












MindSpore 全场景的几个重要特性: 1、端边云统一的C++ 推理接口,支持算法代码可快速迁移到不同硬件环境执行。
2、模型统一,端云使用相同的模型格式和定义,软件架构一致。MindSpore 支持 Ascend、 GPU 、 CPU ( x86 、 arm 、 … )等多种硬件的执行,一次训练多处部署 使用。 3、多样化算力支持。提供统一的南向接口,支持新硬件的快捷添加使用。 4、模型小型化技术,适配不同硬件环境和业务场景的要求,如量化等。以及端边 云协同技术的快速应用,如联邦学习等技术。 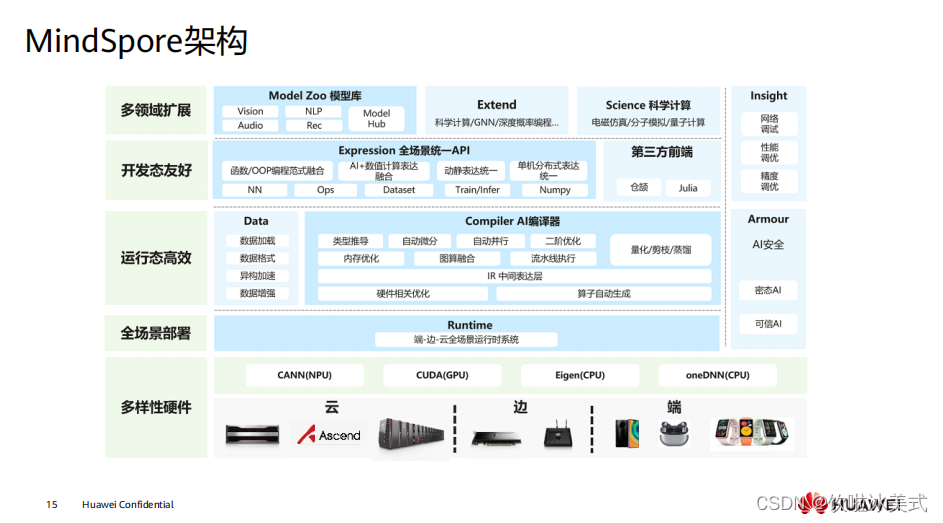 MindSpore 整体架构分为四层: 1、模型层,为用户提供开箱即用的功能,该层主要包含预置的模型和开发套件, 以及图神经网络( GNN )、深度概率编程等热点研究领域拓展库; 2、表达层 (MindExpression ),为用户提供 AI 模型开发、训练、推理的接口,支 持用户用原生 Python 语法开发和调试神经网络,其特有的动静态图统一能力使 开发者可以兼顾开发效率和执行性能,同时该层在生产和部署阶段提供全场景 统一的 C++ 接口; 3、编译优化(MindCompiler ),作为 AI 框架的核心,以全场景统一中间表达 ( MindIR )为媒介,将前端表达编译成执行效率更高的底层语言,同时进行全 局性能优化,包括自动微分、代数化简等硬件无关优化,以及图算融合、算子 生成等硬件相关优化; 4、运行时,按照上层编译优化的结果对接并调用底层硬件算子,同时通过“端- 边 - 云”统一的运行时架构,支持包括联邦学习在内的“端 - 边 - 云” AI 协同。
MindSpore 整体架构分为四层: 1、模型层,为用户提供开箱即用的功能,该层主要包含预置的模型和开发套件, 以及图神经网络( GNN )、深度概率编程等热点研究领域拓展库; 2、表达层 (MindExpression ),为用户提供 AI 模型开发、训练、推理的接口,支 持用户用原生 Python 语法开发和调试神经网络,其特有的动静态图统一能力使 开发者可以兼顾开发效率和执行性能,同时该层在生产和部署阶段提供全场景 统一的 C++ 接口; 3、编译优化(MindCompiler ),作为 AI 框架的核心,以全场景统一中间表达 ( MindIR )为媒介,将前端表达编译成执行效率更高的底层语言,同时进行全 局性能优化,包括自动微分、代数化简等硬件无关优化,以及图算融合、算子 生成等硬件相关优化; 4、运行时,按照上层编译优化的结果对接并调用底层硬件算子,同时通过“端- 边 - 云”统一的运行时架构,支持包括联邦学习在内的“端 - 边 - 云” AI 协同。  MindExpression 层次结构。 High-Level Python API : 第一层为高阶 API ,其在中阶 API 的基础上又提供了训练推理的管理、混合精度 训练、调试调优等高级接口,方便用户控制整网的执行流程和实现神经网络的 训练推理及调优。例如用户使用 Model 接口,指定要训练的神经网络模型和相 关的训练设置,对神经网络模型进行训练。 Medium-Level Python API : 第二层为中阶 API ,其封装了低阶 API ,提供网络层、优化器、损失函数等模块, 用户可通过中阶 API 灵活构建神经网络和控制执行流程,快速实现模型算法逻辑。 例如用户可调用 Cell 接口构建神经网络模型和计算逻辑,通过使用 Loss 模块和 Optimizer 接口为神经网络模型添加损失函数和优化方式,利用 Dataset 模块对 数据进行处理以供模型的训练和推导使用。 Low-Level Python API : 第三层为低阶 API ,主要包括张量定义、基础算子、自动微分等模块,用户可使 用低阶 API 轻松实现张量定义和求导计算。例如用户可通过 Tensor 接口自定义张 量,使用 ops.composite 模块下的 GradOperation 算子计算函数在指定处的导数。
