文章目录
前言一、库导入二、训练1.引入库2.训练3.你可能遇到的问题 三、数据保存1.保存2.注意参数设置! 本文最终代码
前言
在上文的末尾,我们已经完成了对环境变量的矢量化,那这次我们就正式开始强化学习的训练。请查看最终代码的顺序,帮助你更好理解本文内容。
一、库导入
import osfrom stable_baselines3 import PPOfrom stable_baselines3.common.callbacks import BaseCallbackos库用于保存训练的模型参数。
PPO用于导入我们训练需要的算法。
BaseCallback库用于帮助我们保存和可视化的查看我们的训练过程,包括但不限于loss是否下降等等,可以直观的看出训练有没有效果以及问题排查。
二、训练
1.引入库
chechpoint_dir = './train/'log_dir = './logs/'checkpoint_dir 保存训练集
log_dir 保存训练日志 即每次训练之后的loss等的数据 的路劲
2.训练
model = PPO('CnnPolicy', environment, verbose=1, tensorboard_log=log_dir, learning_rate=0.000001, n_steps=512)model.learn(total_timesteps=200000, callback=callback)我们调用PPO函数,这是开源库已经帮我们做好的算法接口,我们调用即可。此处我们使用的是CnnPolicy,就是卷积神经网络。简单阐述一下,卷积神经网络是通过矩阵的卷积操作来识别、分析图片,一般用于图像识别等的有监督学习中。此处由于我们需要处理马里奥游戏传给我们的图片,所以我们使用卷积神经网络。
learning_rate是学习率,是我们一次训练后,要向更优方向移动的距离,step是一次训练的次数。
model.learn设定训练总量。
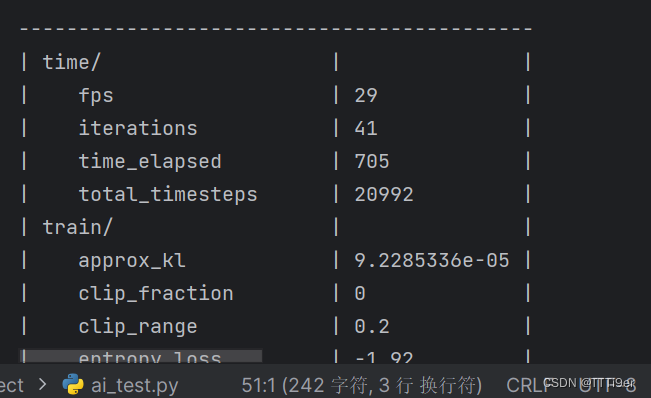
输出是这样就说明正在训练了。
3.你可能遇到的问题
如果你遇到
ImportError: Trying to log data to tensorboard but tensorboard is not installed.
说明你没安装tensorboard库,请输入
pip install tensorboard三、数据保存
1.保存
class TrainAndLoggingCallback(BaseCallback): def __init__(self, check_freq, save_path, verbose=1): super(TrainAndLoggingCallback, self).__init__(verbose) self.check_freq = check_freq self.save_path = save_path def _init_callback(self): if self.save_path is not None: os.makedirs(self.save_path, exist_ok=True) def _on_step(self): if self.n_calls % self.check_freq == 0: model_path = os.path.join(self.save_path, 'best_model_{}'.format(self.n_calls)) self.model.save(model_path) return True这一部分是重写了BaseCallBack库,这些方法名都是库内做过抽象方法的,如果你需要自行改写,请不要修改这些方法名字。此处就是设定了一些路径,不必浪费过多时间,复制即可。
#调用callback = TrainAndLoggingCallback(check_freq=10000, save_path=chechpoint_dir)以上函数是调用了TrainAndLoggingCallBack函数,每10000次记录一次。
