目录
一、标识符
标识符的介绍及命名规则
二、关键字
三、数据类型
数据类型介绍
基本数据类型
整型
字符型
布尔类型(C99)
四、各种数据类型的长度
计算机的存储单位换算
sizeof 操作符
signed 和 unsigned
数据类型长度
sizeof中的表达式不计算
五、数据类型的取值范围
六、转义字符
七、ASCII 码表
八、常量、变量
常量
变量
变量的创建
全局变量
局部变量
全局变量和局部变量在内存中的存储

一、标识符
标识符的介绍及命名规则
标识符介绍
在C语言中为了在程序运行过程中可以使用常量、变量、函数等,就要为这些形式设定一个名称,这个名称就是所谓的标识符。
简单来说,标识符就是名字,主要用于给变量、常量、函数、数组等命名,就像每个人都有一个名字,如张三、李四等。
名字是可以随便取的,但还是应该在满足一定命名规则的基础上自由发挥。
标识符的命名规则
由字母、数字、下划线组成不能以数字开头区分大小写不能使用关键字命名命名最好具有相关含义ANSI标准规定,标识符可以为任意长度,但外部名必须至少能由前8个字符唯一区分(这是因为某些编译程序如IBM PC的MS C仅能识别前8个字符)

二、关键字
C语言的关键字是C语言程序中已经预定义好的具有特殊意义的单词,它们不能作为变量名、函数名或其他标识符使用。
C语言的关键字是固定的,不能自定义或更改。
C语言的32个关键字,如下表
| auto | 声明自动存储类别的局部变量 |
| break | 跳出循环或switch分支 |
| case | switch语句的选择分支 |
| char | 声明字符型变量或函数 |
| const | 声明只读变量,即常量 |
| continue | 在循环中,跳过当前循环的剩余部分,开始下一次循环 |
| default | 在switch语句中,处理其他情况 |
| do | 创建一个执行语句块直到满足特定条件的循环 |
| double | 声明双精度浮点型变量或函数 |
| else | 与if语句一起使用,指定当if条件不满足时执行的代码块 |
| enum | 声明枚举类型和枚举常量 |
| extern | 声明变量或函数是在其他文件或模块中定义的 |
| float | 声明单精度浮点型变量或函数 |
| for | 创建一个循环,指定初始条件、循环条件和循环迭代 |
| goto | 无条件跳转到程序中指定的标签位置 |
| while | 创建一个循环,只要指定条件为真就执行循环体 |
| int | 声明整型变量或函数 |
| long | 声明长整型变量或函数 |
| register | 建议编译器将局部变量存储在寄存器中,以提高访问速度(但现代编译器通常会自动优化) |
| union | 声明联合类型,允许在相同的内存位置存储不同的数据类型 |
| short | 声明短整型变量或函数 |
| signed | 声明有符号类型变量或函数 |
| sizeof | 获取特定类型或对象所占空间大小(以字节为单位) |
| static | 声明静态变量或函数,函数内部定义时具有文件作用域,函数外部定义时具有内部链接性 |
| struct | 声明结构体类型 |
| switch | 基于不同条件执行不同代码块的多路分支结构 |
| typedef | 为数据类型定义新名称 |
| return | 从函数中返回值 |
| unsigned | 声明无符号类型变量或函数 |
| void | 声明函数无返回或无参数,声明指针为空类型指针 |
| votatile | 告诉编译器不要优化对该变量的访问,因为该变量的值可能会在程序不知情的情况下改变 |
| if | 用于条件判断 |
C语言标准可能会随着版本的更新而有所变化,例如C99标准就增加了一些新的关键字。
在C99标准中加入了 intline、restrict、_Bool、_Complex、_Tmaginary等关键字,不过使用最多的还是上面32个关键字。
三、数据类型
数据类型介绍
在生活中,有各种不同的数据,例如你的姓名、年龄、商品的价格、考试成绩等等,C语言提供了丰富的数据类型来描述这些数据。用整型来描述整数,浮点型(实型)来描述小数,字符型来描述字符,布尔类型来描述真假,如你的年龄是18岁,那就是整数类型,书的价格32.8元、考试成绩90.5分,那就是浮点数类型。
类型,也就是相似的数据所拥有的共同特征,编译器只有知道了数据的类型,才知道怎么操作。
下图为C语言中的数据类型分类