MindExpression 层次结构。 High-Level Python API : 第一层为高阶 API ,其在中阶 API 的基础上又提供了训练推理的管理、混合精度 训练、调试调优等高级接口,方便用户控制整网的执行流程和实现神经网络的 训练推理及调优。例如用户使用 Model 接口,指定要训练的神经网络模型和相 关的训练设置,对神经网络模型进行训练。 Medium-Level Python API : 第二层为中阶 API ,其封装了低阶 API ,提供网络层、优化器、损失函数等模块, 用户可通过中阶 API 灵活构建神经网络和控制执行流程,快速实现模型算法逻辑。 例如用户可调用 Cell 接口构建神经网络模型和计算逻辑,通过使用 Loss 模块和 Optimizer 接口为神经网络模型添加损失函数和优化方式,利用 Dataset 模块对 数据进行处理以供模型的训练和推导使用。 Low-Level Python API : 第三层为低阶 API ,主要包括张量定义、基础算子、自动微分等模块,用户可使 用低阶 API 轻松实现张量定义和求导计算。例如用户可通过 Tensor 接口自定义张 量,使用 ops.composite 模块下的 GradOperation 算子计算函数在指定处的导数。 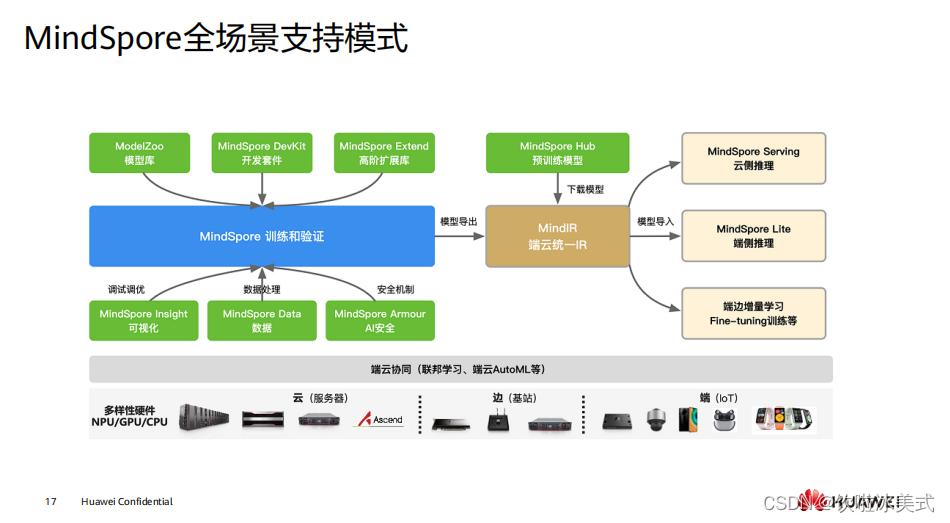 MindSpore 作为全场景 AI 框架,所支持的有端(手机与 IOT 设备)、边(基站与路由 设备)、云(服务器)场景的不同系列硬件,包括 昇 腾系列产品、英伟达 NVIDIA 系 列产品、 Arm 系列的高通骁龙、华为麒麟的芯片等系列产品。 左边蓝色方框的是 MindSpore 主体框架,主要提供神经网络在训练、验证相关的基础 API 功能,另外还会默认提供自动微分、自动并行等功能。 蓝色方框往下是 MindSpore Data 模块,可以利用该模块进行数据预处理,包括数据 采样、数据迭代、数据格式转换等不同的数据操作。在训练的过程会遇到很多调试调 优的问题,因此有 MindSpore Insight 模块对 loss 曲线、算子执行情况、权重参数变量 等调试调优相关的数据进行可视化,方便用户在训练过程中进行调试调优。 AI 安全最简单的方式就是从攻防的视角来看,例如,攻击者在训练阶段掺入恶意数据, 影响 AI 模型推理能力,于是 MindSpore 推出了 MindSpore Armour 模块,为 MindSpore 提供 AI 安全机制。 蓝色方框往上的内容跟算法开发相关的用户更加贴近,包括存放大量的 AI 算法模型库 ModelZoo ,提供面向不同领域的开发工具套件 MindSpore DevKit ,另外还有高阶拓 展库 MindSpore Extend ,这里面值得一提的就是 MindSpore Extend 中的科学计算套 件 MindSciences , MindSpore 首次探索将科学计算与深度学习结合,将数值计算与深 度学习相结合,通过深度学习来支持电磁仿真、药物分子仿真等等。 神经网络模型训练完后,可以导出模型或者加载存放在 MindSpore Hub 中已经训练好 的模型。接着有 MindIR 提供端云统一的 IR 格式,通过统一 IR 定义了网络的逻辑结构和 算子的属性,将 MindIR 格式的模型文件 与硬件平台解耦,实现一次训练多次部署。 因此如图所示,通过 IR 把模型导出到不同的模块执行推理。
