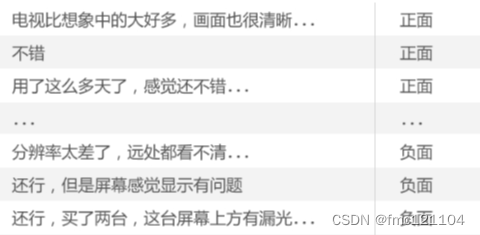
这就意味着,CSV文件里有多少行评价数据,reader对象中就有多少个列表。
为了方便接下来对所有的评价进行处理,我们可以对reader变量里的数据进行标准化处理。
标准化处理
具体的方法是把所有的评价都存储在一个列表中,这样不论是遍历所有评价还是访问单独的某一条评价,都会非常方便。
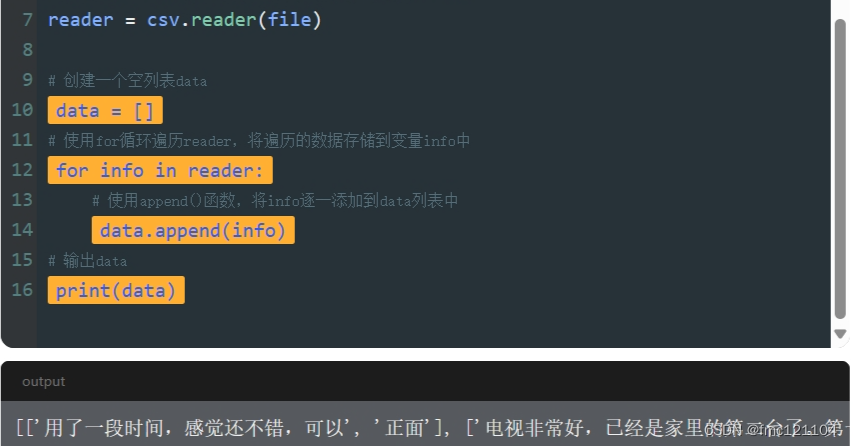
步骤如下:
1. 先创建一个空列表,用于存储reader对象中的值
2. 使用for循环遍历reader对象
3. 使用append()函数,将reader对象中的每行数据添加到空列表data中
完成后,data列表里存储的就是我们需要的电视评价数据啦~
修改代码如下:
输出结果