基本数据类型
了解了C语言中的数据类型有哪些,我们先来学习其中的基本数据类型。
关于signed,unsigned 以及基本数据类型所占空间大小和取值范围,下文会进行介绍,先了解各个基本数据类型。
下文中 [ ]中的内容可以省略
整型
整型就是我们所说的整数类型,例如 -2,0,1,15,20等。
整型根据所占内存空间大小,又分为短整型,整型,长整型, 更长的整型(C99)
//短整型short [int][signed] short [int] unsigned short //整型int [signed] int unsigned int//长整型long [int][signed] long [int] [unsigned] long [int] //更长的整型//C99中引入long long [int][signed] long long [int] [unsigned] long long [int] 在编写整型常量时,可以在常量的后面加上符号 L或者U来修饰 。
L 或者 l 表示该常量是长整型,U 或者 u 表示该常量为无符号整数。
LongNum = 100L; // L表示长整型UnsignNum = 25U; // U表示无符号整型整型常量可以通过3种形式进行表达,分别为八进制形式、十进制形式和十六进制形式。
八进制整数:要想所使用的数据表达形式是八进制,需要在常数前加上 0 作为前缀进行修饰,八进制所包含的数字为 0~7
十进制整数:不需要在常量前面加前缀,所包含的数字是 0~9
十六进制整数:在常量前加上 0x 作为前缀进行修饰,包含数字是 0~9 以及字母A~F(其中字母A~F可以是大写,也可以是小写)
//八进制num1 = 0123;num2 = 0456; //以下关于八进制的写法是错误的num3 = 145; //没有前缀num4 = 0489;//包含非八进制数8和9//十进制num1 = 123;num2 = 569;//以下关于十进制的写法是错误的num3 = 0156; //有前缀0,该数为八进制num4 = 0x156; //有前缀0x,该数为十六进制//十六进制num1 = 0x234;num2 = 0x4a5c;//以下关于十六进制的写法是错误的num3 = 158; //没有前缀0xnum4 = 0x95j4; //包含非十六进制数的字母j
浮点型(实型)
浮点型就是我们所说的小数类型,例如 -1.2,0.5,3.14,5.20等。
浮点型,也称为实型,分为单精度浮点型,双精度浮点型,长双精度浮点型。它们的精确范围由小到大。
float //单精度浮点型double //双精度浮点型long double //长双精度浮点型float :精确到小数点后 6 位
double : 精确到小数点后 15 位
long double : 精度通常至少与 double 相同,有时更高,取决于编译器和平台
由于这些类型有不同的存储大小和精度,因此在进行浮点数运算时,选择正确的类型是很重要的,如果你需要更高的精度,那么可以选择使用 double 或 long double。
在编写浮点型常量时,可以在常量后面加上符号 F 或 L 修饰。
F 或者 f 表示该常量是单精度浮点型,L 或者 l 表示该常量是长双精度浮点型
如果不在后面加上后缀,在默认状态下,该常量是 double 双精度类型
num1 = 3.12f; //float型num2 = 2.54; //double型num3 = 0.45L; //long double型浮点型由整数部分和小数部分组成。表示浮点型的方式有科学计数方式和指数方式
科学计数方式:使用十进制的小数方法。例如1.2,2.5
指数方式:使用字母 e 或者 E 进行指数显示 。例如12e2 , 56e-3
//科学计数法num1 = 2.1;num2 = .14; //可以省略整数部分,小数点前没有数字,这里就认为是 0.14//指数方式num1 = 1.52e3; //表示1520num2 = 2.8E-2;//表示0.028
字符型
字符型,是用来存储字符的,例如英文字母或标点等,严格来说,字符型其实也是整型,因为字符型数据存储的实际上是整数(字符的ASCII码值),而不是字符。例如ASCII用65代表大写字母A,因此存储字母A实际上存储的是整数65。ASCII码值后面会介绍。
char //character[signed] char //有符号的unsigned char //无符号的字符型常量分为字符常量和字符串常量。
字符常量:用单引号 ' ' 括起来的一个字符。例如 'A' , '#' , '='
字符串常量:用双引号 " " 括起来的若干字符序列。例如 "hello!", "am is are"
字符常量
1. 只能包括一个字符。例如 'A' 是正确的,'Ab'是错误的
2. 区分大小写。例如 'A' 和 'a' 是不一样的
3. 单引号 ' '代表定界符,不属于字符常量中的一部分
字符串常量
1. 如果字符串中一个字符都没有,称为空串,此时字符串中的长度为0
2. C语言存储字符串常量时,系统会在字符串的末尾自动加一个 " \0 " 作为字符串的结束标志
例如,字符串 "Hello" 在内存中的存储形式如下图

