AI赋能自动化测试:智能接口自动化测试数据生成平台设计思路
目录
1.背景
2.名词解释
3.设计目标
4.设计思路及折衷
4.1阶段性任务
4.2方案选型
4.2.1 设计方案选型
4.2.1.1 原始数据获取模块
4.2.1.2 数据构造模块
4.2.1.3 预执行模块
4.2.1.4 覆盖率反馈调整模块
4.2.1.5 预测模型
4.2.2 技术选型
5.系统设计
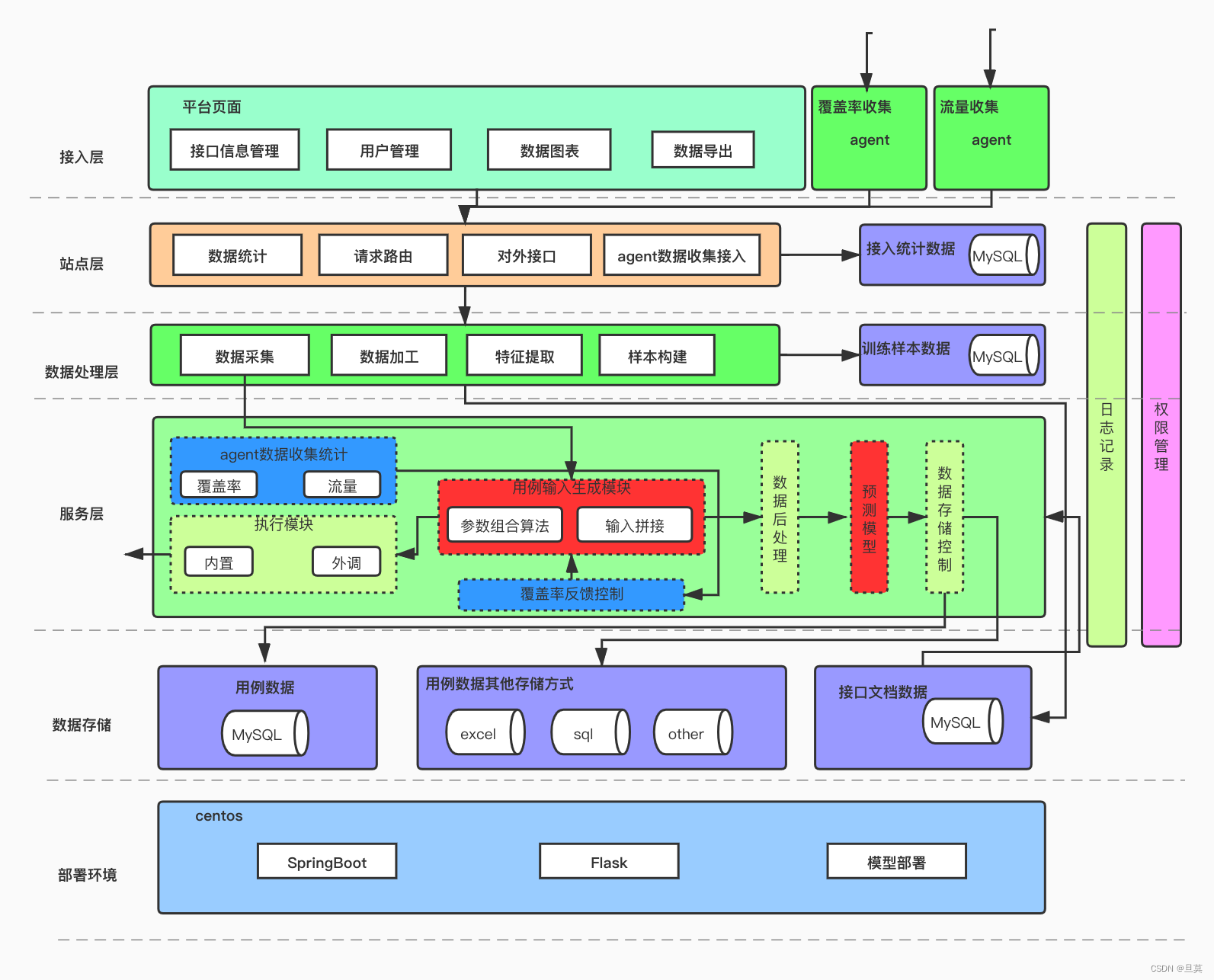
5.1 项目架构
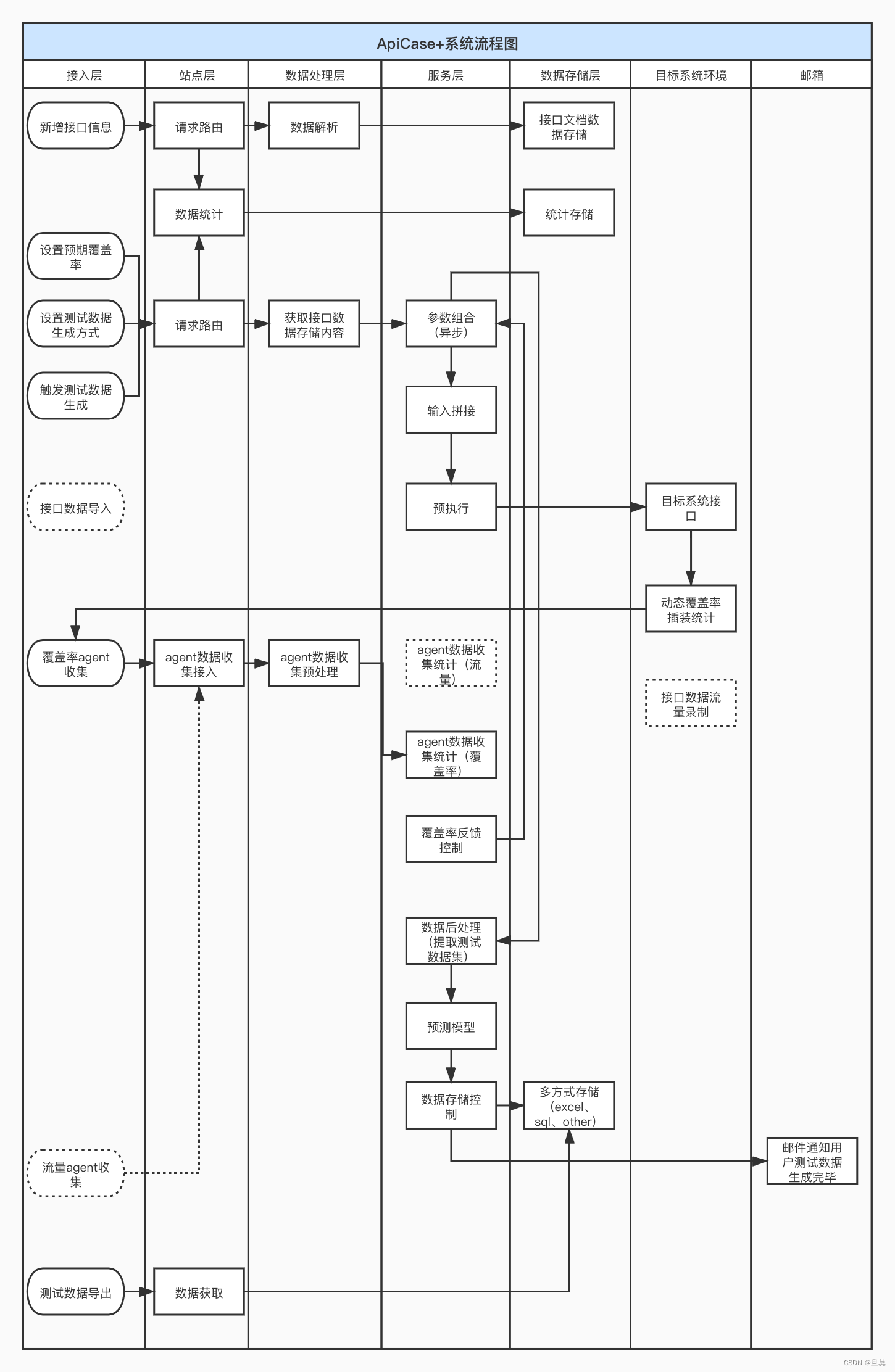
5.2 流程图
编辑
5.3 模块详细设计
5.3.1 原始数据获取模块
5.3.2 数据构造模块
5.3.3 预执行模块
5.3.4 覆盖率反馈调整
5.3.5 预测模型
5.3.5.1 定义问题
5.3.5.2 数据处理
5.3.5.3 训练模型
5.3.5.4 部署上线
1.背景
1)目前自动化测试用例维护成本极高且维护人员缺乏维护“兴趣”;
2)现有自动化数据生成方案,数据质量和量级难以均衡保障;
3)公司内部测试提效平台繁多,缺乏核心部件测试数据,没有测试数据就无法很好的接入使用各类提效平台。
2.名词解释
例子:根据天气情况预测是否可以打球
数据集:机器学习使用的数据集合被称为“数据集”
样本:数据集中的每一个数据
特征:像气象信息中的天气、温度、湿度这些数据
标签:“是否可以打球”就是机器学习根据当天数据做的一个概括性结论
模型:获得基于天气特征来判断是否适合打球的“理论依据”
学习/训练:从数据集中“学得”模型的过程