MindSpore 作为全场景 AI 框架,所支持的有端(手机与 IOT 设备)、边(基站与路由 设备)、云(服务器)场景的不同系列硬件,包括 昇 腾系列产品、英伟达 NVIDIA 系 列产品、 Arm 系列的高通骁龙、华为麒麟的芯片等系列产品。 左边蓝色方框的是 MindSpore 主体框架,主要提供神经网络在训练、验证相关的基础 API 功能,另外还会默认提供自动微分、自动并行等功能。 蓝色方框往下是 MindSpore Data 模块,可以利用该模块进行数据预处理,包括数据 采样、数据迭代、数据格式转换等不同的数据操作。在训练的过程会遇到很多调试调 优的问题,因此有 MindSpore Insight 模块对 loss 曲线、算子执行情况、权重参数变量 等调试调优相关的数据进行可视化,方便用户在训练过程中进行调试调优。 AI 安全最简单的方式就是从攻防的视角来看,例如,攻击者在训练阶段掺入恶意数据, 影响 AI 模型推理能力,于是 MindSpore 推出了 MindSpore Armour 模块,为 MindSpore 提供 AI 安全机制。 蓝色方框往上的内容跟算法开发相关的用户更加贴近,包括存放大量的 AI 算法模型库 ModelZoo ,提供面向不同领域的开发工具套件 MindSpore DevKit ,另外还有高阶拓 展库 MindSpore Extend ,这里面值得一提的就是 MindSpore Extend 中的科学计算套 件 MindSciences , MindSpore 首次探索将科学计算与深度学习结合,将数值计算与深 度学习相结合,通过深度学习来支持电磁仿真、药物分子仿真等等。 神经网络模型训练完后,可以导出模型或者加载存放在 MindSpore Hub 中已经训练好 的模型。接着有 MindIR 提供端云统一的 IR 格式,通过统一 IR 定义了网络的逻辑结构和 算子的属性,将 MindIR 格式的模型文件 与硬件平台解耦,实现一次训练多次部署。 因此如图所示,通过 IR 把模型导出到不同的模块执行推理。 



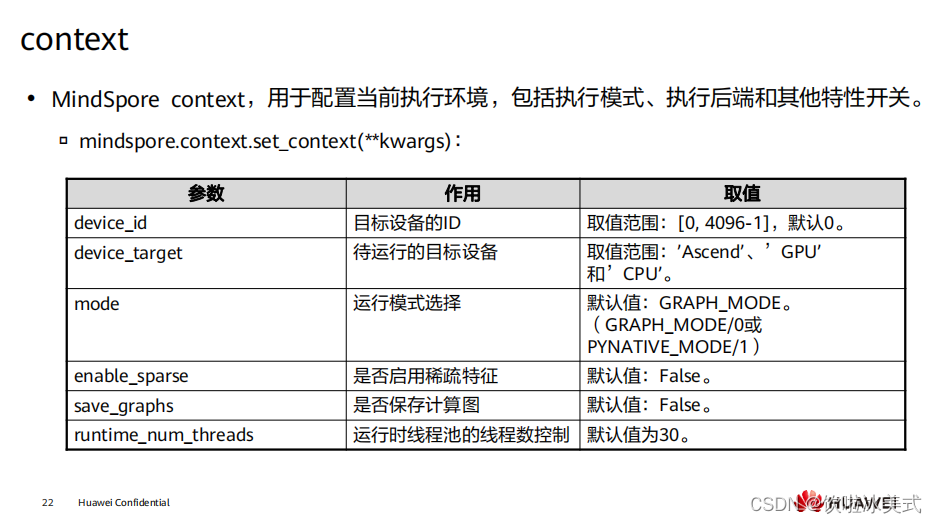 在运行程序之前,应配置 context 。如果没有配置,默认情况下将根据设备目标进行 自动设置。
在运行程序之前,应配置 context 。如果没有配置,默认情况下将根据设备目标进行 自动设置。 
 其中数据文件包含文件头、标量数据页、块数据页,用于存储用户归一化后的训练数 据,且单个 MindSpore Record 文件建议小于 20G ,用户可将大数据集进行分片存储为 多个 MindSpore Record 文件。而索引文件则包含基于标量数据(如图像 Label 、图像 文件名等)生成的索引信息,用于方便的检索、统计数据集信息。数据文件中的文件 头、标量数据页、块数据页的具体用途如下所示: 文件头 :是 MindSpore Record 文件的元信息,主要用来存储文件头大小、标量 数据页大小、块数据页大小、 Schema 信息、索引字段、统计信息、文件分区信 息、标量数据与块数据对应关系等。 标量数据页 :主要用来存储整型、字符串、浮点型数据,如图像的 Label 、图像 的文件名、图像的长宽等信息,即适合用标量来存储的信息会保存在这里。 块数据页 :主要用来存储二进制串、 NumPy 数组等数据,如二进制图像文件本 身、文本转换成的字典等。 MindSpore Record 数据格式具备的特征如下: 1、实现数据统一存储、访问,使得训练时数据读取更加简便。 2、数据聚合存储、高效读取,使得训练时数据方便管理和移动。 3、高效的数据编解码操作,使得用户可以对数据操作无感知。 4、可以灵活控制数据切分的分区大小,实现分布式数据处理。