在编写字符串常量时,不必在一个字符串的结尾处 加上 " \0 "结束字符,系统会自动添加结束字符
 上面介绍了字符常量和字符串常量,那么同样是字符,它们之间有什么差别吗?
上面介绍了字符常量和字符串常量,那么同样是字符,它们之间有什么差别吗?
字符和字符串的区别:
使用的定界符不同。字符常量使用单引号 ' ',字符串常量使用双引号 " "长度不同。字符常量只有一个字符,那么长度就是1。字符串常量的长度却可以是0,即使字符串中只有一个字符,长度是2,不是1。因为字符串末尾还含有 \0 作为结束标志。存储方式不同。在字符常量中存储的是字符的ASCII码值,但在字符串常量中,不仅要存储有效的字符,还要存储结尾处的 \0
布尔类型(C99)
C语言中原本并没有为布尔值单独设置一个类型,而是使用整数0表示假,非零值表示真。
在C99标准中引入了布尔类型,专门用来表示真假
在布尔类型中,变量取值只有两种,要么是true,要么是false,不会出现第三种。
true 表示真 false 表示假
_Bool使用布尔类型,需要包含头文件 <stdbool.h>
我们在定义布尔类型时,可以将 _Bool 写为 bool,原因如下:
我们在VS2022上输入bool ,选中 bool 右击鼠标,点击转到定义
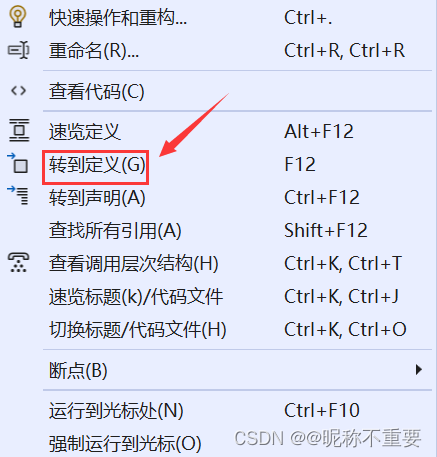
可以看到上面把 _Bool 定义为 bool , 所以 bool 等同于 _Bool

代码演示:
_Bool flag = true;if(flag) printf("为真");else printf("为假");
四、各种数据类型的长度
计算机的存储单位换算
计算机内部的数据以二进制表示,由0和1组成,逢二进一
计算机中最小的数据单位是 位(b),存储容量的基本单位是 字节(Byte),8个二进制位称为1个字节。
计算机中的数据大小通常以字节(Byte)作为基本单位

sizeof 操作符
sizeof 是一个关键字,也是一个操作符,是专门用来计算sizeof的操作数的类型长度的,单位是字节。
sizeof 的操作数可以是类型,也可以是变量或者表达式,如果是表达式,则括号可以省略
sizeof(类型)sizeof(表达式) //如果 sizeof 后面是表达式,可以省略括号sizeof 后面的表达式不真实参与运算,是根据表达式的类型来得出大小
sizeof 的计算结果是 size_t 类型的
sizeof 的返回值,C语言只规定是无符号整数,并没有规定具体的类型,而是留给系统自己决定,sizeof 返回什么类型呢?不同的系统中,返回值的类型可能是 unsigned int , 可能是 unsigned long , 也可能是 unsigned long long,对应的 printf( )的占位符分别是 %u 、%lu、%llu。这样不利于程序的可移植性。
所以C语言提供了一个解决方法,创造了一个类型别名 size_t ,用来统一表示 sizeof 的返回值类型。
例如下面的代码
int main(){int a = 5;printf("%zd\n", sizeof(a));printf("%zd\n", sizeof a); //a是变量的名字,可以省略sizeof后面的括号printf("%zd\n", sizeof(int)); printf("%zd\n", sizeof(2 + 1.5));return 0;}代码结果如下

a 的值是 5 ,而 5 是整型,int 占4个字节,所以输出 4
最后一个 2+1.5 中的 1.5 是 double 类型,double 占8个字节,所以输出 8,这里的2+1.5是不参与运算的
signed 和 unsigned
C语言使用 signed 和 unsigned 关键字来修饰字符型和整型。
signed:有符号的,表示这个类型带有正负号,包含负值
unsigned:无符号的,表示这个类型不带正负号,只能表示0和正整数
对于 int 类型 ,默认是带有正负号的,所以 int 就等同于 signed int
由于这是默认情况,所以 signed 一般都省略不写,写了也是正确的,不过稍微麻烦点
int //等同于 signed int当你使用的 int 类型表示 负整数 时,就必须使用关键字 unsigned 声明变量
unsigned int a = -1;
数据类型长度
我们了解了基本数据类型和 sizeof 的用处,接下来就是利用sizeof 来看看基本数据类型的长度
sizeof 可以获取特定类型或对象在内存中所占用的空间大小,单位是字节

