Web Speech API的语音识别技术
SpeechSynthesis对象
这是一个实验性技术
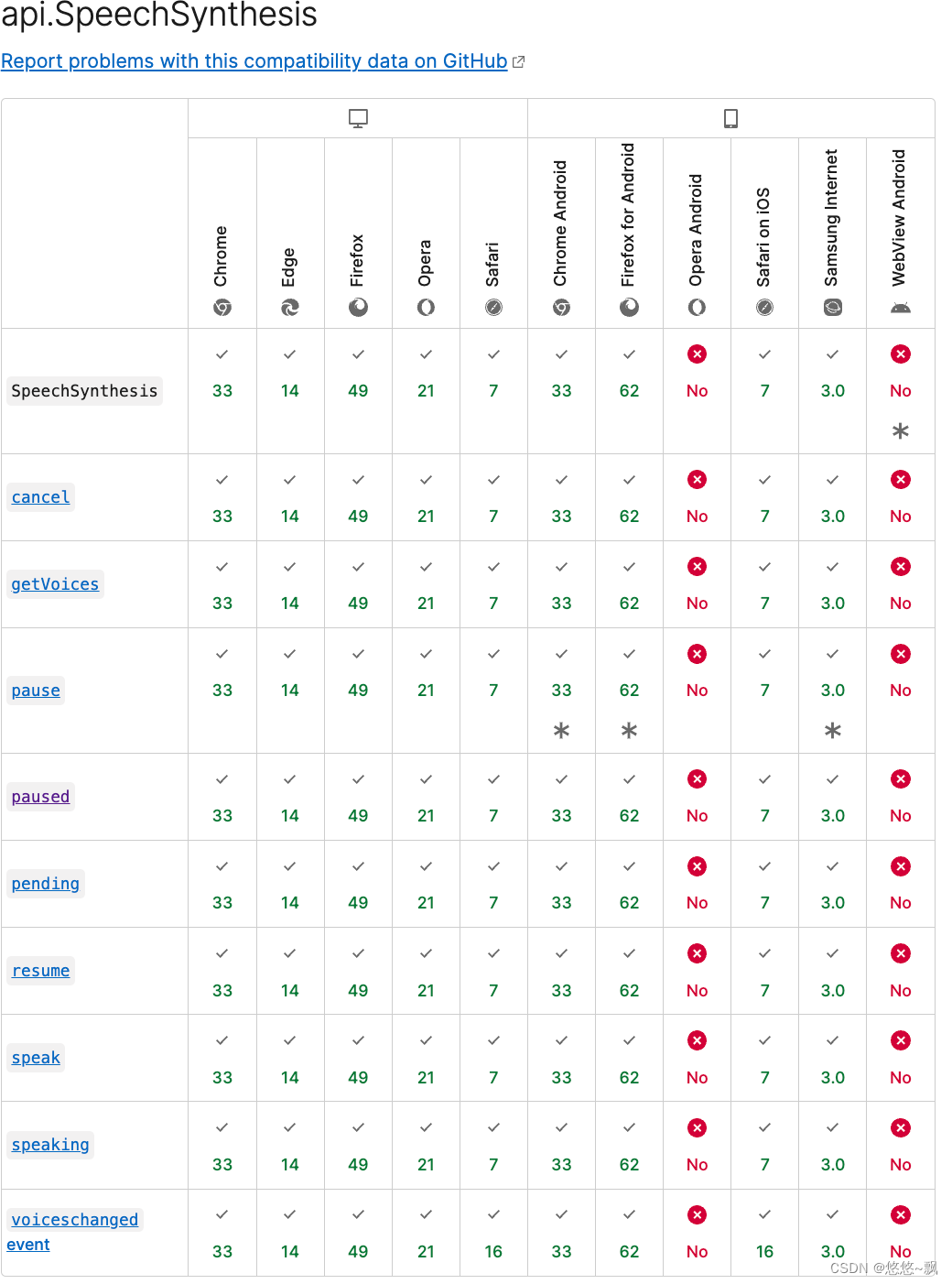
目前兼容性如图:
pc端几乎兼容,移动端部分不兼容
网页语音 API 的SpeechSynthesis 接口是语音服务的控制接口;
它可以用于获取设备上关于可用的合成声音的信息,开始、暂停语音,或除此之外的其他命令。
SpeechSynthesis 也从它的父接口继承属性,EventTarget.
