
作者 | 王启隆
责编 | 唐小引
出品 | AI 科技大本营(ID:rgznai100)
从今年 2 月,OpenAI 用一个意为“天空”的日语词汇“Sora”引爆了技术圈,并为视频生成技术立下了一道新标杆:将简短的文本描述转换成一分钟的高清视频片段。随后的两个月里,各路神仙试图从“CloseAI”的各类发布渠道中捕捉 Sora 零碎的研究细节,时至今日仍未降温。
这期间,北京大学和兔展智能在三月份联合发起了开源项目 Open-Sora-Plan ,旨在通过开源框架重现 Sora,训练一个包含无条件视频生成、类视频生成和文本、视频生成等技术的模型。
就在昨天,Open-Sora-Plan v1.0.0 正式推出,显着增强了视频生成质量和文本控制功能,并且正在训练更高分辨率(>1024)以及更长持续时间(>10 秒)的视频。一个月的变化非常大,Open-Sora-Plan 如今采用 CausalVideoVAE 架构,支持华为升腾 910b 芯片,在 Hugging Face 上已有 Demo。
GitHub 链接:https://github.com/PKU-YuanGroup/Open-Sora-Plan
Hugging Face 在线演示:https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.0.0
以上两个视频为 Open-Sora-Plan 项目训练的 Video-VAE 重建结果