我们可以看到这些基本数据类型的长度分别为1字节、1字节、2字节....
其中有一点,long 的存储范围比 int 更大,不应该是 long 的长度比 int 大吗? 为什么它们的长度都是4呢?
原因是:C语言标准规定 int 至少和 short 一样长,long 至少和 int 一样长,这个规则同样适用于浮点型,long double 至少和 double一样长,double 至少和 float 一样长。
然而,这并不意味着 long一定比 int 长或 int 一定比 short 长,它们之间的具体大小取决于编译器和平台。
sizeof(char) == 1sizeof(char) <= sizeof(short)sizeof(short) <= sizeof(int)sizeof(int) <= sizeof(long)sizeof(long) <= sizeof(long long)sizeof中的表达式不计算
#include<stdio.h>int main(){short a = 2;int b = 5;printf("%d\n", sizeof(a = b + 1));printf("a=%d\n", a);return 0;}我们第一反应可能会觉得结果分别是 4和6 ; 为什么第一反应会觉得是 4和6呢?因为a=b+1其中的b是int型,int占4个字节,而下面a=b+1,也就是a=5+1=6;其实这样是不对的
我们看看运行结果

第一个2:b是int型,占4个字节,而a是short型,占2个字节,把一个int型的值赋给short型,会发生数据截断,short 只有2个字节,你把空间占满了,也放不下4个字节,最终结果是short 所占的字节数2
第二个2:sizeof 中的表达式是不参与真实运算的,所以a还是第一次赋值的2
五、数据类型的取值范围
我们可以想想,整型只要一种不就好了吗,为什么会有short 、int、long、long long四种呢?
其实每一种数据类型都有自己的取值范围,有了这些丰富的类型,我们就可以根据取值范围在不同的场景下选择合适的类型。
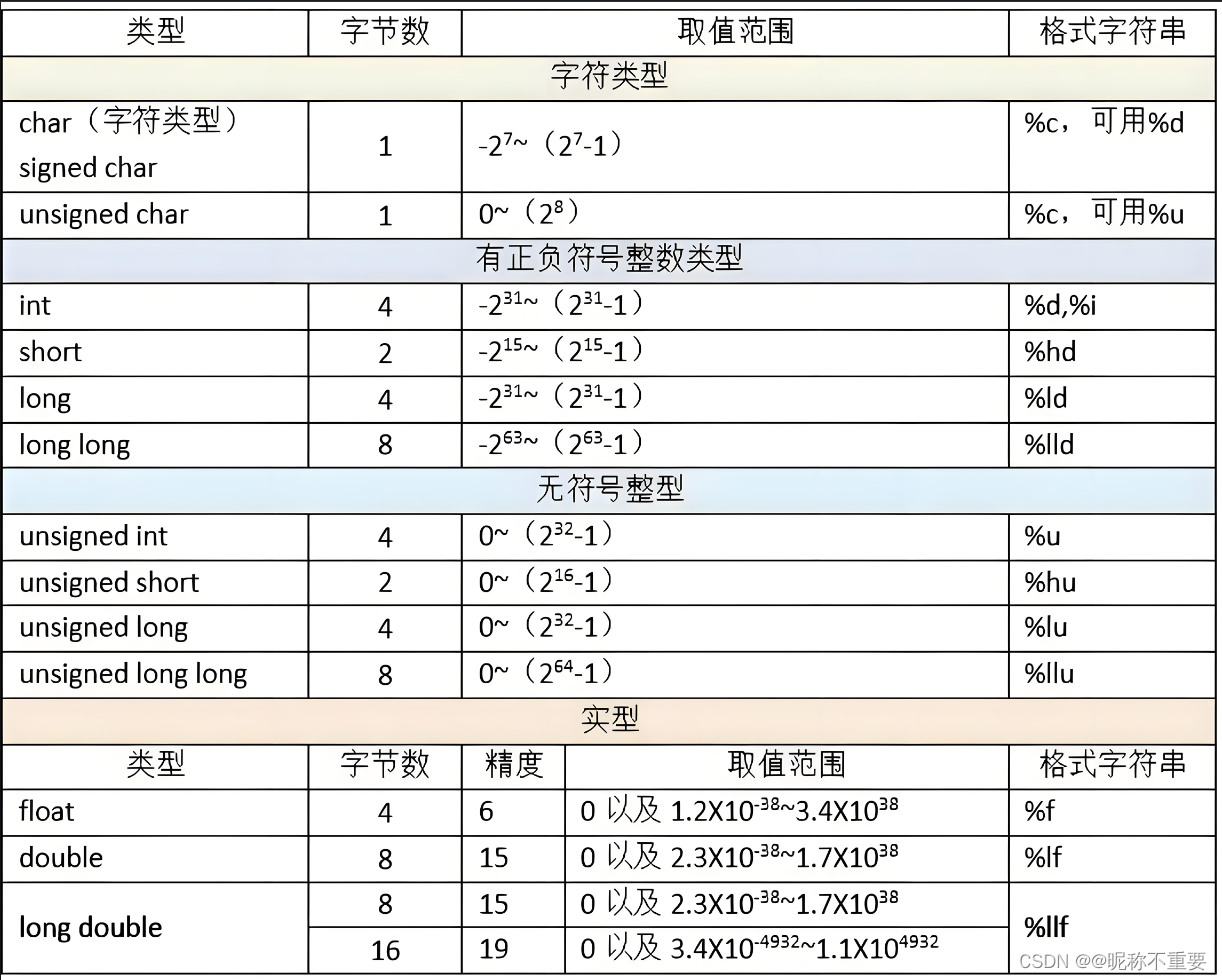
下图总结了基本数据类型所占字节数和取值范围。
_Bool (布尔类型)占 1 字节,取值范围:true 和 false
如果要查看当前系统上不同数据类型的极限值:
limits.h 文件中说明了整型的取值范围
float.h 文件中说明了浮点型的取值范围
下图为limits.h文件中定义的内容(摘取了部分)

