一、前言
本文将介绍如何利用python来根据文本数据(.txt文件)绘制词云图,除了绘制常规形状的词云图(比如长方形),还可以指定词云图的形状。
二、相关库的介绍
1、安装相关的库
pip install jiebapip install matplotlibpip install wordcloudpip install numpypip install Image 2、 导入相关的库
import jiebaimport matplotlib.pyplot as pltfrom wordcloud import WordCloudimport numpy as npfrom PIL import Image # 图像处理3、 相关库的介绍
jieba:
结巴分词库,一个中文分词库。由于中文文本的每个汉字都是连续书写的,因此需要对文本进行分词来获得中文文本的每个词组,即分词。
matplotlib.pyplot
图像展示库。用来创建画布以及相关的图像展示。在绘图前,需要创建一个figure对象,即需要一张画板才能开始绘图。
wordcloud :
词云展示库,可以根据文本的词频,对内容进行词云图的可视化。
numpy
numpy是Python的一个开源的数值计算扩展库,主要用于处理大型多维数组和矩阵,以及进行高效的数学运算,广泛应用于数据分析、机器学习、信号处理等领域。
Image
Image模块是一个强大的图像处理工具,提供了对图像文件的读写和处理的功能。也提供了各种功能和方法来处理和操作图像,包括加载、保存、调整大小、旋转、裁剪、应用滤镜等。
三、数据处理
1、中文分词
中文分词可以将中文语句切割成单独的词组;中文分词的工具有很多,比如 python 的第三方库 jieba;jieba 支持三种分词模式:全模式、精确模式、搜索引擎模式。结巴分词最主要的方法是 cut 方法
(1)精确模式
试图将句子最精确地切开,适合文本分析结巴分词默认为该模式jieba.cut("文本内容",cut_all=False)(2)全模式
把句子中所有可以成词的词语都扫描出来,速度很快,但是不能解决歧义jieba.cut("文本内容",cut_all=True)(3)搜索引擎模式
在精确模式的基础上,对长词再次切分,提高召回率2、去除停用词
对中文来说,包括像“的”、“和”、“在”、“是”等副词、量词、介词、叹词、数词都是停用词。这些词汇几乎在所有中文文本都会出现,不具有特殊性,没有区分度,所以通常会把这些词从文本中去除;去除停用词需要一个停词表stopword.txt,将分词后的文本中每个词与停词字典中的条目进行匹配。如果匹配成功,该词将被删除;直接百度搜索停词表并下载就好了(由于本文用到的数据集的文本内容比较简单,因此没有执行去除停用词这一步的操作)
四、实现
1、绘制基本词云图
(1)核心
在以下代码中,根据实际更改文件的读取路径以及保存路径即可:
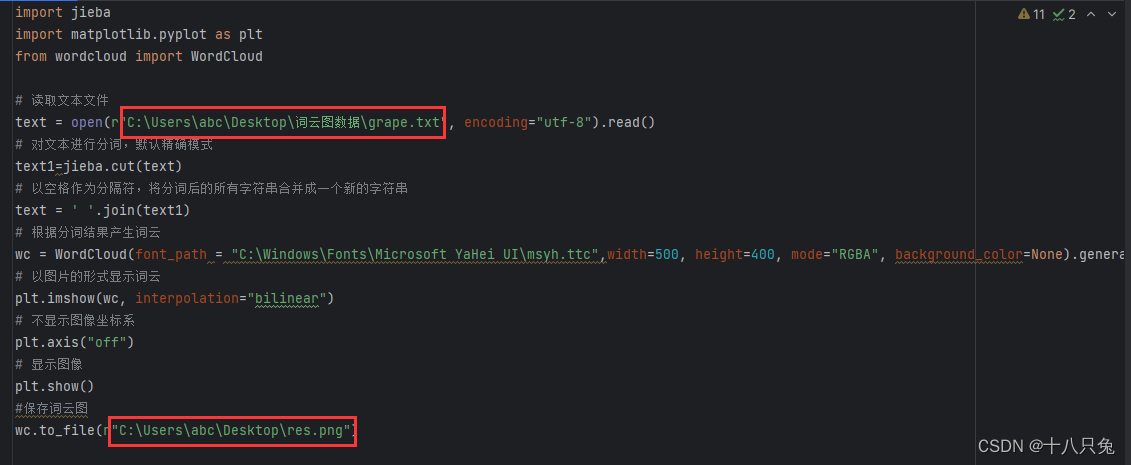
(2)WordCloud 参数解释
参数解释| 参数 | 解释 |
|---|---|
| width | 词云图的宽度(默认400像素) |
| height | 词云图的高度(默认200像素) |
| max_font_size | 词云图字体的最大字号(根据图片高度自动调节) |
| min_font_size | 词云图字体的最小字号(默认为4号字体) |
| max_words | 词云图显示的最大单词数(默认200) |
| stop_words | 不显示的词语、单词 |
| mask | 指定词云图的形状(默认为长方形) |