训练数据集:训练中使用的数据集
测试数据集:有了模型后需要评估模型的好坏和准确性,将模型应用到另一批有标签的数据上,通过训练的出结果,这批带标签的数据集就是测试数据集
3.设计目标
1)通过平台可以产出基于最小集合且符合目标覆盖率的接口测试数据;
2)产出数据支持多样化存储、调用;
3)结合流量回放机制,补充完善自动化接口测试用例;
4)引入机器学习方法,尝试在测试提效中落地;
5)全面用于接口冒烟测试、回归测试。
4.设计思路及折衷
4.1阶段性任务
平台整体开发可分三个阶段进行:http接口自动生成开发、RPC接口自动生成开发、接口录制功能开发。
4.2方案选型
4.2.1 设计方案选型
核心系统功能可分为:原始数据获取模块、数据构造模块、预执行模块、覆盖率反馈调整模块、预测模型。
4.2.1.1 原始数据获取模块
预选方案有三种,分别是:
通过动态获取代码变更状态,静态分析代码并识别接口数据;基于开源接口管理平台开发平台站点,同步现有API管理平台的数据;复用API管理平台,在原有功能基础上扩展所需功能结论:由于方案3前后端均使用react编写,在此基础上复用学习成本高且考虑后期功能扩展不易改动所以选择方案2。
4.2.1.2 数据构造模块
平台输入(参考api管理平台)落库:
现有平台模式可以输入获取接口基本信息、参数信息、输出示例;原有基础上增加参数值范围输入、输入示例填写、参数正确性是否强校验;根据输入示例构建模板,利用参数值范围通过Cartesian product+Pairwise进行用例构造4.2.1.3 预执行模块