复现细节
Open-Sora-Plan 的技术框架在项目公布时便已经定下,由三大部分组成:
Video VQ-VAE.
全称 Video Vector-Quantized Variational Autoencoder,结合了变分自编码器(VAE)和矢量量化(Vector Quantization, VQ)的概念,是一种针对视频数据的编码-解码模型,用于压缩和重建视频序列。
Denoising Diffusion Transformer.
Denoising 意指去噪自编码器(Denoising Autoencoders)。Diffusion Transformer 通常简称 DiT,翻译过来就是“扩散 Transformer”,被视为 Sora 的重要技术基础之一,在 Sora 出圈时还带火了论文的合撰者谢赛宁。
这种模型通常用于从噪声逐渐重构原始数据的过程中,通过一系列逐步去噪步骤生成高保真样本,特别是在图像和视频生成场景中表现出色。
Condition Encoder.
即条件编码器。这是在生成过程中引入外部条件信息的关键组件,它可以将各种类型的输入条件(如文本描述、标签、类别或其他辅助信息)转化为模型可以理解的高级特征表示。
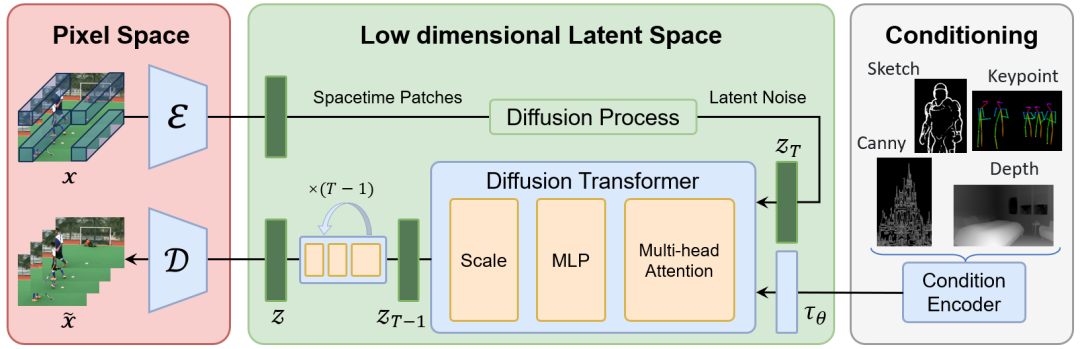
而本次 v1.0.0 版本的发布的主要改进,便是能够利用 CausalVideoVAE 实现高效训练和推理,通过 4×8×8 的空间-时间压缩优化视频数据处理,并将首帧视为图像,允许自然地同时对图像和视频进行编码,从而让扩散模型更好地捕捉空间视觉细节,提高视觉质量。
模型结构
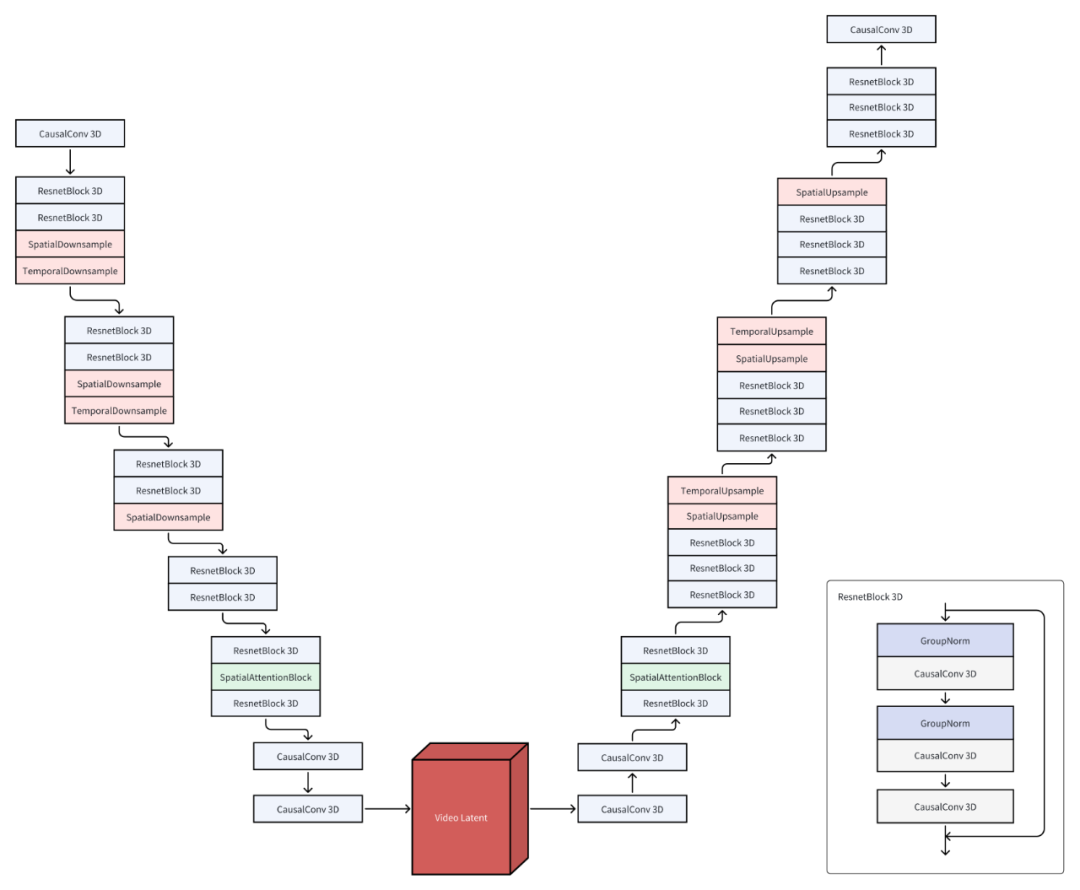
CausalVideoVAE 的结构基于 Stable-Diffusion Image VAE,在 Stable Diffusion 中使用 VAE 能够得到颜色更鲜艳、细节更锋利的图像,同时也有助于改善脸和手等部位的图像质量。为了让图像 VAE 的预训练权重顺利地用在视频 VAE 上,Open-Sora-Plan 的团队做了以下设计:
CausalConv3D:将 Conv2D 转换成 CausalConv3D 可以同时训练图像和视频数据。CausalConv3D 对第一帧进行了特殊处理,因为它无法获取到后续帧。
初始化:将 Conv2D 扩展成 Conv3D 有两种常见的方法,一是平均初始化,二是中心初始化。Open-Sora-Plan 采用了一种特殊的初始化方法(尾部初始化)。这种初始化方法可以让模型在没有任何训练的情况下,直接重建图像,甚至视频。
训练细节
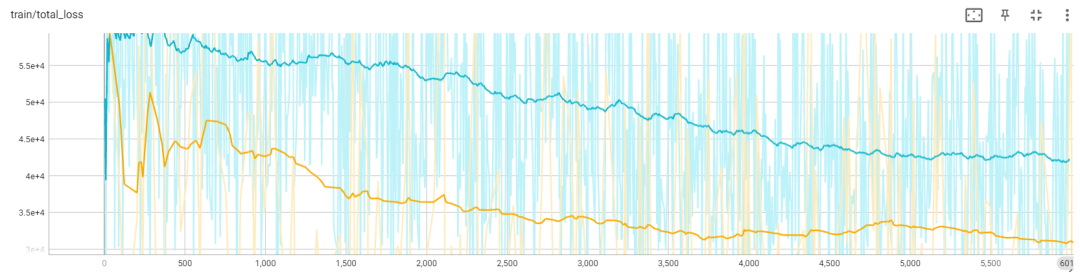
上图展示了两种不同初始化方法在 17×256×256 图像上的损失曲线。
黄色曲线表示使用尾部初始化的损失,蓝色曲线对应中心初始化的损失。从图上可以看出,尾部初始化在损失曲线上表现更好。此外,研究团队发现中心初始化会导致错误积累,导致长时间的崩溃。
优化推理
即使冻结 Diffusion 训练中的 VAE,CausalVideoVAE 的成本还是会比较高。具体来说,在 Open-Sora-Plan 团队现有配备的 80GB GPU 内存的情况下,仅能使用半精度处理分辨率分别为 256×512×512 或 32×1024×1024 的视频进行推理,这限制了他们对更长和更高分辨率视频进行扩展的能力。
因此,他们采用了瓦片卷积(tile convolution),以几乎恒定的内存使用量推断任意长度或分辨率的视频。
数据构建
Open-Sora-Plan 团队构建了一个高品质视频数据集,其严格遵守两个原则:
首先,确保数据集中不包含任何与内容无关的水印。为此,他们从一系列 CC0 许可的开源网站搜集了大约 40,000 个视频资源,其中包括从 mixkit 获得的 1,244 个视频、从 pexels 获取的 7,408 个视频以及从 pixabay 收集的 31,617 个无水印视频。按照 Panda70M 提供的场景切换和剪辑方案,这些原始视频被细分为约 434,000 个独立的视频片段。
这批数据来源高达 99% 的视频都仅包含单一场景,同时超过 60% 的爬取数据属于风景类视频内容。
其次,针对高质量且密集的字幕要求,直接在网络上大规模抓取此类字幕颇具挑战性。团队于是决定采用先进的图像-字幕模型来生成高标准的字幕内容,对两款多模态大模型——ShareGPT4V-Captioner-7B 和 LLaVA-1.6-34B 进行了消融实验。前者专为字幕生成任务设计,后者则是一款通用的大型多模态模型。
实验结果显示两者性能相当,但推理速度有所差异:在 A800 GPU 上,ShareGPT4V-Captioner-7B 以批处理大小 12 的情况下,每 40 秒能完成一轮推理;而 LLaVA-1.6-34B 在批处理大小 1 时,每 15 秒即可进行一轮推理。团队已公布所有相关注释*,并展示了部分统计数据,在设定模型最大长度为 300 的前提下,这几乎覆盖了 99% 的样本需求。

