在这篇文章中,我们将分享7个Python爬虫的小案例,帮助大家更好地学习和了解Python爬虫的基础知识。以下是每个案例的简介和源代码:
1. 爬取豆瓣电影Top250
这个案例使用BeautifulSoup库爬取豆瓣电影Top250的电影名称、评分和评价人数等信息,并将这些信息保存到CSV文件中。
import requestsfrom bs4 import BeautifulSoupimport csv# 请求URLurl = '<https://movie.douban.com/top250>'# 请求头部headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}# 解析页面函数def parse_html(html): soup = BeautifulSoup(html, 'lxml') movie_list = soup.find('ol', class_='grid_view').find_all('li') for movie in movie_list: title = movie.find('div', class_='hd').find('span', class_='title').get_text() rating_num = movie.find('div', class_='star').find('span', class_='rating_num').get_text() comment_num = movie.find('div', class_='star').find_all('span')[-1].get_text() writer.writerow([title, rating_num, comment_num])# 保存数据函数def save_data(): f = open('douban_movie_top250.csv', 'a', newline='', encoding='utf-8-sig') global writer writer = csv.writer(f) writer.writerow(['电影名称', '评分', '评价人数']) for i in range(10): url = '<https://movie.douban.com/top250?start=>' + str(i*25) + '&filter=' response = requests.get(url, headers=headers) parse_html(response.text) f.close()if __name__ == '__main__': save_data()2. 爬取猫眼电影Top100
这个案例使用正则表达式和requests库爬取猫眼电影Top100的电影名称、主演和上映时间等信息,并将这些信息保存到TXT文件中。
import requestsimport re# 请求URLurl = '<https://maoyan.com/board/4>'# 请求头部headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}# 解析页面函数def parse_html(html): pattern = re.compile('<p class="name"><a href=".*?" title="(.*?)" data-act="boarditem-click" data-val="{movieId:\\\\d+}">(.*?)</a></p>.*?<p class="star">(.*?)</p>.*?<p class="releasetime">(.*?)</p>', re.S) items = re.findall(pattern, html) for item in items: yield { '电影名称': item[1], '主演': item[2].strip(), '上映时间': item[3] }# 保存数据函数def save_data(): f = open('maoyan_top100.txt', 'w', encoding='utf-8') for i in range(10): url = '<https://maoyan.com/board/4?offset=>' + str(i*10) response = requests.get(url, headers=headers) for item in parse_html(response.text): f.write(str(item) + '\\\\n') f.close()if __name__ == '__main__': save_data()3. 爬取全国高校名单
这个案例使用正则表达式和requests库爬取全国高校名单,并将这些信息保存到TXT文件中。
import requestsimport re# 请求URLurl = '<http://www.zuihaodaxue.com/zuihaodaxuepaiming2019.html>'# 请求头部headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}# 解析页面函数def parse_html(html): pattern = re.compile('<tr class="alt">.*?<td>(.*?)</td>.*?<td><div align="left">.*?<a href="(.*?)" target="_blank">(.*?)</a></div></td>.*?<td>(.*?)</td>.*?<td>(.*?)</td>.*?</tr>', re.S) items = re.findall(pattern, html) for item in items: yield { '排名': item[0], '学校名称': item[2], '省市': item[3], '总分': item[4] }# 保存数据函数def save_data(): f = open('university_top100.txt', 'w', encoding='utf-8') response = requests.get(url, headers=headers) for item in parse_html(response.text): f.write(str(item) + '\\\\n') f.close()if __name__ == '__main__': save_data()4. 爬取中国天气网城市天气
这个案例使用xpath和requests库爬取中国天气网的城市天气,并将这些信息保存到CSV文件中。
import requestsfrom lxml import etreeimport csv# 请求URLurl = '<http://www.weather.com.cn/weather1d/101010100.shtml>'# 请求头部headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}# 解析页面函数def parse_html(html): selector = etree.HTML(html) city = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/h1/text()')[0] temperature = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/i/text()')[0] weather = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/@title')[0] wind = selector.xpath('//*[@id="around"]/div/div[1]/div[1]/p/span/text()')[0] return city, temperature, weather, wind# 保存数据函数def save_data(): f = open('beijing_weather.csv', 'w', newline='', encoding='utf-8-sig') writer = csv.writer(f) writer.writerow(['城市', '温度', '天气', '风力']) for i in range(10): response = requests.get(url, headers=headers) city, temperature, weather, wind = parse_html(response.text) writer.writerow([city, temperature, weather, wind]) f.close()if __name__ == '__main__': save_data()5. 爬取当当网图书信息