利用内置执行模块,构建接口参数化进行请求,如:接口测试框架、http标准库等。可以调用第三方执行模块,传入已构建的请求数据,如:现有自动化测试平台。4.2.1.4 覆盖率反馈调整模块
提供目标覆盖率设置功能,通过预执行模块将生成的接口输入数据发送至目标系统,利用动态覆盖率统计得出实时覆盖率,对比覆盖率结果是否满足预设覆盖率目标,如果不满足则调整构造数据算法重的n元素对偶生成(2~n逐级上调),每次调整生成数据量级后随之增加,相应接口覆盖率也会增加。按照数据生成 -- 请求反馈覆盖率 -- 数据生成元素纬度调整形成闭环,当满足目标覆盖率后,停止元素纬度增加,即得出满足目标覆盖率的最小数据集。
4.2.1.5 预测模型
使用大量原始接口数据的输入和输出训练结果预测模型,问题:输入与输出参数较少,类型复杂且部分情况存在二义性,难以得出直接的对应关系。在方案1基础上缩小预测目标,定位分类问题为:结果类型预测,在原始数据基础上进行特征提取和构建,利用输入特征与标签构建训练样本集,训练输出结果二分类的模型(后期可以进一步提模型效果进行多分类模型训练)。结论:采用方案2的建模方式,通过缩小预测目标达到解决问题的准确性。
4.2.2 技术选型
| 机器学习框架 | 优点 | 缺点 | 备注 |
| Tensorflow | 高自由度 |
|
|
| Scikit-learn | 使用简单资料多传统机器学习库的瑞士军刀 |
|
|
结论:Scikit-learn
| 模型算法 | 优点 | 缺点 | 备注 |
