目录
前言
设计思路
一、课题背景与意义
二、算法理论原理
2.1 目标检测
2.2 Anchor改进
三、检测的实现
3.1 数据集
3.2 实验环境搭建
3.3 实验及结果分析
实现效果图样例
最后
前言
?大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
?对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
?基于深度学习的钢材表面缺陷识别系统

设计思路
一、课题背景与意义
基于深度学习的目标检测方法具有较高的检测精度和较强的适应性,在工业场景中也得到了广泛的应用。在钢材表面缺陷检测任务中,由于复杂的工业环境等因素的影响,导致检测难度增加,误检率和漏检率高,检测效率低。因此,对钢材表面缺陷进行快速精准的识别具有重要的研究意义。
二、算法理论原理
2.1 目标检测
阶段目标检测算法首先使用设计好的区域建议网络生成感兴趣区域,然后将目标检测任务转变为对生成的感兴趣区域中图像进行分类的任务。R-CNN是第一个两阶段的深度学习目标检测算法,其中的结构设计也成为了此后两阶段目标检测算法提供了重要参考。Faster R-CNN结构由3个网络组成,分别是特征提取网络、RPN区域建议网络和检测子网络。Faster R-CNN网络的改进之处是将区域建议网络融入进算法网络,通过RPN直接训练得到候选区域,改善了网络对于目标预测的精度。
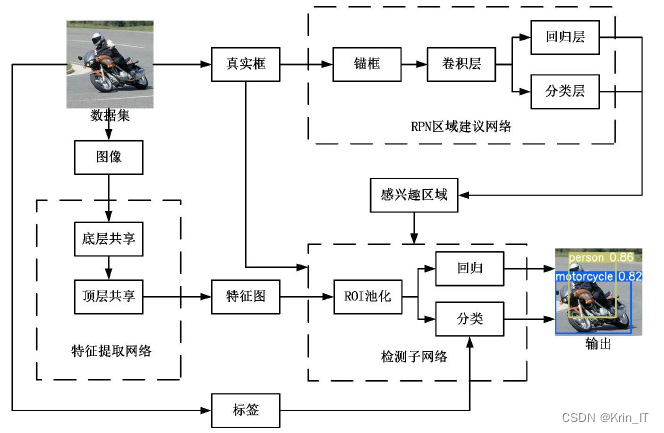
2.2 Anchor改进
Anchor是目标检测中一组无固定尺寸的候选框,Anchor的相关参数会间接地决定目标位置回归的准确性。K-Means属于划分聚类方法,其学习模式为无监督,二维数据可以通过K-Means方法进行有效地聚类。数据在二维空间中的近似程度通常使用欧氏距离来评判,近似程度与数据之间的欧氏距离成反相关。欧氏距离越小近似程度越大。
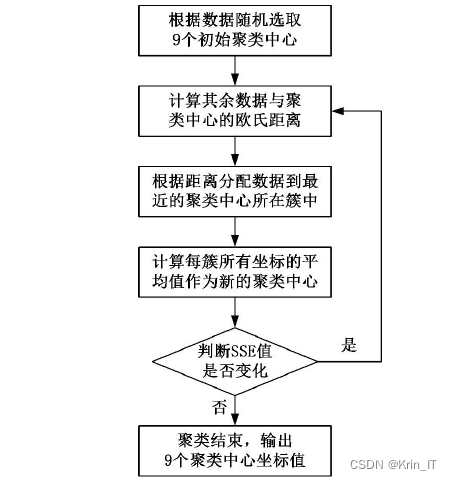
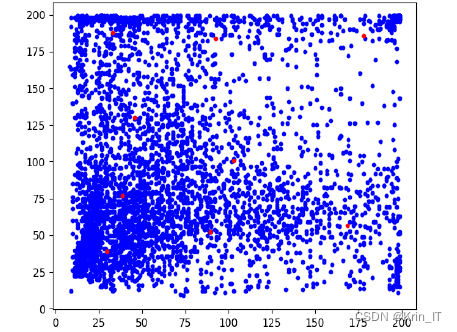
NEU-DET数据集 经过聚类后的结果如下,其中红色圆点为聚类中心,横坐标为Anchor的宽,纵坐标为 Anchor的高。
不同Anchor选择方法的损失函数曲线 :

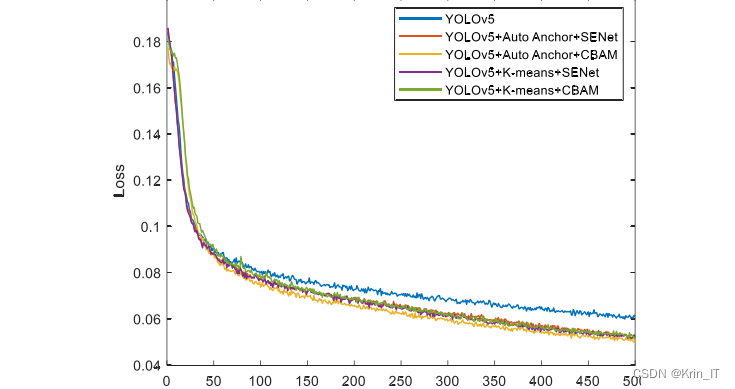
K-Means聚类方法的模型收敛情况更好,在前260个周期里3种Anchor策略的训练损失差别不明显,在260个周期以后K-Means聚类方法的Loss值下降速度变快,在500个周 期后Loss值下降到0.05左右,而其他两条曲线的Loss值均在0.06左右。
三、检测的实现
3.1 数据集
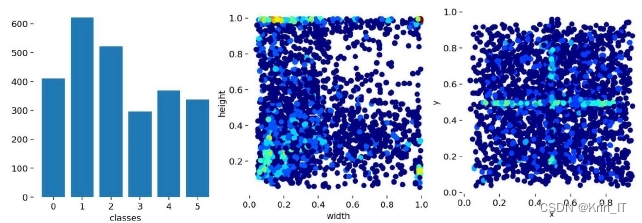
数据集是从互联网收集了钢带的6种典型表面缺陷,即轧制氧化皮(RS),斑块(Pa),开裂(Cr),点蚀表面(PS),凹陷(De)和划痕(Sc)对于缺陷检测任务,数据集提供了注释,标明了每个图像中缺陷的类别和位置。该数据集包括1800张灰度图像,每种缺陷300张图像。