如果你想使用极限值,又记不住极限值的具体数字,为了代码的可移植性,可以使用下面的常量 • SCHAR_MIN , SCHAR_MAX :signed char 的最小值和最大值 • SHRT_MIN , SHRT_MAX :short 的最小值和最大值 • INT_MIN , INT_MAX :int 的最小值和最大值 • LONG_MIN , LONG_MAX :long 的最小值和最大值 • LLONG_MIN , LLONG_MAX :long long 的最小值和最大值 • UCHAR_MAX :unsigned char 的最大值 • USHRT_MAX :unsigned short 的最大值 • UINT_MAX :unsigned int 的最大值 • ULONG_MAX :unsigned long 的最大值 • ULLONG_MAX :unsigned long long 的最大值
六、转义字符
转义字符:顾名思义,转变了原来的意思的字符,转义字符在字符常量中是一种特殊的字符。以反斜杠 “ \ ”开头,后面跟一个或几个字符。
在下面的代码中,打印 abcndef,原样输出

如果我们在 n 的前面加上反斜杠 “ \” ,结果会怎样呢?

我们可以看到加上反斜杠之后,不是输出 \n,而是进行了换行
转义字符如下表所示
| 转义字符 | 含义 | 描述 |
| \a | 响铃 | 使终端发出警报声或出现闪烁,或两者同时发生 |
| \b | 退格 | 光标回退一个字符 |
| \f | 换页 | 光标移到下一页 |
| \n | 换行 | 光标移到下一列开头 |
| \r | 回车 | 光标移到同一行的开头 |
| \t | 水平制表符 | 光标移到下一个制表位,一个制表位的长度通常是8 |
| \v | 垂直分割符 | 光标移到下一个垂直制表位,通常是下一行的同一列 |
| \' | 单引号 ' | |