*: https://huggingface.co/datasets/LanguageBind/Open-Sora-Plan-v1.0.0
未来……
关于 CausalVideoVAE 模型:面对存在的动态模糊和网格效应问题,他们正在进行一系列改进措施,即将推出的增强版本作为“预览版”,预计在下一次更新时正式发布。Open-Sora-Plan 团队同样放出了新版本预览,提升很大:
关于数据构建的源头:上文提到,“60% 的爬取数据属于风景类视频内容”,这在一定程度上限制了在其他类型视频生成上的表现力。尽管现有的大规模开源数据集多数通过抓取 YouTube 等平台获取,但由于对视频质量控制的考量,Open-Sora-Plan 团队选择持续积累高质量的数据资源。他们正发起名为 Open-Sora-Dataset 的项目,并邀请开源社区共同参与推荐和建设。
关于字幕生成流程:鉴于长视频的需求,有必要研发更为高效的视频字幕生成解决方案,而不完全依赖于大型多模态图像模型。目前,他们正致力于开发新一代视频字幕生成管道,旨在提供对长视频强大而稳定的支持。
关于算力:项目发起者之一、北大信息工程学院助理教授、博导袁粒向 CSDN 透露,针对如何更好地支持国产算力训练的问题,当前主要与华为开展了深度合作,并与其他诸如摩尔线程等国产算力平台进行接触。尽管各家企业在推进合作的进度和流程上存在差异,每家企业的节奏各异,但合作的基本思路是相通的。