| 决策树 | 决策树易于理解和解释,可以可视化分析,容易提取出规则可以同时处理标称型和数值型数据比较适合处理有缺失属性的样本能够处理不相关的特征运行速度比较快,且可以应用于大型数据集 | 容易发生过拟合容易忽略数据集中属性的相关联对于各类样本数据量不一致的数据,在决策树中进行属性划分时,不同的判定准则会带来不同的属性选择倾向 |
|
| 随机森林 | 不要求对数据预处理集成了决策树的所有优点,弥补了其不足支持并行处理使用超高维度数据集、稀疏数据集、线性模型更好 | 生成每棵树的方法是随机的,不同的random_state会导致模型完全不同,因此要固化其值比较消耗内存、运行速度慢。如果要节省内存和时间,建议用线性模型 |
|
| KNN(K近邻算法) | 简单易用,相比其他算法简洁明了模型训练时间快预测效果好对异常值不敏感
| 对内存要求较高,因为该算法存储了所有训练数据预测阶段可能很慢对不相关的功能和数据规模敏感
|
|
| SVM(支持向量机)
| 可以解决高维(大型特征空间)问题解决小样本下机器学习问题能够处理非线性特征的相互作用无局部极小值问题(相对于神经网络)不用依赖整个数据泛化能力比较强 | 当观测样本很多时,效率并不是很高对非线性问题没有通用解决方案,有时很难找到一个合适的核函数对于核函数的高维映射解释能力不强常规SVM只支持二分类,多分类开发稍复杂些对缺失数据敏感 |
|
结论:综合比较了几种模型算法,考虑初次尝试将机器学习引入测试提效中且本次划分问题类别并非很复杂的场景,所以排除掉了非经典机器学习算法,在剩下的经典机器学习算法中,对比了决策树、随机森林、支持向量机以及K近邻算法,根据算法本身优缺点我们首先排除决策树和K近邻算法,因为决策树的易过拟合、K近邻训练耗时较高。最后对比随机森林和支持向量机,这两种算法均支持分类问题的解决,但是考虑到后面本平台需要解决的问题不仅限于二分类,支持向量机对于多分类的支持并不好,所以最终选择随机森林算法作为本次建模主要算法。