| \" | 双引号 " | |
| \\ | 反斜杠 \ | |
| \? | 问号? | |
| \ddd | 1~3位八进制数所代表的字符 | 如 \130是八进制130,转换成十进制88,作为ASCII码值表示字符X |
| \xhh | 1~2位十六进制数所代表的字符 | 如 \x30是十六进制30,转换成十进制48,作为ASCII码值标识字符0 |
七、ASCII 码表
在计算机中所有的数据都是以二进制的形式存储的,那么字符是以什么样的二进制存储的呢?如果我们每个人都自己给这些字符编一个二进制序列(这个叫做编码)那不就乱套了吗?为了统一,不造成混乱,美国国家标准学会(ANSI)出台了一个标准ASCII码表。
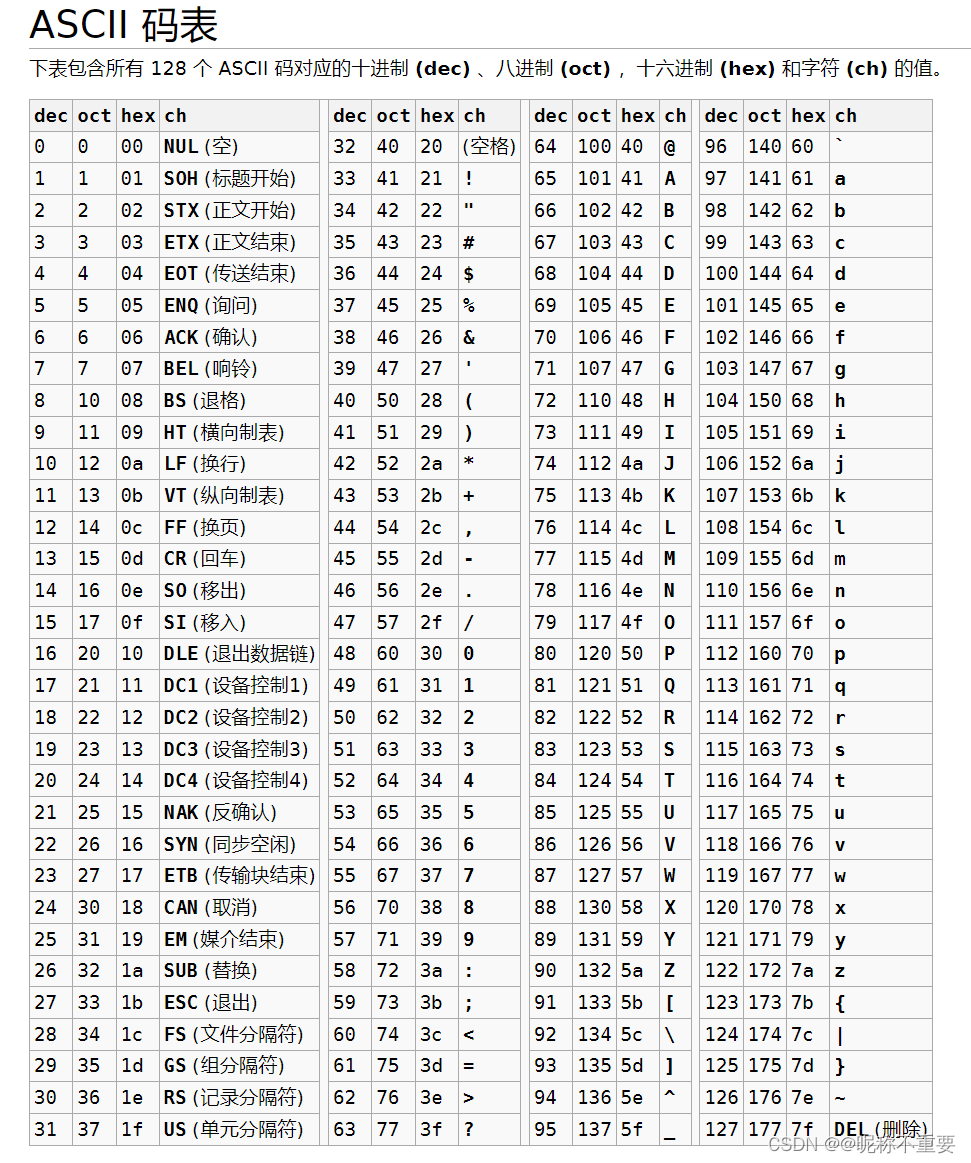
其中ASCII码值为0~31的这32个字符是不可打印字符
对于这张表,我们不需要全部记住,只需要记住下面的就可以
字符A~Z:65~90
字符a~z:97~122
对应的大小写字符的ASCII码值相差32(例如A是65,a是97,相差32)
数字字符0~9:48~57
换行\n:10
八、常量、变量
常量
常量就是其值在程序运行过程中不可以改变的。常量可以分为数值型常量(包括整型常量、浮点型常量)、字符型常量、符号常量。
整型常量:例如 1,5,14,100 等
浮点型常量:例如 0.0,1.5,3.14 等
字符型常量:例如 'A', '=', "hello" ,"am is are"等
上面的几种常量前文都已经介绍过,我们来看看符号常量
符号常量:使用一个符号名代替固定的常量值,这里使用的符号称为符号常量。
#include<stdio.h>#define NUM 5 // NUM是符号常量int main(){int a = 2;int sum = 2 + NUM;printf("%d\n", sum);}运行结果:

变量
经常变化的值叫做变量
变量的创建
前面介绍了类型,那么类型是用来干什么的?类型就是用来创建变量
变量创建的语法形式
data_type name; | | | | 数据类型 变量名变量在创建的时候给一个初始值,就叫做初始化
char ch = 'a';int age = 18;double score = 98.5;变量分为全局变量和局部变量
全局变量
在所有函数的外部声明的变量叫全局变量(这里先简单理解为在大括号外部声明的变量),顾名思义,全局变量在程序中的任何位置都可以使用。
局部变量
在一个函数的内部定义的变量叫局部变量(这里先简单理解为在大括号内部定义的变量),局部变量的使用范围比较局限,只能在自己的局部范围内使用。
在语句块里声明的变量仅在该语句块内部起作用,也包括嵌套在其中的子语句块。
#include<stdio.h>int a = 5; //全局变量int main(){int b = 2; //局部变量 { int c = 3; //局部变量 }return 0;}如果全局变量和局部变量名字相同呢?

我们可以看到结果输出a 是 2,用的是局部变量的值,那么也就可以得出一个结论
当全局变量和局部变量的名字相同时,局部变量会屏蔽全局变量,我们可以记为:两者相同时,局部优先
全局变量如果不初始化,默认为0
局部变量如果不初始化,默认为随机值

在VS下无法验证了,如果不初始化局部变量,VS直接不给通过,但在其他一些编译器下,不初始化局部变量,输出的会是随机值。
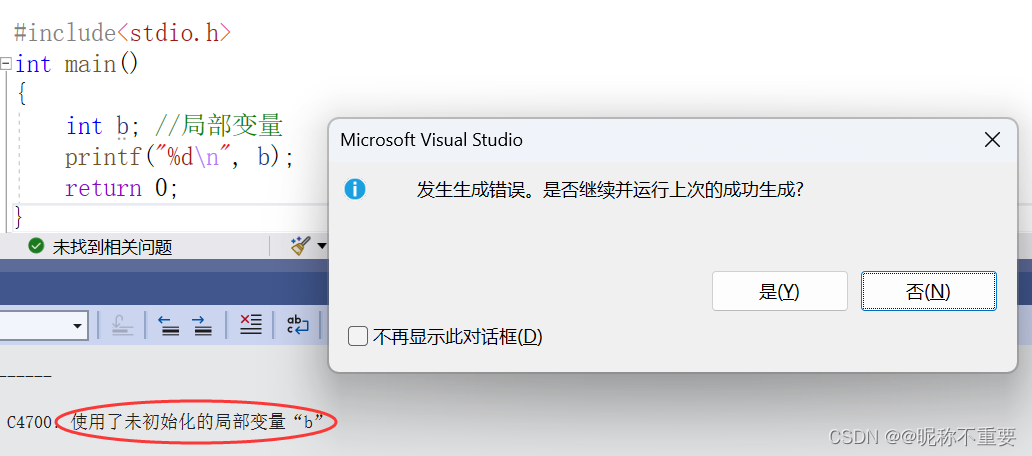
这就告诉我们,创建变量最好要初始化,初始化也会让我们更能掌控变量里的值,这是一个好的习惯。
全局变量和局部变量在内存中的存储
内存中有三个区域: 栈区、堆区、静态区
全局变量和局部变量在内存中存储在哪里呢?

局部变量放在内存的栈区
全局变量放在内存的静态区
堆区是用来进行动态内存管理的
其实内存区域的划分会更加细致,这里先做大概了解。
那么写到这里,本节内容就结束了,这篇博客花费了很长时间,但写完有满满的成就感,希望能帮助到大家,如果文章有不足的地方,欢迎在评论区留言指正,我们一起学习交流!
希望能得到大家的关注、点赞、评论、收藏!你的支持是我最大的动力!!