这个案例使用xpath和requests库爬取当当网图书信息,并将这些信息保存到CSV文件中。
import requestsfrom lxml import etreeimport csv# 请求URLurl = '<http://search.dangdang.com/?key=Python&act=input>'# 请求头部headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}# 解析页面函数def parse_html(html): selector = etree.HTML(html) book_list = selector.xpath('//*[@id="search_nature_rg"]/ul/li') for book in book_list: title = book.xpath('a/@title')[0] link = book.xpath('a/@href')[0] price = book.xpath('p[@class="price"]/span[@class="search_now_price"]/text()')[0] author = book.xpath('p[@class="search_book_author"]/span[1]/a/@title')[0] publish_date = book.xpath('p[@class="search_book_author"]/span[2]/text()')[0] publisher = book.xpath('p[@class="search_book_author"]/span[3]/a/@title')[0] yield { '书名': title, '链接': link, '价格': price, '作者': author, '出版日期': publish_date, '出版社': publisher }# 保存数据函数def save_data(): f = open('dangdang_books.csv', 'w', newline='', encoding='utf-8-sig') writer = csv.writer(f) writer.writerow(['书名', '链接', '价格', '作者', '出版日期', '出版社']) response = requests.get(url, headers=headers) for item in parse_html(response.text): writer.writerow(item.values()) f.close()if __name__ == '__main__': save_data()6. 爬取糗事百科段子
这个案例使用xpath和requests库爬取糗事百科的段子,并将这些信息保存到TXT文件中。
import requestsfrom lxml import etree# 请求URLurl = '<https://www.qiushibaike.com/text/>'# 请求头部headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}# 解析页面函数def parse_html(html): selector = etree.HTML(html) content_list = selector.xpath('//div[@class="content"]/span/text()') for content in content_list: yield content# 保存数据函数def save_data(): f = open('qiushibaike_jokes.txt', 'w', encoding='utf-8') for i in range(3): url = '<https://www.qiushibaike.com/text/page/>' + str(i+1) + '/' response = requests.get(url, headers=headers) for content in parse_html(response.text): f.write(content + '\\\\n') f.close()if __name__ == '__main__': save_data()7. 爬取新浪微博
这个案例使用selenium和requests库爬取新浪微博,并将这些信息保存到TXT文件中。
import timefrom selenium import webdriverimport requests# 请求URLurl = '<https://weibo.com/>'# 请求头部headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'}# 解析页面函数def parse_html(html): print(html)# 保存数据函数def save_data(): f = open('weibo.txt', 'w', encoding='utf-8') browser = webdriver.Chrome() browser.get(url) time.sleep(10) browser.find_element_by_name('username').send_keys('username') browser.find_element_by_name('password').send_keys('password') browser.find_element_by_class_name('W_btn_a').click() time.sleep(10) response = requests.get(url, headers=headers, cookies=browser.get_cookies()) parse_html(response.text) browser.close() f.close()if __name__ == '__main__': save_data()希望这7个小案例能够帮助大家更好地掌握Python爬虫的基础知识!
关于Python学习指南
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后给大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
包括:Python激活码+安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。让你从零基础系统性的学好Python!
?Python所有方向的学习路线?
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。(全套教程文末领取)
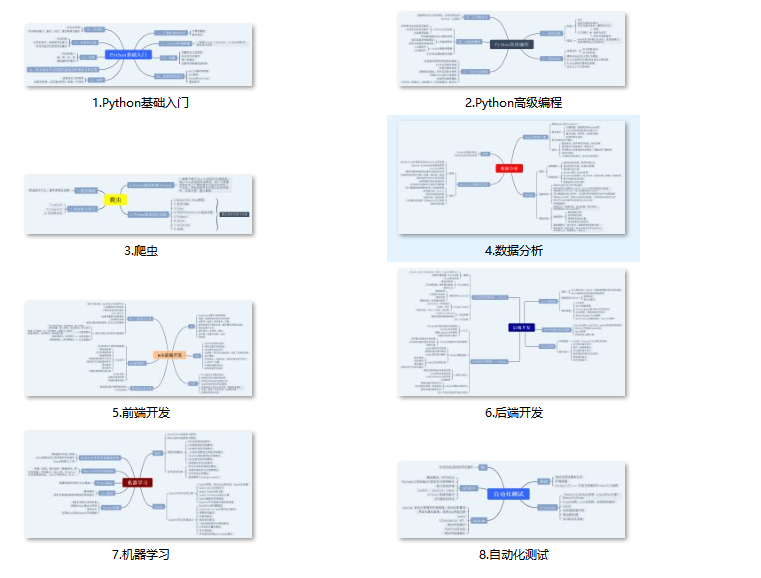
?Python学习视频600合集?
