系列文章目录?
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
文章目录
系列文章目录?前言一、常用的预训练数据集1、网页2、书籍3、维基百科4、代码5、混合型数据集 二、常用微调数据集1、指令微调数据集1.1 自然语言处理任务数据集1.2 日常对话数据集1.3 合成数据集 2、人类对齐数据集
前言
在人工智能领域,构建强大的AI系统的关键步骤之一是大规模的语言模型预训练。为了实现这一目标,需要大量且多样化的训练数据。以下是对目前常用于训练大语言模型的数据集的整理与概述。

一、常用的预训练数据集
大语言模型在训练上需要大量的训练数据,这些数据需要涵盖广泛的内容范围。多领域、多源化的训练数据可以帮助大模型更加全面地学习真实世界的语言与知识,从而提高其通用性和准确性。本节将介绍目前常用于训练大语言模型的代表性数据集合。根据其内容类型进行分类,这些语料库可以划分为:网页、书籍、维基百科、代码以及混合型数据集。
1、网页
网页是大语言模型训练语料中最主要的数据来源,包含了丰富多样的文本内容,例如新闻报道、博客文章、论坛讨论等,这些广泛且多元的数据为大语言模型深入理解人类语言提供了重要资源。下面介绍重要的网页数据资源。
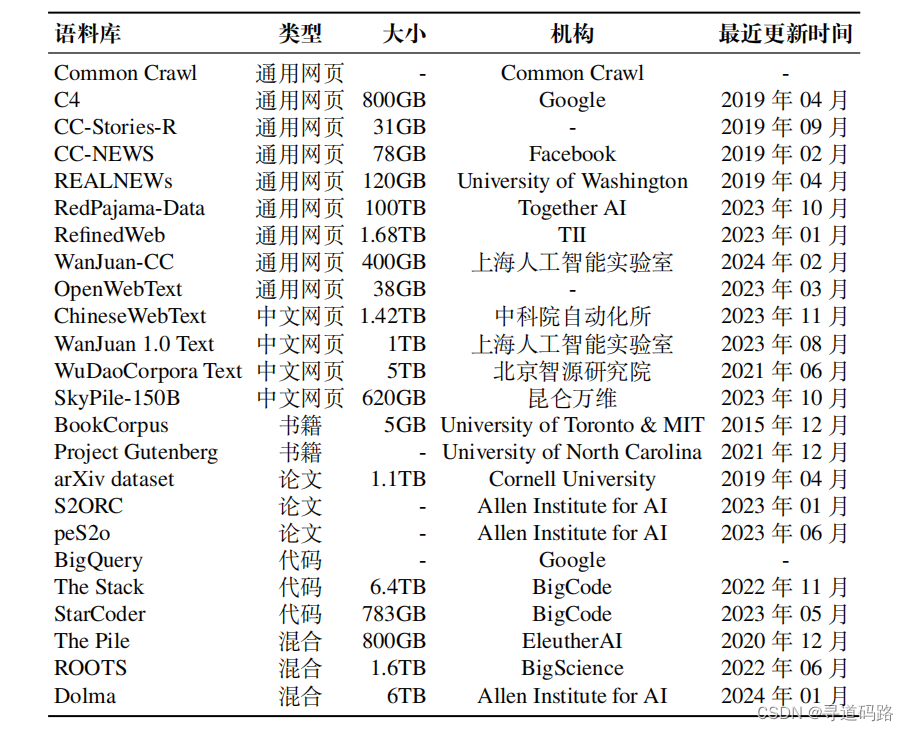
下面是部分通用的数据集:
1)Common Crawl. 该数据集是一个规模庞大的、非结构化的、多语言的网页数据集,包含原始网页数据、元数 据和提取的文本数据等,总数据量达到 PB 级别。由于这个数据集规模过于庞大,一般主要提取其特定时间段或者符合特殊要求的子集进行使用,注意:该数据集内部充斥着大量的噪声和低质量数据,在使用前必须清洗,常用的自动清洗工具有 CCNet 等。
2)CC-News. 该数据集是一个新闻文章数据集,数据量约 76GB,包含了从 2016 年 9 月到 2019 年 2 月期间抓取的 63M 篇英文新闻文章,并以网页存档 (WARC)文件形式提供。
3) RedPajama-Data 该数据集是一个公开的综合网页数据集,包含了来自 Common Crawl 的 100B 份文档,其使用了 CCNet 工具进行清洗,在经过过滤和去重得到约 30T 词元。
4) RefinedWeb该数据集是一个在 Common Crawl 数据的基础上通过严格 筛选和去重得到的网络数据集,共约 5T 词元。其中,开源部分有 600B 词元,数据量约 500GB,解压后需要 2.8TB 的本地存储空间。
5)WanJuan-CC(万卷 CC)该数据集是一个从 Common Crawl 数据中抽取并清洗的高质量英文数据集。从约 130B 份原始数据文档中萃取出约 1.38% 的高质量内容。
6)WebText. 该数据集是由 OpenAI 构建的一个专注于文档质量的网络文本语料库40GB。在GPT-2、GPT-3 和 InstructGPT 等模型的训练过程中,都是使用了该数据集(并未开源)。 OpenWebText. 该数据集是 WebText 的一个复现开源版本,与 WebText 的构建方法相似,保留了来自约 8M 份文档的 38GB 文本数据。
在上述网页数据集中,中文网页占比通常非常低。为了训练具有较好中文语言能力的大语言模型,通常需要专门收集与构建中文网页数据集合。下面介绍具有代表性的中文网页数据集。
1) ChineseWebText 该数据集是从 Common Crawl 庞大的网页数据中精心筛选的中文数据集。该数据集总计 1.42TB 数据量。ChineseWebText 的每篇文本都附有一个定量的质量评分,为研究人员提供了可用于筛选与使用的参考标准。此外,为满足不同研究场景的需求,