| 用例构造算法 | 优点 | 缺点 | 备注 |
| Cartesian product | 覆盖所有参数组合可能 | 冗余组合,形成用例爆炸 |
|
| Cartesianproduct+Pairwise | 不区分语言使用 | 需自己做算法实现 |
|
| allpairs | 无需自己做实现算法 | python三方库,Java无法直接使用 |
|
结论:Cartesianproduct +Pairwise
5.系统设计
5.1 项目架构
5.2 流程图
5.3 模块详细设计
5.3.1 原始数据获取模块
5.3.2 数据构造模块
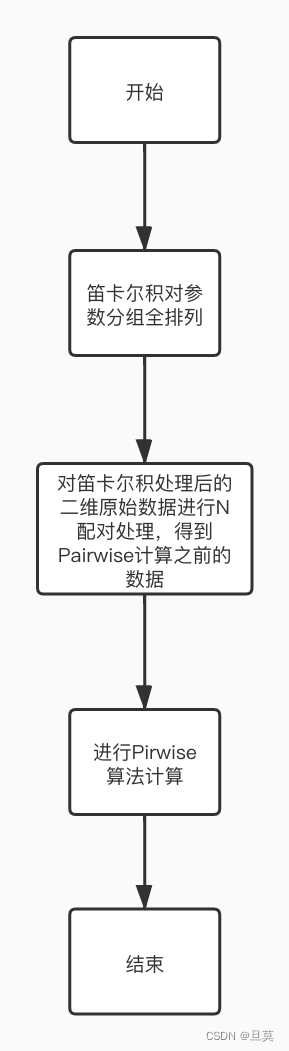
数据构造流程图
5.3.3 预执行模块
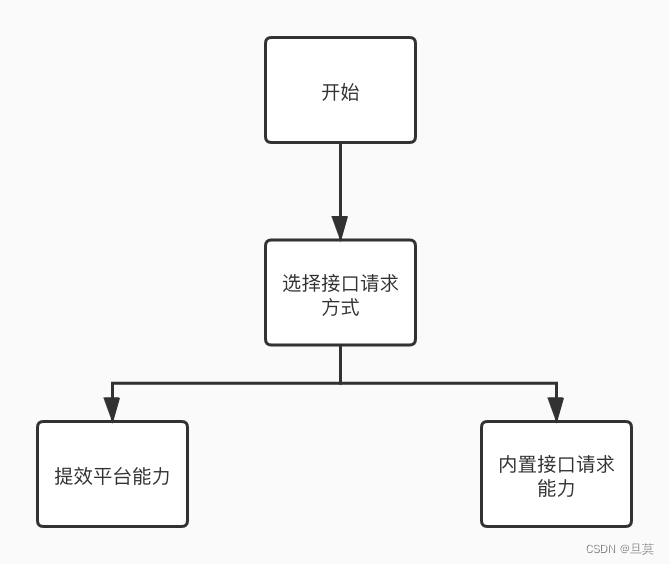
预执行流程图
5.3.4 覆盖率反馈调整
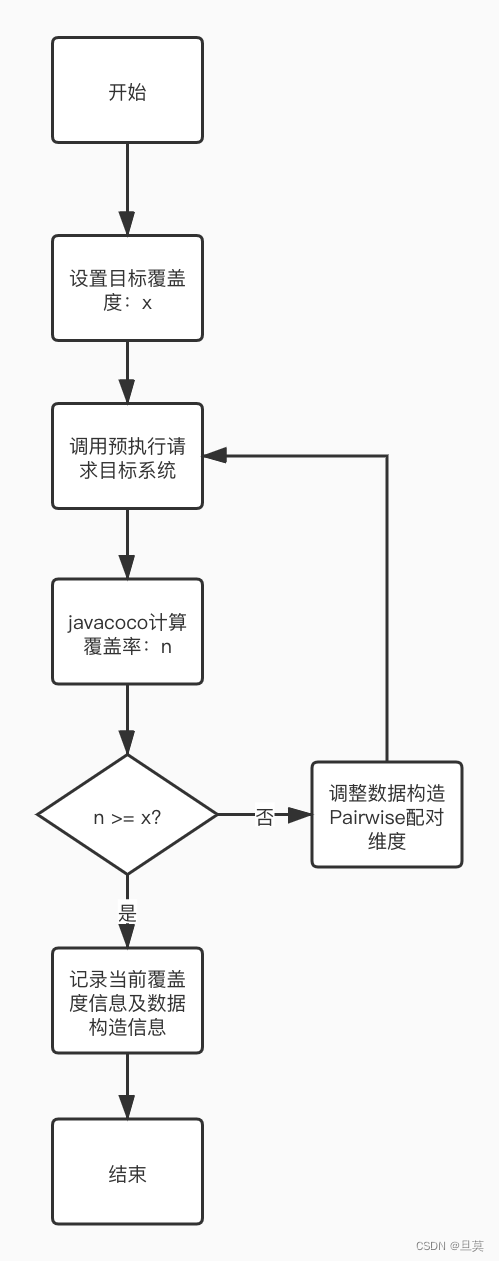
覆盖率反馈调整流程图
5.3.5 预测模型

机器学习生命周期
5.3.5.1 定义问题
1)是否采用机器学习
接口测试方式在整个测试生命周期中相对规范,且接口测试用例设计理论较为成熟,日常工作中QA进行接口测试产出的测试数据恰好成为机器学习的最佳原材料,传统的自动化用例生成方式无法解决预期生成问题,因此考虑引入AI赋能。
2)评估问题分类