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
温馨提示:篇幅有限,已打包文件夹,获取方式在:文末
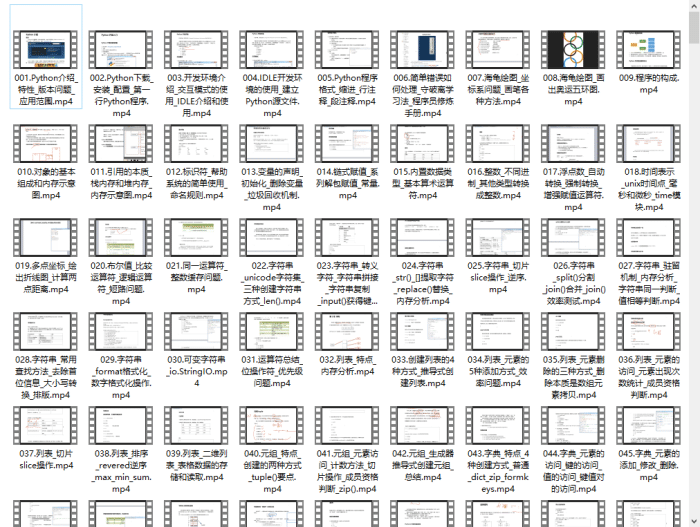
?Python70个实战练手案例&源码?
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

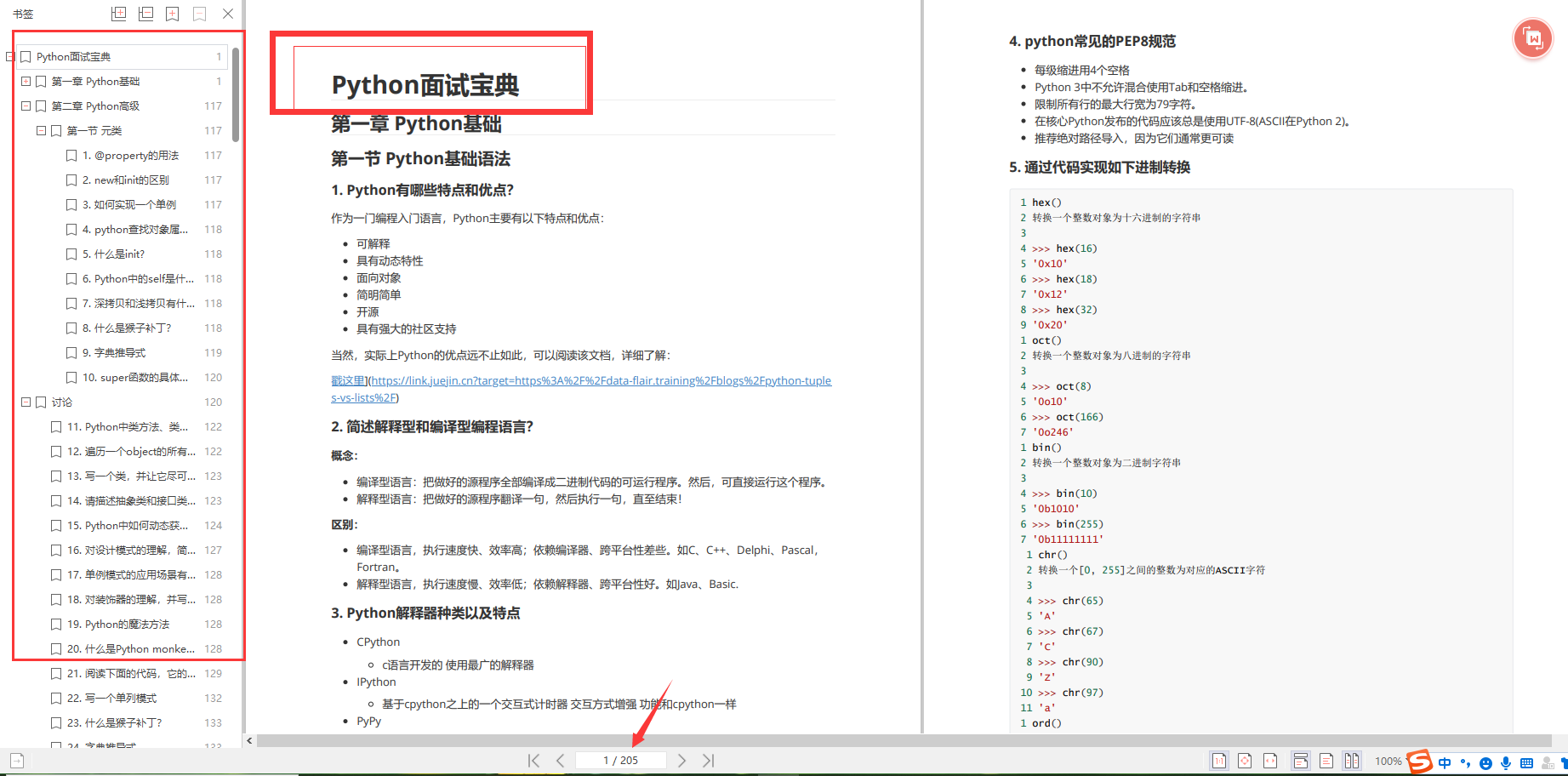
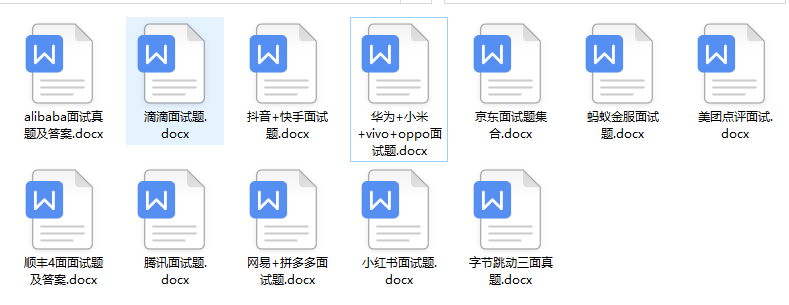
?Python大厂面试资料?