SpeechSynthesis.paused 只读
当SpeechSynthesis 处于暂停状态时, Boolean值返回 true 。
SpeechSynthesis.pending只读
当语音播放队列到目前为止保持没有说完的语音时, Boolean值返回 true 。
SpeechSynthesis.speaking只读
当语音谈话正在进行的时候,即使SpeechSynthesis处于暂停状态, Boolean返回 true 。
事件操作
SpeechSynthesis.onvoiceschanged (en-US)当由SpeechSynthesis.getVoices()方法返回的SpeechSynthesisVoice (en-US)列表改变时触发。
方法
SpeechSynthesis 也从它的父接口继承方法, EventTarget.
SpeechSynthesis.cancel() (en-US)
移除所有语音谈话队列中的谈话。
SpeechSynthesis.getVoices()
返回当前设备所有可用声音的 SpeechSynthesisVoice (en-US)列表。
SpeechSynthesis.pause() (en-US)
把 SpeechSynthesis 对象置为暂停状态。
SpeechSynthesis.resume() (en-US)
把 SpeechSynthesis 对象置为一个非暂停状态:如果已经暂停了则继续。
SpeechSynthesis.speak() (en-US)
添加一个 utterance到语音谈话队列;它将会在其他语音谈话播放完之后播放。
示例
用 window.speechSynthesis抓取关于语音播放控制器
在定义了一些必要的变量后,用 SpeechSynthesis.getVoices()获取了一列可用的声音并且用它们生成一列可选表单,这样用户能够选择他们想要的声音。
inputForm.onsubmit 的内部操作中,我们用preventDefault()阻止了表单的提交,创建了一个从文本框获取文本的新SpeechSynthesisUtterance (en-US)实例,在元素可选的声音设置成语音谈话的 voice 属性,然后通过SpeechSynthesis.speak() (en-US)方法开始语音播放。
var synth = window.speechSynthesis;var inputForm = document.querySelector("form");var inputTxt = document.querySelector(".txt");var voiceSelect = document.querySelector("select");var pitch = document.querySelector("#pitch");var pitchValue = document.querySelector(".pitch-value");var rate = document.querySelector("#rate");var rateValue = document.querySelector(".rate-value");var voices = [];function populateVoiceList() { voices = synth.getVoices(); for (i = 0; i < voices.length; i++) { var option = document.createElement("option"); option.textContent = voices[i].name + " (" + voices[i].lang + ")"; if (voices[i].default) { option.textContent += " -- DEFAULT"; } option.setAttribute("data-lang", voices[i].lang); option.setAttribute("data-name", voices[i].name); voiceSelect.appendChild(option); }}populateVoiceList();if (speechSynthesis.onvoiceschanged !== undefined) { speechSynthesis.onvoiceschanged = populateVoiceList;}inputForm.onsubmit = function (event) { event.preventDefault(); var utterThis = new SpeechSynthesisUtterance(inputTxt.value); var selectedOption = voiceSelect.selectedOptions[0].getAttribute("data-name"); for (i = 0; i < voices.length; i++) { if (voices[i].name === selectedOption) { utterThis.voice = voices[i]; } } utterThis.pitch = pitch.value; utterThis.rate = rate.value; synth.speak(utterThis); inputTxt.blur();};属性:
paused
SpeechSynthesis 接口的只读属性 paused 是一个 Boolean值,当SpeechSynthesis对象处于暂停状态时,返回true ,否则返回 false。
它能被设置为 暂停状态即使当前并没有语音在播放队列中。如果utterances被添加到语音播放队列,队列中的语音并不会播放直到使用 SpeechSynthesis.resume() (en-US)使SpeechSynthesis对象处于非暂停状态。
语法
var amIPaused = speechSynthesisInstance.paused;
Value
一个Boolean (en-US)。
示例
var synth = window.speechSynthesis;synth.pause();var amIPaused = synth.paused; // 将返回 truepending
只读属性 SpeechSynthesisinterface是一个布尔值,返回 true如果话语队列包含尚未说出的话语。
值
布尔值。
示例
const synth = window.speechSynthesis;const utterance1 = new SpeechSynthesisUtterance( "helloWorld.",);const utterance2 = new SpeechSynthesisUtterance( "helloWorld2.",);synth.speak(utterance1);synth.speak(utterance2);const amIPending = synth.pending; // 如果话语1仍在说话并且话语2在队列中,则将返回trues in the queuespeaking
只读属性 SpeechSynthesisinterface是一个布尔值,返回 true如果话语当前正在被说出的过程中-甚至 如果SpeechSynthesis在 paused州。