其中数据文件包含文件头、标量数据页、块数据页,用于存储用户归一化后的训练数 据,且单个 MindSpore Record 文件建议小于 20G ,用户可将大数据集进行分片存储为 多个 MindSpore Record 文件。而索引文件则包含基于标量数据(如图像 Label 、图像 文件名等)生成的索引信息,用于方便的检索、统计数据集信息。数据文件中的文件 头、标量数据页、块数据页的具体用途如下所示: 文件头 :是 MindSpore Record 文件的元信息,主要用来存储文件头大小、标量 数据页大小、块数据页大小、 Schema 信息、索引字段、统计信息、文件分区信 息、标量数据与块数据对应关系等。 标量数据页 :主要用来存储整型、字符串、浮点型数据,如图像的 Label 、图像 的文件名、图像的长宽等信息,即适合用标量来存储的信息会保存在这里。 块数据页 :主要用来存储二进制串、 NumPy 数组等数据,如二进制图像文件本 身、文本转换成的字典等。 MindSpore Record 数据格式具备的特征如下: 1、实现数据统一存储、访问,使得训练时数据读取更加简便。 2、数据聚合存储、高效读取,使得训练时数据方便管理和移动。 3、高效的数据编解码操作,使得用户可以对数据操作无感知。 4、可以灵活控制数据切分的分区大小,实现分布式数据处理。 




 静态图模式比较适合网络固定且需要高性能的场景。在静态图模式下,基于图优化、 计算图整图下沉等技术,编译器可以针对图进行全局的优化,因此在静态图下能获得 较好的性能,但是执行图是从源码转换而来,因此在静态图下不是所有的 Python 语法 都能支持。 nn.Cell 类,是构建所有网络的基类,也是网络的基本单元,定义网络结构是需要继承 该类,具体使用可以参考课程后面的应用案例部分。 ms_function 是 MindSpore 中提供的用于加速动态图执行效率的工具。
静态图模式比较适合网络固定且需要高性能的场景。在静态图模式下,基于图优化、 计算图整图下沉等技术,编译器可以针对图进行全局的优化,因此在静态图下能获得 较好的性能,但是执行图是从源码转换而来,因此在静态图下不是所有的 Python 语法 都能支持。 nn.Cell 类,是构建所有网络的基类,也是网络的基本单元,定义网络结构是需要继承 该类,具体使用可以参考课程后面的应用案例部分。 ms_function 是 MindSpore 中提供的用于加速动态图执行效率的工具。 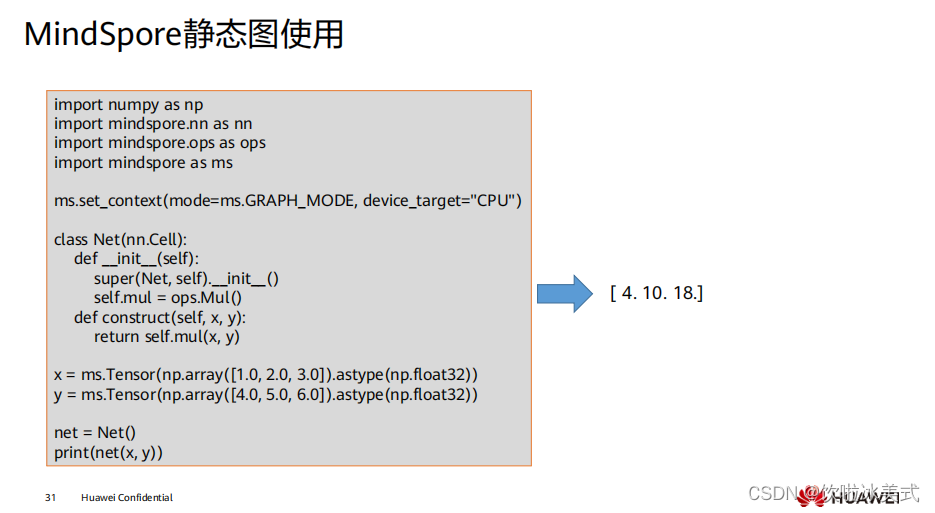
 通过前端的 Python API ,调用到框架层,最终到相应的硬件设备上进行计算。 在 PyNative 下执行正向过程完全是按照 Python 的语法进行执行。 拓展:在 PyNative 下是基于 Tensor 进行实现反向传播的,我们在执行正向过程中,将 所有应用于 Tensor 的操作记录下来,并针对每个操作求取其反向,并将所有反向过程 串联起来形成整体反向传播图(简称反向图)。最终,将反向图在设备上进行执行计 算出梯度。