ChineseWebText 还特别发布了一个 600GB 大小的中文数据子集,并配套推出了一款名为 EvalWeb 的数据清洗工具,方便研究人员根据需求清洗数据。
2) WanJuan 1.0 Text 该数据集是上海人工智能实验室发布的万卷 1.0 多模态语料库的一部分(除文本数据集外,还有图文数据集和视频数据集)。该文本数据集由多种不同来源的数据组成,包括网页、书籍等,数据总量约 500M 个文档,数据大小超过 1 TB。
3)WuDaoCorpora Text 该数据集是北京智源研究院构建的“悟道”项目数据集的一部分(除文本数据集外,还有多模态图文数据集和中文对话数据集)。其中还包含教育、科技等超过 50 个行业数据标签,经过清洗、隐私数据信息去除后剩余 5TB,而开源部分有 200GB。
2、书籍
书籍是人类知识与文化的重要载体,已经成为了重要的预训练数据源之一。书籍通常都是有着较为严格的版权限制,使用者需要按照版权的要求来判断是否能够使用某一书籍用于训练。目前,常用的书籍数据集包括下述几个数据集合。
1) BookCorpus 该数据集是一个免费小说书籍集合,大约有 74M 句子和 1B 个单词,涵盖了 16 种不同的主题类型5GB 左右。该数据集常被用于训练小规模的模型, 如 GPT 和 GPT-2。同时,原始数据集不再公开,伦多大学创建了一个镜像版本 BookCorpusOpen,可在 Hugging Face 上进行下载。
2)arXiv Dataset是一个收录了众多领域预印本论文的网站。广泛涵盖了物理、数学和计算机科学等领域的论文文献,共包含约1.7M 篇预印本文章,总数据量约为 1.1TB,并在 Kaggle 上提供了公开下载。
3)S2ORC该数据集源于学术搜索引擎 Semantic Scholar 上的学术论文,这些论文经过了清洗、过滤并被处理成适合预训练的格式。在 Semantic Scholar 上提供了可公开下载的版本。此外,该数据集还有一个衍生数据集 peS2o,到目前为止已发布了两个版本,其中 v2 版本共计包含了约 42B 词元,并且在 Hugging Face 提供了公开下载。
3、维基百科
维基百科(Wikipedia)是一个综合性的在线百科全书,由全球志愿者共同编写和维护,提供了高质量的知识信息文章,涵盖了历史、科学、文化艺术等多个领域。维基百科的数据具有以下几个特点:
专业性:维基百科的条目通常具有良好的结构性和权威性;多语性:维基百科支持的语言种类有汉语、英语、法语等300 多种语言;实时性:维基百科的内容目前还在不断更新,知识信息的维护较为及时。4、代码
代码具有高度结构化与专业性的特点。 对于预训练语言模型来说,引入包含代码的数据集可以增强模型的结构化推理能力与长程逻辑关系,能够提升模型理解和生成编程语言的能力。两个主要来源是公共 代码仓库GitHub和StackOverflow。
1)BigQuery. BigQuery 是谷歌发布的企业数据仓库,包含了众多领域的公 共数据集,如社交、经济、医疗、代码等。其中的代码类数据覆盖各种编程语言。CodeGen 抽取了 BigQuery 数据库中的公开代码数据子集构成 BIGQUERY 进行训练,以得到多语言版本的 CodeGen。
2)The Stack 该数据集由 Hugging Face 收集并发布,是一个涵盖了 30 种编程语言的代码数据集,其数据来源于 GHArchive 项目的 GitHub 活跃仓库。
3)StarCoder 该数据集是 BigCode 围绕 The Stack v1.2 进一步处理得到的代码数据集,是同名模型 StarCoder 的预训练数据。