星星之火可以燎原
你是如何理解开源精神的?
是 BSD 开花结果孕育 Mac OS X 和 Unix-like?还是 MySQL 在被 Oracle 收购之后催生了 MariaDB 等一系列数据库?亦或是 Netscape 被微软逼入绝境后,开源 Mozilla 项目涅槃重生?
袁粒向 CSDN 表示,Open-Sora-Plan 项目的追求既非完全复现 Sora,更不是要抢先于 OpenAI 实现“弯道超车”,而是「开源」这件事情本身。
“我们追求的还是开源。开源社区本身的资源是有限的,我们能做的并不是超越,而是给大家提供一个开源版本,大家可以基于此继续往前推动。”

目前,开源社区对 Open-Sora-Plan 的回馈相当热情,GitHub 上已有 6.7 stars。袁粒认为,开源社区里不只有个人开发者,许多企业也正在支持开源,他们本身也是开源的一份子,有许多开发者和企业都为 Open-Sora-Plan v1.0.0 的算力&算法提供了支持。此外,华为也在持续跟进该项目,他们表示完全尊重开源,并有工程师协助袁粒的团队做适配。
Open-Sora-Plan 团队计划以自身开源为核心,鼓励合作企业不仅支持开源,具体的协作模式是开放且灵活的:各个国内企业都可以针对开源项目提交 Pull Request(PR)对现有框架进行适配以适应国产算力平台。团队会对提交的代码进行审核,确认无误后将其融入到开源框架中。在适配过程中遇到的技术问题,团队会与合作企业保持紧密沟通,共同寻求解决方案,确保国产算力与开源框架的有效整合与兼容。
通过各方共同努力,逐步建立起一套基于国产算力环境的开源生态体系。

截至 4 月 8 日,Open-Sora-Plan 的社区贡献者
开源之火,生生不息。
去年 12 月的时候,Linus Torvalds 在日本的开源峰会上曾作出如此分享:
“我还记得三十年前我启动这个项目(Linux)时的情景,人们会问我'为什么'或'你要怎么赚钱?' 现在,这已经不再是一个问题了。开源已经成为行业的标准。”
GitHub 链接:https://github.com/PKU-YuanGroup/Open-Sora-Plan
Hugging Face 在线演示:https://huggingface.co/spaces/LanguageBind/Open-Sora-Plan-v1.0.0

Open-Sora-Plan 团队

4 月 25 ~ 26 日,由 CSDN 和高端 IT 咨询和教育平台 Boolan 联合主办的「全球机器学习技术大会」将在上海环球港凯悦酒店举行,特邀近 50 位技术领袖和行业应用专家,与 1000+ 来自电商、金融、汽车、智能制造、通信、工业互联网、医疗、教育等众多行业的精英参会听众,共同探讨人工智能领域的前沿发展和行业最佳实践。欢迎所有开发者朋友访问官网 http://ml-summit.org、点击「阅读原文」或扫码进一步了解详情。