通过前端的 Python API ,调用到框架层,最终到相应的硬件设备上进行计算。 在 PyNative 下执行正向过程完全是按照 Python 的语法进行执行。 拓展:在 PyNative 下是基于 Tensor 进行实现反向传播的,我们在执行正向过程中,将 所有应用于 Tensor 的操作记录下来,并针对每个操作求取其反向,并将所有反向过程 串联起来形成整体反向传播图(简称反向图)。最终,将反向图在设备上进行执行计 算出梯度。 
 在 MindSpore 中,我们可以通过控制模式输入参数来切换执行使用动态图还是静态图。 但是,由于在静态图下,对于 Python 语法有所限制,因此从动态图切换成静态图时, 需要符合静态图的语法限制,才能正确使用静态图来进行执行。
在 MindSpore 中,我们可以通过控制模式输入参数来切换执行使用动态图还是静态图。 但是,由于在静态图下,对于 Python 语法有所限制,因此从动态图切换成静态图时, 需要符合静态图的语法限制,才能正确使用静态图来进行执行。  MindIR 是 MindSpore 提供的中间表达形式,可以帮助大家实现一次训练多处部署,实 现端云互通。简单来说,就是你可以在 Ascend 、 GPU 、 CPU 硬件平台上训练生成 MindIR 格式的模型,然后快速部署到手机端、推理服务器等环境上,体验到 MindSpore 的全场景能力。 MindIR 通过统一的算子 IR 定义,消除了不同后端的模型差异,大家可以基于同一个模 型文件在端、边、云不同平台上进行协同任务。 中间表示 ( intermediate representation , IR) 指编译器对于源程序进行扫描后生成 的内部表示,代表源程序的语义和语法结构,编译器的各个阶段都在 IR 上进行分析或 优化变换,因而它对编译器的整体结构、效率和健壮性都有着极大的影响。中间表示 对提高编译器的可移植性以及代码生成起到关键作用,在编译器的研究中,应该设计 一种结构良好的中间表示,这种中间表示应在适当的抽象层次上,向上能支持多语言 的映射,向下能适应多平台转换且易于进行各种优化
MindIR 是 MindSpore 提供的中间表达形式,可以帮助大家实现一次训练多处部署,实 现端云互通。简单来说,就是你可以在 Ascend 、 GPU 、 CPU 硬件平台上训练生成 MindIR 格式的模型,然后快速部署到手机端、推理服务器等环境上,体验到 MindSpore 的全场景能力。 MindIR 通过统一的算子 IR 定义,消除了不同后端的模型差异,大家可以基于同一个模 型文件在端、边、云不同平台上进行协同任务。 中间表示 ( intermediate representation , IR) 指编译器对于源程序进行扫描后生成 的内部表示,代表源程序的语义和语法结构,编译器的各个阶段都在 IR 上进行分析或 优化变换,因而它对编译器的整体结构、效率和健壮性都有着极大的影响。中间表示 对提高编译器的可移植性以及代码生成起到关键作用,在编译器的研究中,应该设计 一种结构良好的中间表示,这种中间表示应在适当的抽象层次上,向上能支持多语言 的映射,向下能适应多平台转换且易于进行各种优化 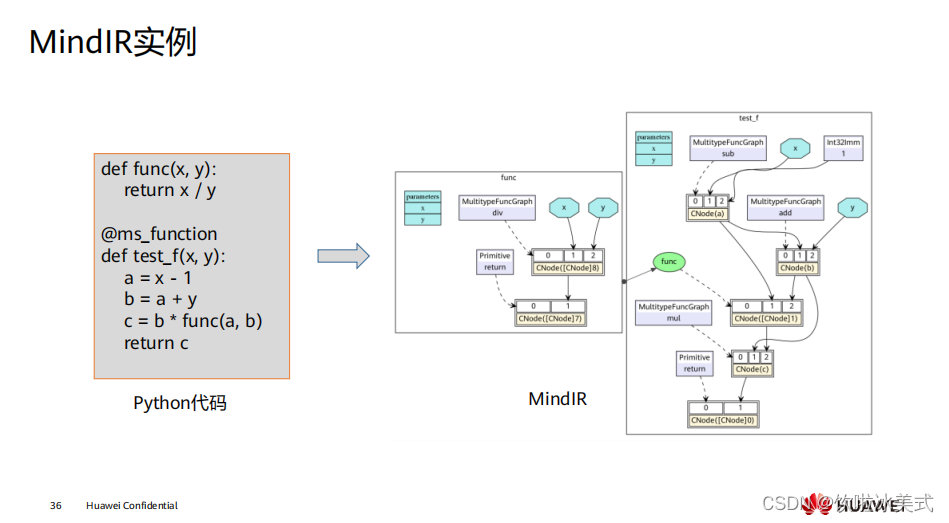 打开 MindIR ,它是一种基于图表示的函数式 IR ,定义了可扩展的图结构以及算子的 IR 表示,它存储了 MindSpore 基础数据结构,包括计算图、参数权重等。
打开 MindIR ,它是一种基于图表示的函数式 IR ,定义了可扩展的图结构以及算子的 IR 表示,它存储了 MindSpore 基础数据结构,包括计算图、参数权重等。  计算流程: 用户设置网络执行的后端(device ); 用户设置特定算子执行后端; 框架根据计算图算子标志进行切图。 框架调度不同后端执行子图。 当前典型使用异构并行计算的场景有:优化器异构、 Embedding 异构、 PS 异构