针对接口的输入输出关系,我们可以将接口测试的输入规则与输出数据抽象成二分或多分类问题,根据接口输入数据的特征,会有强相关的输出分类,如划分输入对应正向用例以及非正向用例即二分类,输入对应正向子类别用例-1、2、3......,非正向子类别用例-1、2、3......即多分类。
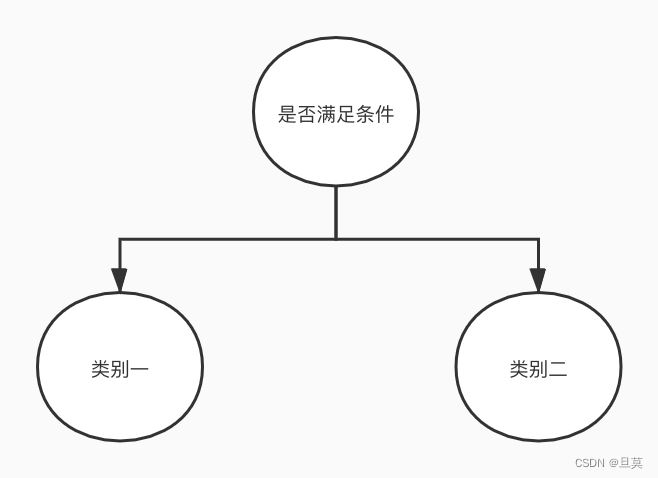
二分类示意图
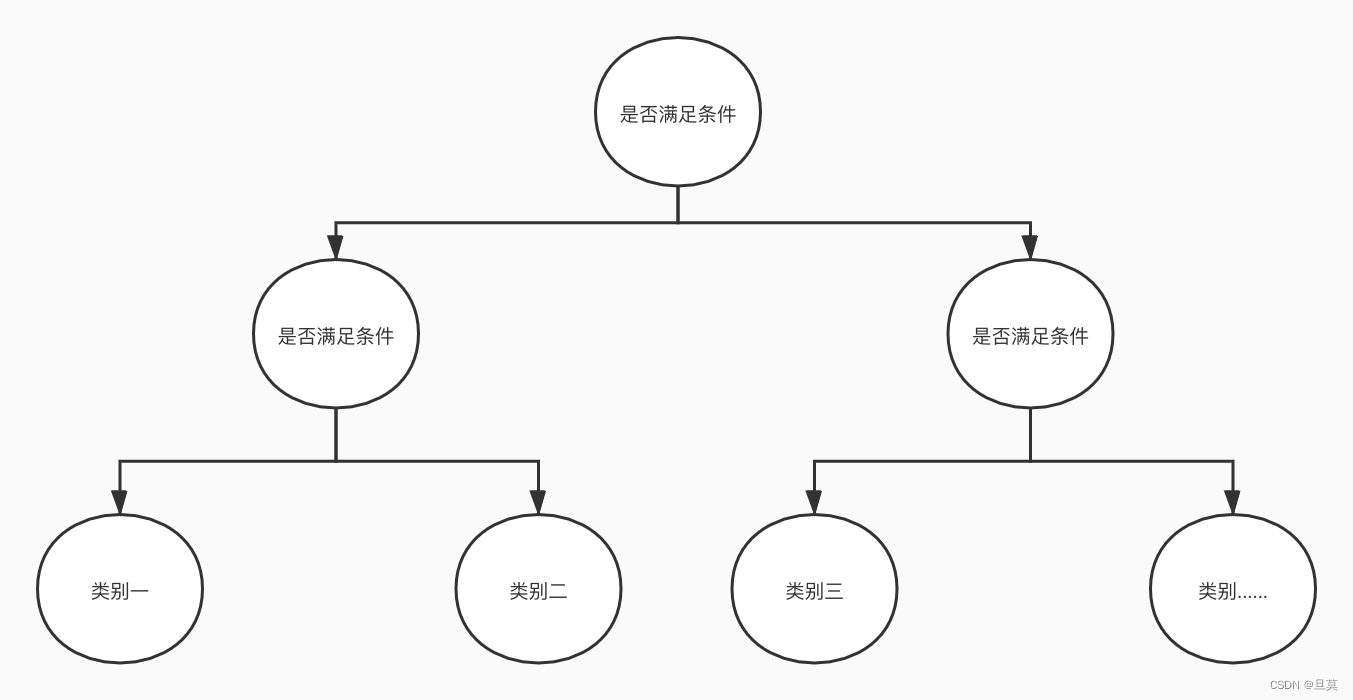
多分类示意图
3)选择监督学习还是非监督学习
如图所示,接口数据非常规范,均包含输入、输出,针对接口原始数据分析我们可以提取出相关特征及标签,这种规范的数据适合监督学习的训练,因此选择监督学习。
4)业务性能考虑
由于接口测试业务对于实时性要求并不高,所以本系统采用离线训练,线上部署的方式使用机器学习模型。
5)机器学习模型结果评定及缩小误差
由于机器学习模型的设计方案选型为随机森林,且接口原始数据可利用特征数量能够很好地满足我们要求,所以在模型优化方面我们可以采用超参调优以及优化训练集的方式来保证模型可信度。
5.3.5.2 数据处理
1)数据采集
接口数据采集来源清晰,本系统主要采集来源有两个: 1、平台页面端用户输入,经由原始数据获取模块持久化存储;2、通过服务端流量录制,由agent传回至原始数据获取模块,处理后做持久化存储
2)数据预处理
针对API管理平台获取数据中的空数据做缺失值处理
3)特征创造
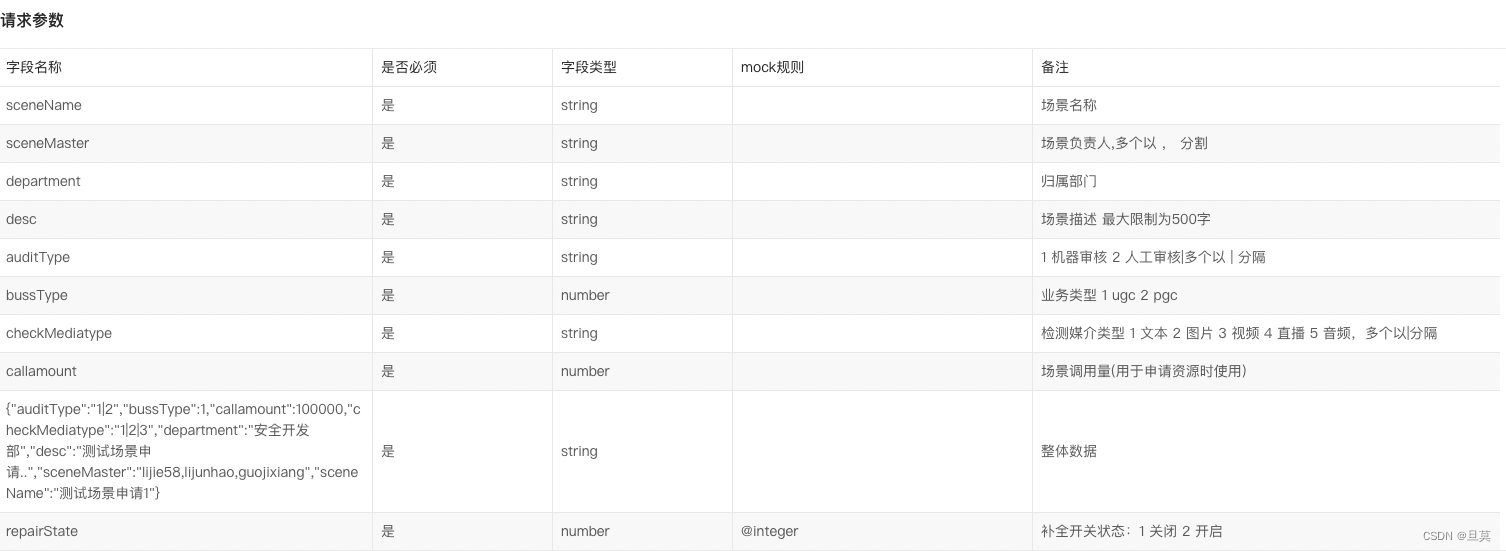
通过原始数据获取模块的第一种数据采集来源我们可以得到如上表示例的接口信息数据,但是这样的文本内容数据无法很好地直接作为训练样本使用,需要做一定的处理。