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
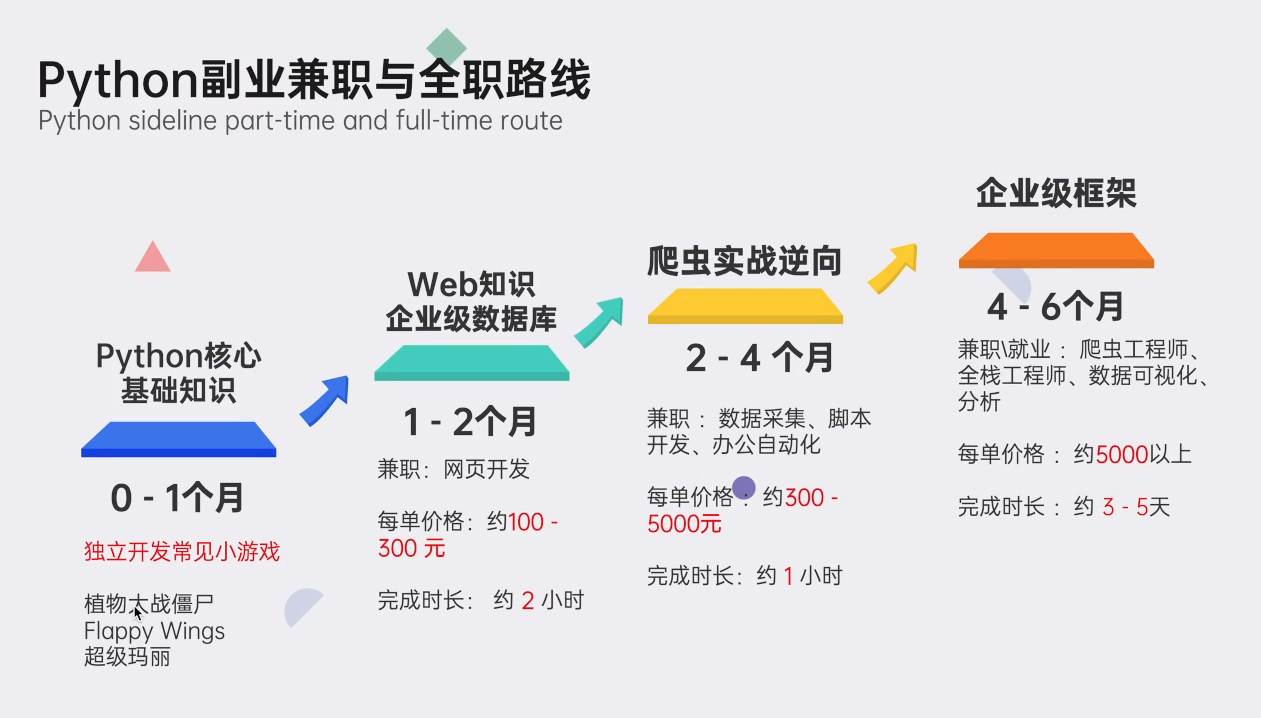
?Python副业兼职路线&方法?
学好 Python 不论是就业还是做副业赚钱都不错,但要学会兼职接单还是要有一个学习规划。
? 这份完整版的Python全套学习资料已经上传,朋友们如果需要可以扫描下方CSDN官方认证二维码或者点击链接免费领取【保证100%免费】
点击免费领取《CSDN大礼包》:Python入门到进阶资料 & 实战源码 & 兼职接单方法 安全链接免费领取