5、混合型数据集
除了上述特定类型的数据集外,为了便于研发人员的使用,很多研究机构对于多种来源的数据集合进行了混合,发布了一系列包括多来源的文本数据集合。
1)The Pile: 一个大规模、多样化且可公开下载的文本数据集,数据来源非常广泛,包括书籍、网站、代码、科学论文和社交媒体数据等。该数据集由22个多样化的高质量子集混合而成,包括上面提到的OpenWebText、维基百科等。
2)ROOTS: 涵盖了59种不同语言数据集。该数据集主要由两部分组成:约62%的数据来源于整理好的自然语言处理数据集及相关文档、利用Common Crawl收集的网页数据以及GitHub代码数据。
3)Dolma: 该数据集也包含了多种数据源,包括来自Common Crawl的网络文本、Semantic Scholar学术论文、GitHub代码、书籍、Reddit的社交媒体帖子以及维基百科数据。
二、常用微调数据集
为了增强模型的任务解决能力,大语言模型在预训练之后需要进行适应性微调,通常涉及两个主要步骤,即指令微调(有监督微调)和对齐微调。
1、指令微调数据集
在预训练之后,指令微调(也称为有监督微调)是增强或激活大语言模型特 定能力的重要方法之一(例如指令遵循能力)。本小节将介绍几个常用的指令微调数据集,并根据格式化指令实例的构建方法将它们分为三种主要类型,即自然语言处理任务数据集、日常对话数据集和合成数据集。
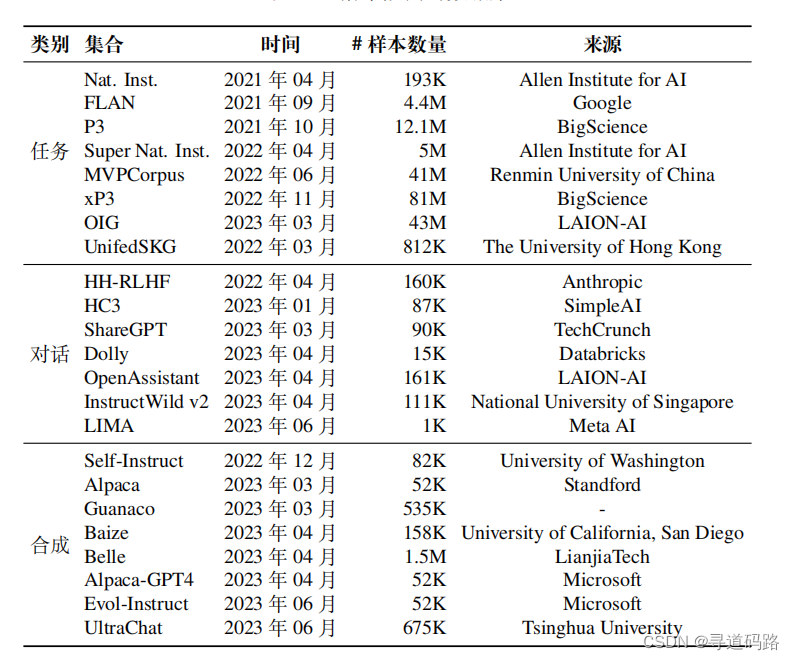
1.1 自然语言处理任务数据集
在指令微调被提出前,早期的研究通过收集不同自然语言处理任务(如文本分类和摘要等)的实例,创建了有监督的多任务训练数据集。这些多任务训练数据集成为了构建指令微调数据集的重要来源之一。
1)P3. P3(Public Pool of Prompts)是一个面向英文数据的指令微调数据集,由超过 270 个自然语言处理任务数据集和 2,000 多种提示整合而成,全面涵盖多选问答、提取式问答、闭卷问答、情感分类、文本摘要、主题分类、自然语言推断等自然语言处理任务。
2)FLAN. 早期的 FLAN 是通过将 62 个广泛使用的 NLP 基准数据集进行格式化得到的英语指令数据集。现在俗称的 FLAN 实际上是指 FLAN-v2,主要由四个子集 Muffin、NIV2、T0-SF 和 CoT 构成。
1.2 日常对话数据集
日常对话数据集是基于真实用户对话构建的,其中查询主要是由真实用户提出的,而回复是由人类标注员回答或者语言模型所生成。主要的对话类型包括开放式生成、问答、头脑风暴和聊天。其中,三个较为常用的日常对话数据集包括ShareGPT 、OpenAssistant 和 Dolly。
1)ShareGPT. 该数据集因来源于一个开源的数据收集平台 ShareGPT 而得名。 查询来自于用户的真实提问或指令,回复则是 ChatGPT 对此生成的回答。
2)OpenAssistant. 该数据集是一个人工创建的多语言对话语料库,共有 91,829 条用户提示,69,614 条助手回复。OpenAssistant 共包含 35 种语言的语料,每条语料基本都附有人工标注的质量评级,由用户真实提供的。
3)Dolly. 该数据集是一个英语指令数据集,由 Databricks 公司发布。Dolly 包含了 15,000 个人类生成的数据实例,旨在让大语言模型与用户进行更符合人类价值的高效交互。该数据集由 Databricks 员工标注得到,主题涉及 InstructGPT 论文中提到的 7 个领域,包括头脑风暴、分类、封闭式质量保证、生成、信息提取、开放式质量保证和总结等。