在特征创造部分,主要针对请求参数进行处理,根据请求参数的属性以及实际数据的关系,我们可以做如下转化。
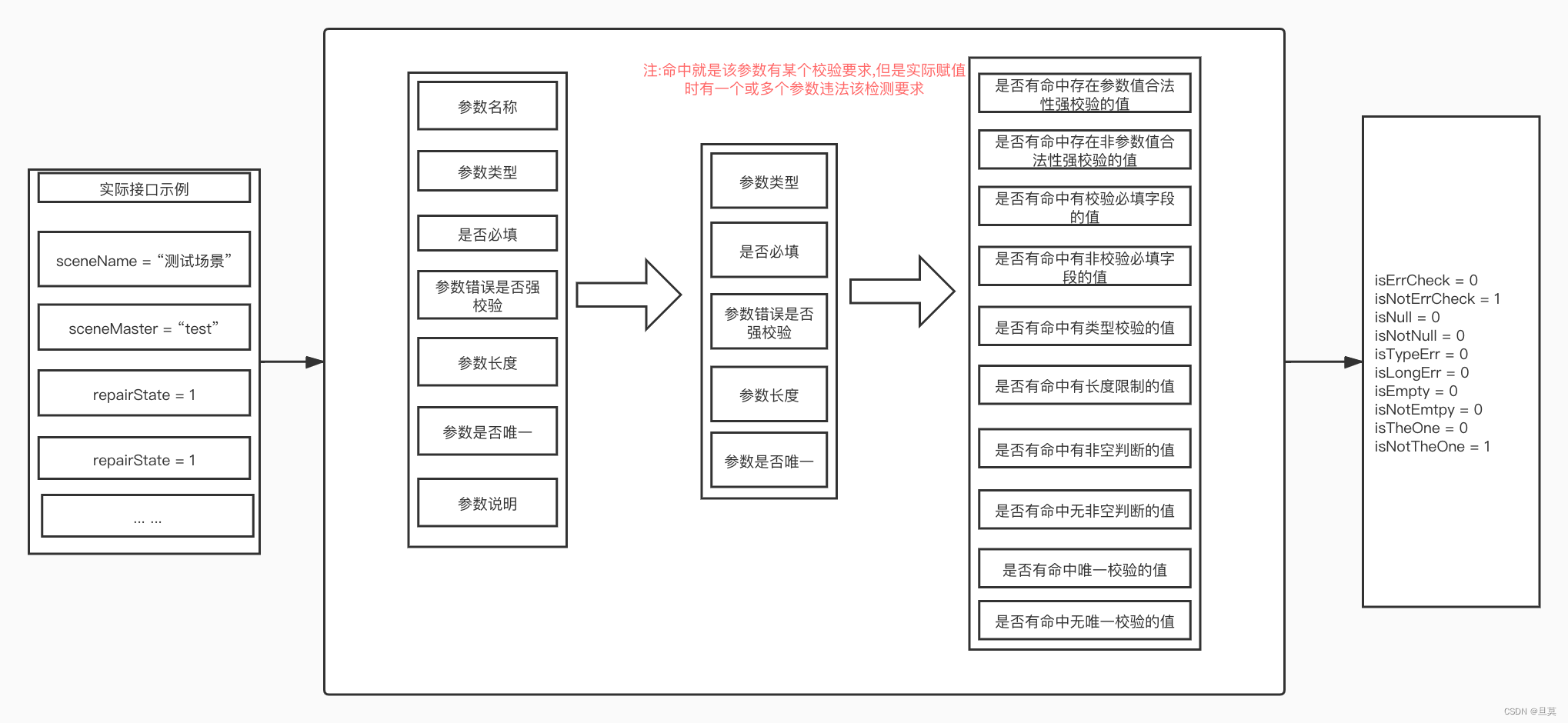
在实际样特征据编写时,为下图所示:
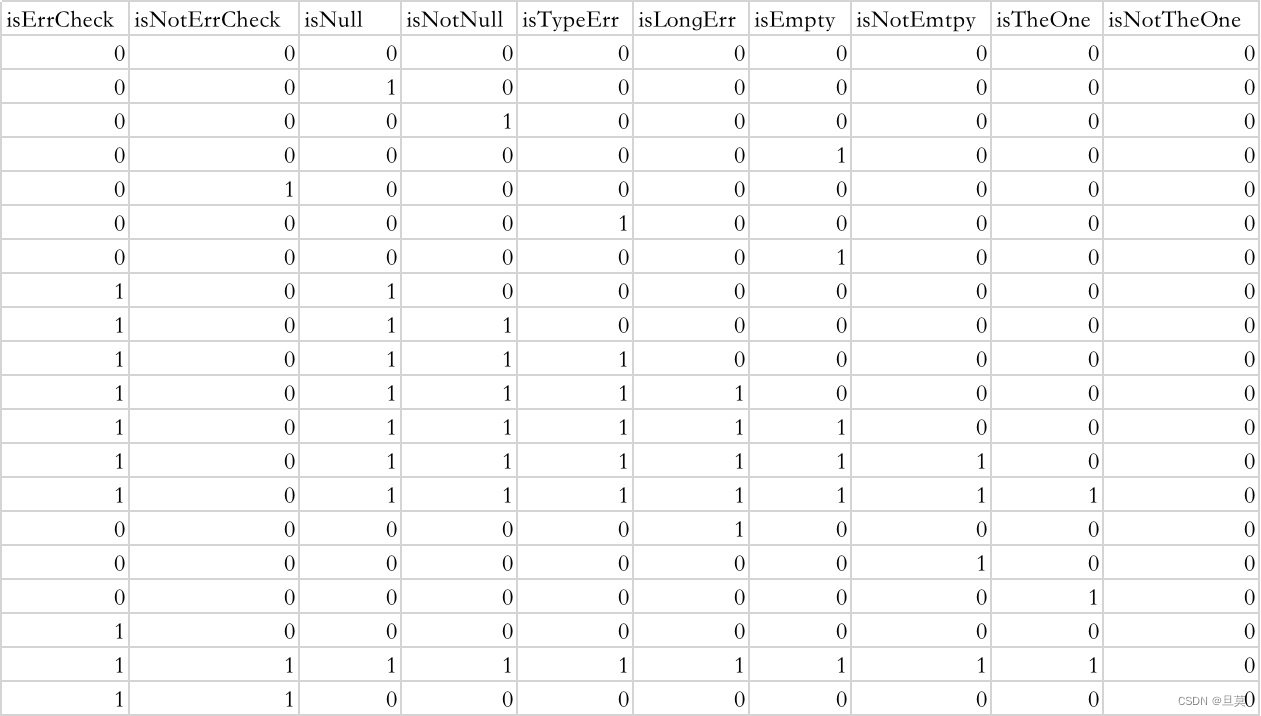
4)特征选择
通过(3、特征创造)中的表格可以看出,可用特征数据很多,但是实际模型训练中,由于特征重要性的因素存在,所以并不是每个参与训练的特征数据都被用到,即便是用到了,权重也不都是非常均衡(有些占比极低)。所以结合我们问题的实际场景以及sklearn提供的模型训练特征重要性接口,从所有原始数据中选出请求参数分组的:参数类型、是否必填、参数错误是否强校验、参数长度、参数是否唯一作为基本特征。
通过sklearn的api获取训练后特征的重要性权重,以此来过滤低重要性的特征。
5)样本数据构造
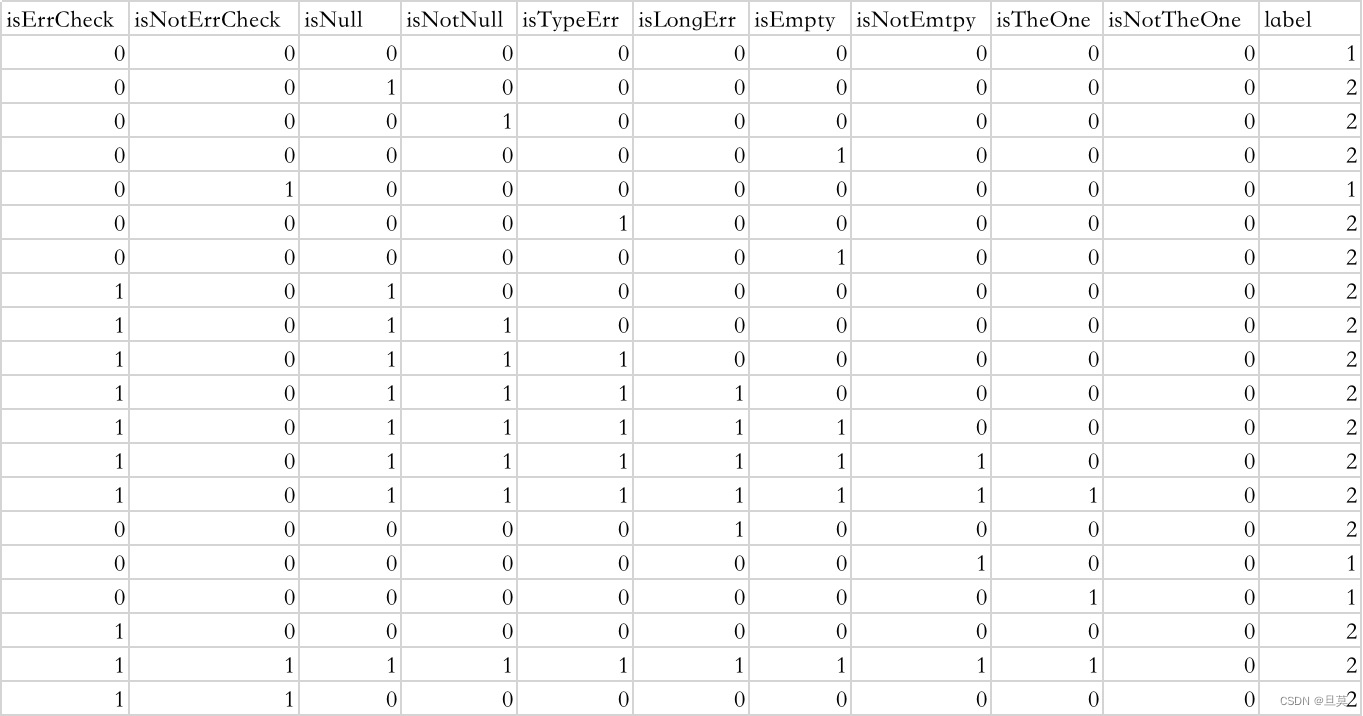
5.3.5.3 训练模型
1)调参
控制基评估器的参数
| 参数 | 含义 |
| criterion | 不纯度的衡量指标,有基尼系数和信息熵两种选择 |
| max_depth | 树的最大深度,超过最大深度的树枝都会被剪掉 |
| min_samples_leaf | 一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生 |
| min_samples_split | 一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生 |