计算流程: 用户设置网络执行的后端(device ); 用户设置特定算子执行后端; 框架根据计算图算子标志进行切图。 框架调度不同后端执行子图。 当前典型使用异构并行计算的场景有:优化器异构、 Embedding 异构、 PS 异构 
 MindSpore 抽象各个硬件下的统一算子接口,因此,在不同硬件环境下,网络模型的 编程代码可以保持一致。同时加载相同的模型文件,在 MindSpore 支持的各个不同硬 件上均能有效执行推理。 推理考虑到大量用户使用 C++/C 编程方式,因此提供了 C++ 的推理编程接口,相关编程接口在形态上与 Python 接口的风格较接近。
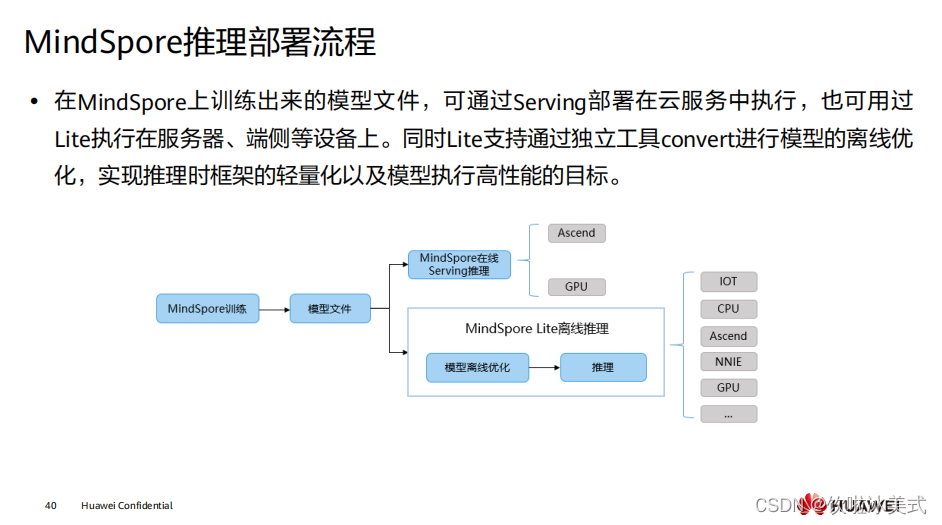
MindSpore 抽象各个硬件下的统一算子接口,因此,在不同硬件环境下,网络模型的 编程代码可以保持一致。同时加载相同的模型文件,在 MindSpore 支持的各个不同硬 件上均能有效执行推理。 推理考虑到大量用户使用 C++/C 编程方式,因此提供了 C++ 的推理编程接口,相关编程接口在形态上与 Python 接口的风格较接近。 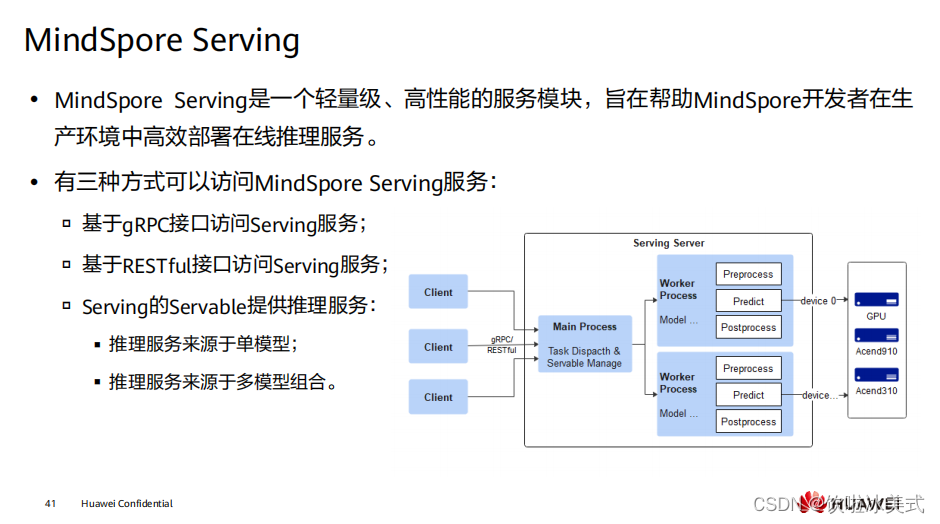
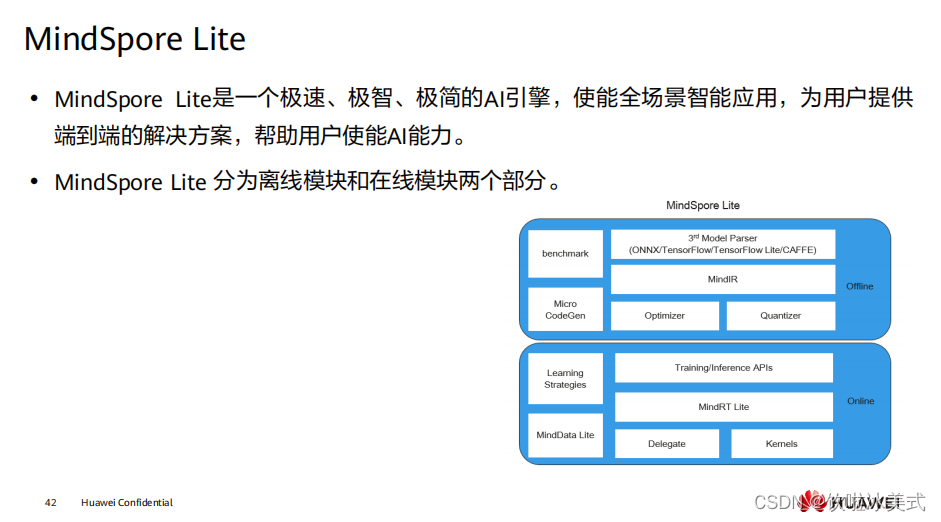 离线模块: 3rd Model Parsers: 将第三方模型转换为统一的 MindIR ,其中第三方模型包括 TensorFlow、 TensorFlow Lite 、 Caffe 1.0 和 ONNX 模型。 MindIR: MindSpore端云统一的 IR 。 Optimizer: 基于 IR 进行图优化,如算子融合、常量折叠等。 Quantizer: 训练后量化模块,支持权重量化、激活值量化等训练后量化手段。 benchmark: 测试性能以及调试精度的工具集。 Micro CodeGen: 针对 IoT 场景,将模型直接编译为可执行文件的工具。 在线模块: Training/Inference APIs: 端云统一的 C++/Java 训练推理接口。 MindRT Lite: 轻量化的在线运行时,支持异步执行。 MindData Lite: 用于端侧数据处理 Delegate: 用于对接专业 AI 硬件引擎的代理。 Kernels: 内置的高性能算子库,提供 CPU 、 GPU 和 NPU 算子。 Learning Strategies: 端侧学习策略,如迁移学习。
离线模块: 3rd Model Parsers: 将第三方模型转换为统一的 MindIR ,其中第三方模型包括 TensorFlow、 TensorFlow Lite 、 Caffe 1.0 和 ONNX 模型。 MindIR: MindSpore端云统一的 IR 。 Optimizer: 基于 IR 进行图优化,如算子融合、常量折叠等。 Quantizer: 训练后量化模块,支持权重量化、激活值量化等训练后量化手段。 benchmark: 测试性能以及调试精度的工具集。 Micro CodeGen: 针对 IoT 场景,将模型直接编译为可执行文件的工具。 在线模块: Training/Inference APIs: 端云统一的 C++/Java 训练推理接口。 MindRT Lite: 轻量化的在线运行时,支持异步执行。 MindData Lite: 用于端侧数据处理 Delegate: 用于对接专业 AI 硬件引擎的代理。 Kernels: 内置的高性能算子库,提供 CPU 、 GPU 和 NPU 算子。 Learning Strategies: 端侧学习策略,如迁移学习。 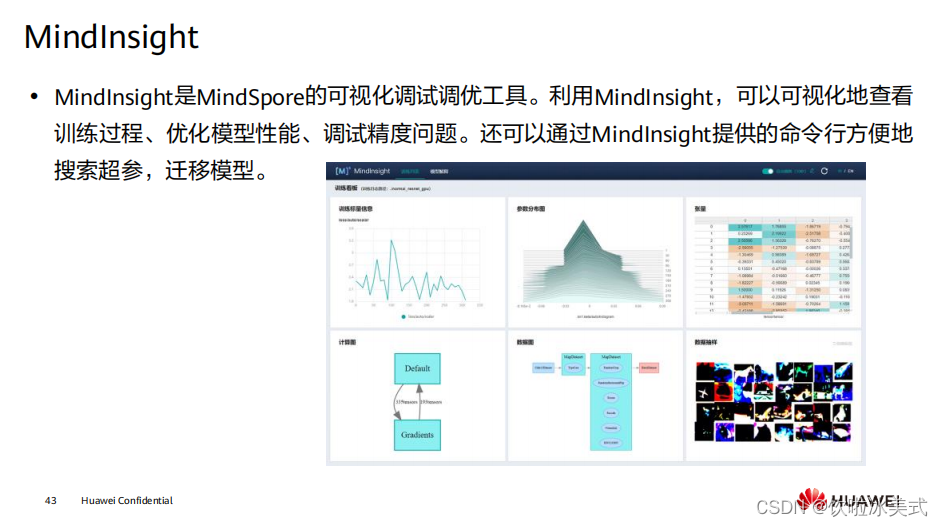 https://www.mindspore.cn/mindinsight/docs/zh-CN/r1.7/index.html