| background_color | 词云图的背景颜色(默认为黑色) |
| font_path | 字体文件的路径 |
font_path = "C:\Windows\Fonts\Microsoft YaHei UI\msyh.ttc"(3)完整代码:
import jiebaimport matplotlib.pyplot as pltfrom wordcloud import WordCloud# 读取文本文件text = open(r"C:\Users\abc\Desktop\词云图数据\grape.txt", encoding="utf-8").read()# 对文本进行分词,默认精确模式text1=jieba.cut(text)# 以空格作为分隔符,将分词后的所有字符串合并成一个新的字符串text = ' '.join(text1)# 根据分词结果产生词云wc = WordCloud(font_path = "C:\Windows\Fonts\Microsoft YaHei UI\msyh.ttc",width=500, height=400, mode="RGBA", background_color=None).generate(text)# 以图片的形式显示词云plt.imshow(wc, interpolation="bilinear")# 不显示图像坐标系plt.axis("off")# 显示图像plt.show()#保存词云图wc.to_file(r"\Users\abc\Desktop\res.png")
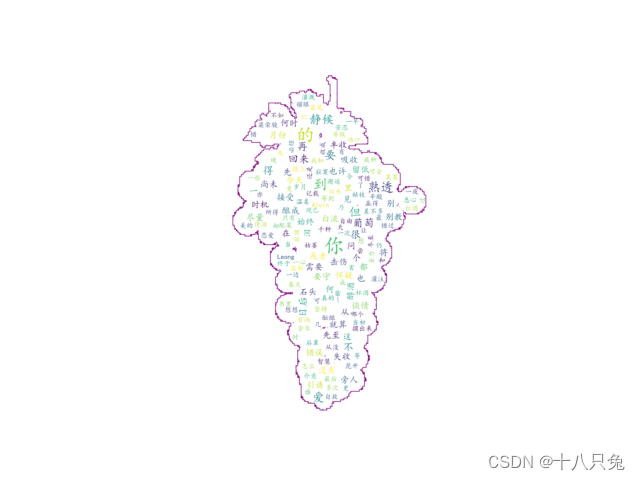
2、绘制指定形状的词云图
有时候需要指定词云图的形状,我们可以通过导入背景图片作为词云图的底图来实现注意:背景图片的背景一定要是白色的,不可以是其他颜色或者透明以下面的葡萄图片作为背景图片:
(1)核心代码
需要使用numpy库以及Image库来对背景图片进行图像处理
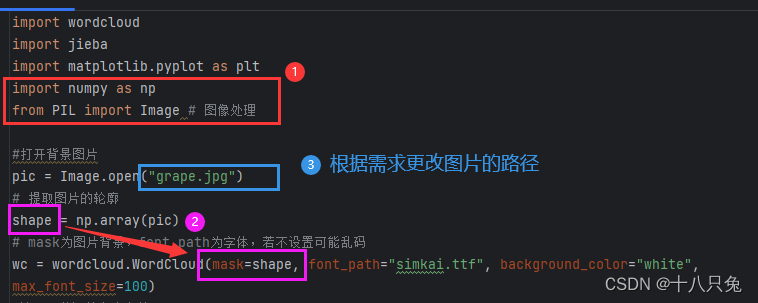

(2)词云图优化
我们可以给背景图的轮廓进行清晰化,比如给轮廓添加粗度和颜色
(3)完整代码:
import wordcloudimport jiebaimport matplotlib.pyplot as pltimport numpy as npfrom PIL import Image # 图像处理#打开背景图片pic = Image.open("grape.jpg")# 提取图片的轮廓shape = np.array(pic)# mask为图片背景,font_path为字体,若不设置可能乱码wc = wordcloud.WordCloud(mask=shape, font_path="simkai.ttf", background_color="white", contour_color='purple',contour_width=3,max_font_size=100)#读取要分词的文本文件text = open(r'C:\Users\abc\Desktop\词云图数据\grape.txt', "r", encoding='UTF-8').read()#结巴分词cut_text = jieba.cut(text)result = " ".join(cut_text)#生成词云图wc.generate(result)#保存词云图wc.to_file("cloud.jpg")# 以图片的形式显示词云plt.imshow(wc, interpolation="bilinear")# 不显示图像坐标系plt.axis("off")# 显示图像plt.show()