将数据集中的图像用LabelImg工具软件标注并以YOLOv5数据的格式分类存储。数据集中共1800张钢材表面缺陷图像,将其中1260张作为训练集,360张作为验证集,剩余180张作为测试集,训练集、验证集、测试集的比例大致为7:2:1,以这样的比例分配数据集可以保证更好的训练效果。
3.2 实验环境搭建
钢材表面缺陷检测研究使用的框架为PyTorch。深度学习框架将算法的编写统一化、规范化,有利于学习和开发。主流的深度学习框架有PyTorch、TensorFlow、Caffe、Keras、CNTK、MXNet、PaddlePaddle等。不同的深度学习框架具有不同的特点,PyTorch支持多种语言环境,被业内开发人员广泛使用。
在此次训练环境的配置过程中选取了NVIDIA Geforce GTX 1080显卡作为图形处理单元,在使用GPU时,在命令行输入NVIDIA-smi命令时会显示出一个命令界面,其中包含了GPU当下状态的所有参数信息。若使用GPU处理图形数据,节省训练和检测时长,则需要预先根据GPU型号配置CUDA和CUDNN等环境。

3.3 实验及结果分析
实验的整体流程:首先对数据集进行线性对比度增强处理,然后对训练参数进行调整以保证较好的训练效果和一致的训练条件,紧接着将其送入不同的网络模型中进行训练并对结果进行分析,最后将模型保存用于测试和部署。
从两个阶段对于YOLOv5算法进行改进,每个阶段各提出了两种方法,Anchor选择阶段提出的方法是自适应Anchor和K-Means聚类Anchor;骨干网络特征提取阶段提出的方法是添加SENet和CBAM注意力机制。为了更快速完成训练同时保证训练效果,YOLOv5在网络模型的训练过程中采取了一些训练技巧。如训练学习率预热、带重启的随机梯度下降、余弦退火学习率调整和自动混合精度训练等。在完成参数调整以后,严格按照上述的训练环境、网络模型以及数据集对网络进行训练。
for epoch in range(num_epochs): # 训练学习率预热 adjust_learning_rate(epoch, lr) for batch_data, batch_labels in train_loader: # 正向传播 outputs = model(batch_data) loss = calculate_loss(outputs, batch_labels) # 反向传播和优化 optimizer.zero_grad() loss.backward() optimizer.step()训练过程中损失函数曲线:
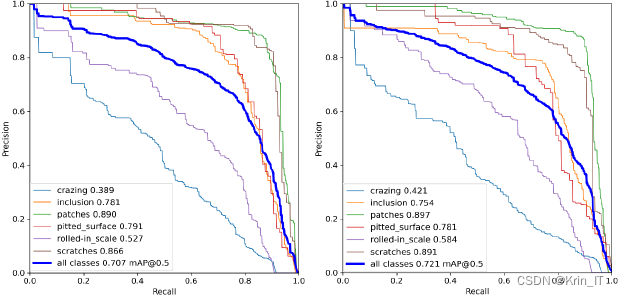
网络模型训练得到的PR曲线:
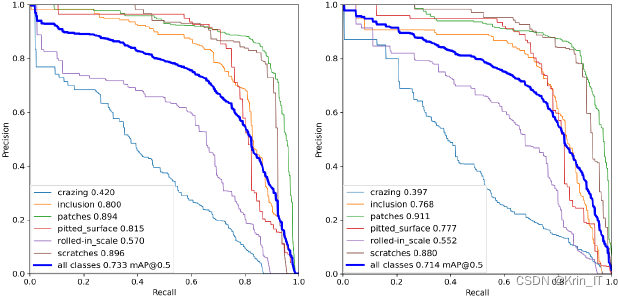
相关代码如下:
import cv2import numpy as npimport tensorflow as tf# 加载预训练的缺陷识别模型model = tf.keras.models.load_model('defect_detection_model.h5')# 设置缺陷类别标签class_labels = ['scratch', 'crack', 'pitting', 'corrosion']# 打开钢材表面图像image = cv2.imread('steel_surface_image.jpg')# 对图像进行预处理,如调整大小、归一化等preprocessed_image = preprocess_image(image)# 使用缺陷识别模型进行预测predictions = model.predict(np.expand_dims(preprocessed_image, axis=0))# 提取预测结果defect_class_id = np.argmax(predictions)defect_class_label = class_labels[defect_class_id]confidence = predictions[0, defect_class_id]# 在图像上绘制识别结果image = draw_defect(image, defect_class_label, confidence)# 显示图像cv2.imshow('Steel Surface Defect Detection', image)cv2.waitKey(0)cv2.destroyAllWindows()实现效果图样例

创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!