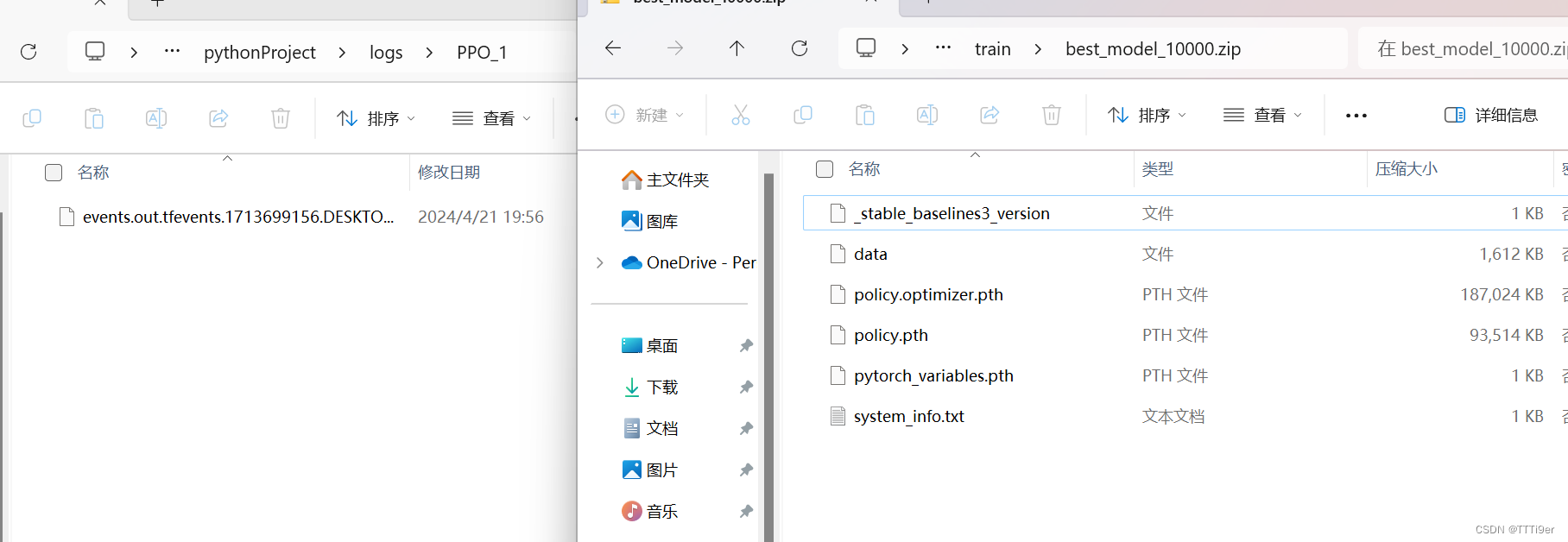
这是保存的文件。左为日志,右为模型。
我们可以使用tensorboard查看左边的log数据,方法如下数据可视化教材
2.注意参数设置!
请注意 n_steps=512和total_timesteps=200000,这两个设置,如果你需要快速得出答案,需要调小哦,本人3060,这个参数需要训练一个小时,请注意电脑散热、电量。
本文最终代码
import gym_super_mario_brosfrom nes_py.wrappers import JoypadSpacefrom gym_super_mario_bros.actions import SIMPLE_MOVEMENTfrom gym.wrappers import FrameStack, GrayScaleObservationfrom stable_baselines3.common.vec_env import VecFrameStack, DummyVecEnvfrom matplotlib import pyplot as pltimport timeenvironment = gym_super_mario_bros.make('SuperMarioBros-v0')environment = JoypadSpace(environment, SIMPLE_MOVEMENT)environment = GrayScaleObservation(environment, keep_dim=True)environment = DummyVecEnv([lambda : environment])environment = VecFrameStack(environment , 4, channels_order='last')# 用于保存训练的模型参数import os# 导入训练用的算法from stable_baselines3 import PPO# 帮助保存,不一定需要from stable_baselines3.common.callbacks import BaseCallbackclass TrainAndLoggingCallback(BaseCallback):#都是重写,注意格式 def __init__(self, check_freq, save_path, verbose=1): super(TrainAndLoggingCallback, self).__init__(verbose) self.check_freq = check_freq self.save_path = save_path def _init_callback(self): if self.save_path is not None: os.makedirs(self.save_path, exist_ok=True) def _on_step(self): if self.n_calls % self.check_freq == 0: model_path = os.path.join(self.save_path, 'best_model_{}'.format(self.n_calls)) self.model.save(model_path) return True#保存训练集chechpoint_dir = './train/'#保存训练日志 即每次训练之后的loss等的数据log_dir = './logs/'#每一万次保存一次,防止数据丢失callback = TrainAndLoggingCallback(check_freq=10000, save_path=chechpoint_dir)model = PPO('CnnPolicy', environment, verbose=1, tensorboard_log=log_dir, learning_rate=0.000001, n_steps=512)model.learn(total_timesteps=200000, callback=callback)