https://www.mindspore.cn/mindinsight/docs/zh-CN/r1.7/index.html 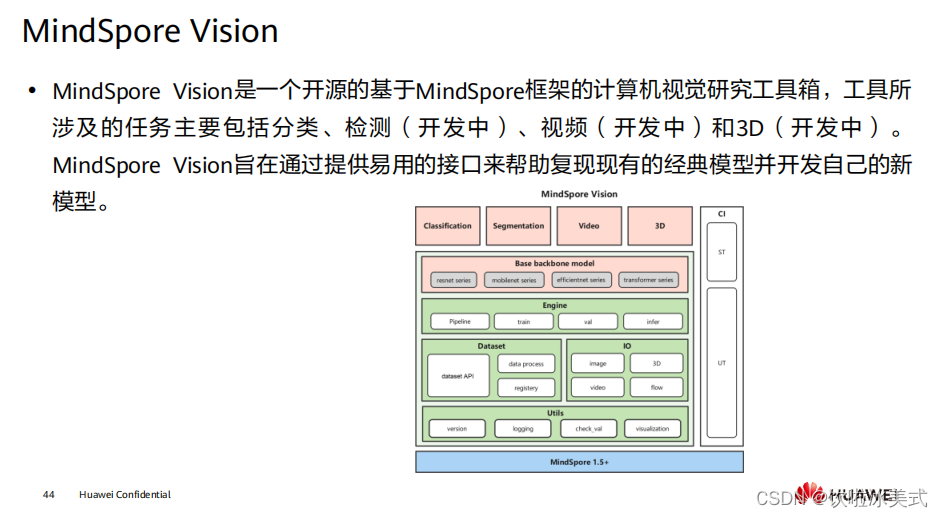 提供的高级功能包括: 分类: 建立在引擎系统上的深层神经网络工作流程。 主干网络: ResNet 和 MobileNet 等模型的基础主干网络。 引擎: 用于模型训练的回调函数。 数据集: 面向各个领域的丰富的数据集接口。 工具: 丰富的可视化接口和 IO( 输入 / 输出 ) 接口。
提供的高级功能包括: 分类: 建立在引擎系统上的深层神经网络工作流程。 主干网络: ResNet 和 MobileNet 等模型的基础主干网络。 引擎: 用于模型训练的回调函数。 数据集: 面向各个领域的丰富的数据集接口。 工具: 丰富的可视化接口和 IO( 输入 / 输出 ) 接口。 

 MindSpore Golden Stick 除了提供丰富的模型压缩算法外,一个重要的设计理念是针 对业界种类繁多的模型压缩算法,提供给用户一个尽可能统一且简洁的体验,降低用 户的算法应用成本。
MindSpore Golden Stick 除了提供丰富的模型压缩算法外,一个重要的设计理念是针 对业界种类繁多的模型压缩算法,提供给用户一个尽可能统一且简洁的体验,降低用 户的算法应用成本。 


 云环境相较于本地环境提供了充足的算力和存储空间,是开发过程中一个较好的选择。
云环境相较于本地环境提供了充足的算力和存储空间,是开发过程中一个较好的选择。 
 此次应用所使用的是开源数据集,所以不需要对数据集本身做太多处理。如果使用的 数据是收集的相关业务数据,还需要对数据做清洗和整理等操作。
此次应用所使用的是开源数据集,所以不需要对数据集本身做太多处理。如果使用的 数据是收集的相关业务数据,还需要对数据做清洗和整理等操作。  mindspore.dataset.vision : 此模块用于图像数据增强,包 括 c_transforms 和 py_transforms 两个子模块。 c_transforms 是使用 C++ OpenCv 开发的高性能图像增强模块。 py_transforms 是使用 Python Pillow 开发的图像增强 模块。 mindspore.dataset.text :此模块用于文本数据增强,包括 transforms 和 utils 两个 子模块。 ▫ transforms 是一个高性能文本数据增强模块,支持常见的文本数据增强处理。 ▫ utils 提供了一些文本处理的工具方法。 mindspore.dataset.audio : 此模块用于音频数据增强,包括 transforms 和 utils 两个 子模块。 transforms 是一个高性能音频数据增强模块,支持常见的音频数据增强操 作。 utils 提供了一些音频处理的工具方法。