值
布尔值。
示例
const synth = window.speechSynthesis;const utterance1 = new SpeechSynthesisUtterance( "话语1.",);const utterance2 = new SpeechSynthesisUtterance( "话语2.",);synth.speak(utterance1);synth.speak(utterance2);const amISpeaking = synth.speaking; // 如果话语1或话语2当前正在说话,则将返回true方法详情
cancel方法
从话语队列中移除所有话语。 如果正在说话,说话将立即停止。
语法
实例.cancel()参数
无
返回值
无(undefined)。
示例
const synth = window.speechSynthesis;const utterance1 = new SpeechSynthesisUtterance( "话语1.",);const utterance2 = new SpeechSynthesisUtterance( "话语2.",);synth.speak(utterance1);synth.speak(utterance2);synth.cancel(); //话语1立即停止,并且两者都从队列中删除getVoices方法
SpeechSynthesis接口返回一个 SpeechSynthesisVoice对象表示所有可用的声音上 当前设备语法
实例.getVoices()参数
无
返回值
无
示例
function populateVoiceList() { if (typeof speechSynthesis === "undefined") { return; } const voices = speechSynthesis.getVoices(); for (let i = 0; i < voices.length; i++) { const option = document.createElement("option"); option.textContent = `${voices[i].name} (${voices[i].lang})`; if (voices[i].default) { option.textContent += " — DEFAULT"; } option.setAttribute("data-lang", voices[i].lang); option.setAttribute("data-name", voices[i].name); document.getElementById("voiceSelect").appendChild(option); }}populateVoiceList();if ( typeof speechSynthesis !== "undefined" && speechSynthesis.onvoiceschanged !== undefined) { speechSynthesis.onvoiceschanged = populateVoiceList;}pause方法
将SpeechSynthesis对象置于暂停状态。 语法
实例.pause()参数
无
返回值
SpeechSynthesisVoice对象的列表(数组)。
示例
const synth = window.speechSynthesis;const utterance1 = new SpeechSynthesisUtterance( "话语1.",);const utterance2 = new SpeechSynthesisUtterance( "话语2.",);synth.speak(utterance1);synth.speak(utterance2);synth.pause(); // 暂停说话resume方法
如果它已经暂停,则恢复它。语法
实例.resume()参数
无
返回值
无
示例
let synth = window.speechSynthesis;const utterance1 = new SpeechSynthesisUtterance( "话语1.",);const utterance2 = new SpeechSynthesisUtterance( "话语2.",);synth.speak(utterance1);synth.speak(utterance2);synth.pause(); synth.resume(); //恢复暂停voiceschanged事件
Web Speech API的voiceschanged事件在由SpeechSynthesisVoice方法返回的SpeechSynthesis.getVoices()对象的列表发生更改时触发(在voiceschanged事件触发时)。语法
在类似addEventListener()的方法中使用事件名称,或者设置事件处理程序属性。
addEventListener("voiceschanged", (event) => {});onvoiceschanged = (event) => {};事件类型
没有添加属性的泛型Event。
示例
这可以用来重新填充一个声音列表,用户可以在事件触发时从中选择。您可以在voiceschanged方法中使用addEventListener事件:
const synth = window.speechSynthesis;synth.addEventListener("voiceschanged", () => { const voices = synth.getVoices(); for (let i = 0; i < voices.length; i++) { const option = document.createElement("option"); option.textContent = `${voices[i].name} (${voices[i].lang})`; option.setAttribute("data-lang", voices[i].lang); option.setAttribute("data-name", voices[i].name); voiceSelect.appendChild(option); }});或者使用onvoiceschanged事件处理程序属性:
const synth = window.speechSynthesis;synth.onvoiceschanged = () => { const voices = synth.getVoices(); for (let i = 0; i < voices.length; i++) { const option = document.createElement("option"); option.textContent = `${voices[i].name} (${voices[i].lang})`; option.setAttribute("data-lang", voices[i].lang); option.setAttribute("data-name", voices[i].name); voiceSelect.appendChild(option); }};
登录后可发表评论
点击登录