| max_features | max_features限制分枝时考虑的特征个数,超过限制个数的特征都会被舍弃,默认值为总特征个数开平方取整 |
| min_impurity_decrease | 限制信息增益的大小,信息增益小于设定数值的分枝不会发生 |
n_estimators:基评估器数量,即森林中树木的数量。这个参数对随机森林模型的精确性影响是单调的,n_estimators 越大,模型的效果往往越好。但是相应的,任何模型都有决策边界,n_estimators达到一定的程度之后,随机森林 的精确性往往不在上升或开始波动,并且,n_estimators越大,需要的计算量和内存也越大,训练的时间也会越来 越长。对于这个参数,我们是渴望在训练难度和模型效果之间取得平衡,如图所示使用demo数据的n_estimators在0~200范围内的学习曲线(X轴:n_estimators取值,Y轴:模型分数)
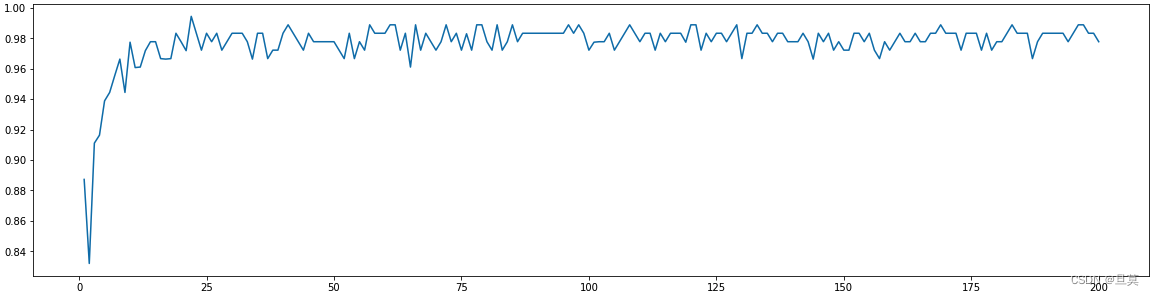
如单一参数调整可以使模型达到预期效果则不需要考虑其他基评估器参数,如果无法达到要求继续调整。参数影响程度优先级:
n_estimators > max_depth > min_samples_leaf = min_samples_split > max_features
2)评估
5.3.5.4 部署上线
Flask提供模型服务 or 打包模型Java调用
目前项目一期已落地,更多内容欢迎大家私信沟通交流 。
登录后可发表评论
点击登录