mindspore.dataset.vision : 此模块用于图像数据增强,包 括 c_transforms 和 py_transforms 两个子模块。 c_transforms 是使用 C++ OpenCv 开发的高性能图像增强模块。 py_transforms 是使用 Python Pillow 开发的图像增强 模块。 mindspore.dataset.text :此模块用于文本数据增强,包括 transforms 和 utils 两个 子模块。 ▫ transforms 是一个高性能文本数据增强模块,支持常见的文本数据增强处理。 ▫ utils 提供了一些文本处理的工具方法。 mindspore.dataset.audio : 此模块用于音频数据增强,包括 transforms 和 utils 两个 子模块。 transforms 是一个高性能音频数据增强模块,支持常见的音频数据增强操 作。 utils 提供了一些音频处理的工具方法。 

 在 MindSpore 中,自定义网络结构、损失函数等可以通过继承对应的父类来快速创建。 具体函数及类的使用请参看 MindSpore 文档: https://www.mindspore.cn/docs/zh CN/r1.7/index.html 。
在 MindSpore 中,自定义网络结构、损失函数等可以通过继承对应的父类来快速创建。 具体函数及类的使用请参看 MindSpore 文档: https://www.mindspore.cn/docs/zh CN/r1.7/index.html 。 

 MindSpore 中神经网络的基本构成单元为 nn.Cell 。模型或神经网络层应当继承该基类。 基类的成员函数 construct 是定义要执行的计算逻辑,所有继承类都必须重写此方法。
MindSpore 中神经网络的基本构成单元为 nn.Cell 。模型或神经网络层应当继承该基类。 基类的成员函数 construct 是定义要执行的计算逻辑,所有继承类都必须重写此方法。 

 训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调( fine tune )和后续的模型部署和推理。且当模型过于庞大时,需要边训练边保存。 第二种保存方式首先需要初始化一个 CheckpointConfig 类对象,用来设置保存策略。 ▫ save_checkpoint_steps 表示每隔多少个 step 保存一次。 ▫ keep_checkpoint_max 表示最多保留 CheckPoint 文件的数量。 ▫ prefix 表示生成 CheckPoint 文件的前缀名。 ▫ directory 表示存放文件的目录。 创建一个 ModelCheckpoint 对象把它传递给 model.train 方法,就可以在训练过程中使 用 CheckPoint 功能了。
训练网络模型的过程中,实际上我们希望保存中间和最后的结果,用于微调( fine tune )和后续的模型部署和推理。且当模型过于庞大时,需要边训练边保存。 第二种保存方式首先需要初始化一个 CheckpointConfig 类对象,用来设置保存策略。 ▫ save_checkpoint_steps 表示每隔多少个 step 保存一次。 ▫ keep_checkpoint_max 表示最多保留 CheckPoint 文件的数量。 ▫ prefix 表示生成 CheckPoint 文件的前缀名。 ▫ directory 表示存放文件的目录。 创建一个 ModelCheckpoint 对象把它传递给 model.train 方法,就可以在训练过程中使 用 CheckPoint 功能了。 

 由于移动端算力不足问题,需要考虑模型的大小和计算量。
由于移动端算力不足问题,需要考虑模型的大小和计算量。  答案: ABC
答案: ABC 