1.3 合成数据集
合成数据集通常是使用大语言模型基于预定义的规则或方法进行构建的。其中,Self-Instruct-52K和 Alpaca-52K是两个具有代表性的合成数据集。
1)Self-Instruct-52K. Self-Instruct-52K 是使用 self-instruct 方法生成的英语指令数据集,共包含 52K 条指令以及 82K 个实例输入和输出。最初,由人工收集创建了 175 个种子任务,每个任务包括 1 个指令和 1 个包含输入输出的实例。然后,每次随机抽取了 8 个指令作为示例,以此提示 GPT-3 生成了新的指令,之后在这些已有指令的基础上,继续利用 GPT-3 生成实例输入及其对应的输出,从而获得了更多数据。
2)Alpaca-52K. Alpaca-52K 数据集同样是基于 self-instruct 方法进行构建的,它是在 Self-Instruct-52K 的 175 个种子任务上,利用 OpenAI 的 text-davinci-003模型获得了 52K 个不重复的指令,并根据指令和输入生成了输出,进而构成了完整的实例数据。
2、人类对齐数据集
除了指令微调之外,将大语言模型与人类价值观和偏好对齐也非常重要。现有的对齐目标一般聚焦于三个方面:有用性、诚实性和无害性。
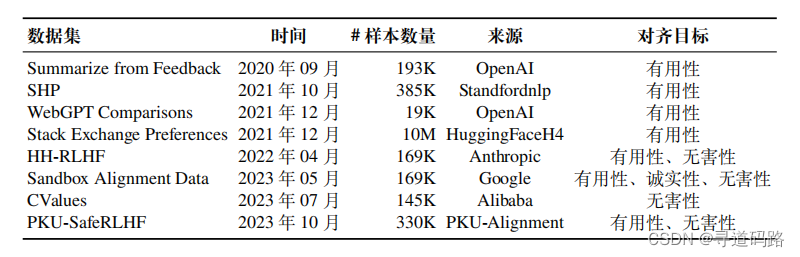
1)HH-RLHF: 该数据集包含两类标注数据,分别关注于大语言模型的有用性和无害性。整个数据集共包含约169K个开放式对话,每个对话涉及一个众包工作者向智能信息助手寻求帮助、建议或请求完成等情景。信息助手将会为每个用户查询提供两个回答,一个回答被选择而另一个被拒绝。对于有用性相关的数据中,被认为更有用的回答将被选择;而对于有害性相关的数据中,被认为更有害的回答将被选择。
2)SHP:主要关注模型生成回复内容的有用性。涵盖了从烹饪到法律建议等各种主题的实例。每个数据实例都是基于一个寻求帮助的 Reddit 帖子构建的,包含该问题下帖子中的问题和帖子下两个排名较高的评论。这两个评论其中一个被 Reddit 用户认为更有用,另一个被认为不太有帮助。与HH-RLHF不同,SHP中的数据并非模型生成的回复,而是真人的回应贴子。
3)PKU-SafeRLHF : 该数据集侧重于对回复内容的有用性和无害性进行标注。该数据集囊括了330K个专家注释的实例,每一个实例都包含一个问题及其对应的两个回答。其中,每个回答都配备了安全性标签,用以明确指出该回答是否安全。
4)Stack Exchange Preferences: 该数据集专注于对答案的有用性进行标注,涵盖了来自知名编程问答社区 Stack Overflow 的约10M个问题和答案,每个数据实例均包含一个具体的问题以及两个或更多的候选答案。每个候选答案都附带一个根据投票数计算得出的分数,并配有一个是指示是否被选中的标签。
5)Sandbox Alignment Data: 致力于运用模型自身的反馈机制来进行数据标注,源于一个虚拟交互环境之中,在这个环境中,多个大语言模型根据问题给出回复然后互相“交流”,并根据彼此的反馈来不断修正和完善自己的回复,每个实例均包含一个查询、多个候选回复选项以及由其他模型给出的相应评分。
6)CValues (Chinese Values): 是一个面向中文的大模型对齐数据集,提出了安全性和责任性这两个评估标准。这个数据集包含了两种类型的提示:安全性提示(未开源)和责任性提示。
?更多专栏系列文章:AIGC-AI大模型探索之路
文章若有瑕疵,恳请不吝赐教;若有所触动或助益,还望各位老铁多多关注并给予支持。