一、 netCDF4的下载注意事项及whl链接
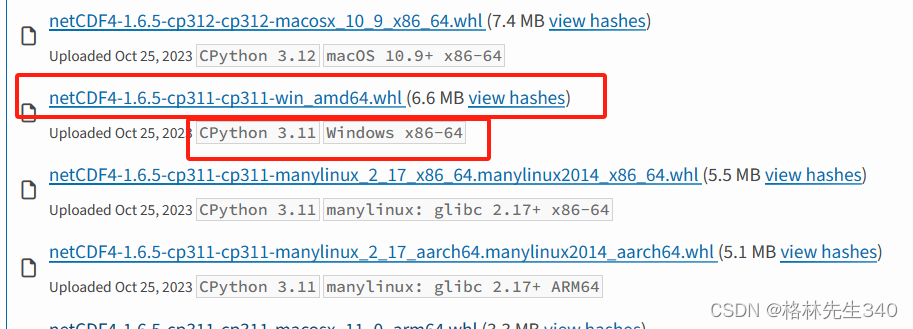
①首先需要在网上下载相应whl的安装包
(注意:一定要保证版本与Python解释器版本一致,比如我的解释器是3.11版本,电脑是windows64位的系统,那么就选择netCDF4-1.6.5-cp311-cp311-win_amd64.whl进行下载)
在网上看到过一些下载地址,但是好多没法用,这里提供一个,不需要梯子:
https://pypi.org/project/netCDF4/
②安装netCDF4
将下载好的whl文件放在其他的下载Python包放置的目录下,而后win+R进入DOS命令窗口输入如下命令进行安装
pip install netCDF4-1.6.5-cp311-cp311-win_amd64.whl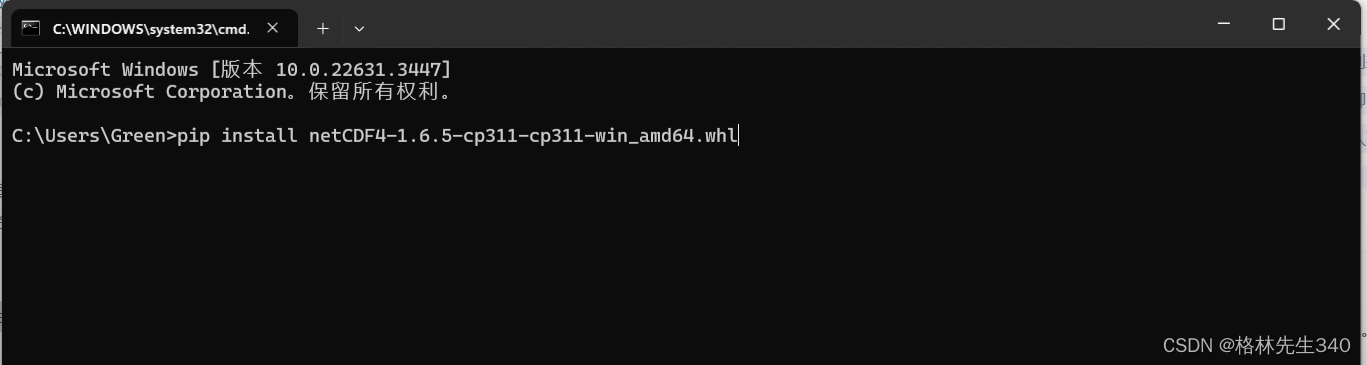
https://pypi.tuna.tsinghua.edu.cn/simple二、代码内容
①数据准备:2010年nc数据文件夹,在其中包含3个子文件夹,每个文件夹中包含有若干nc文件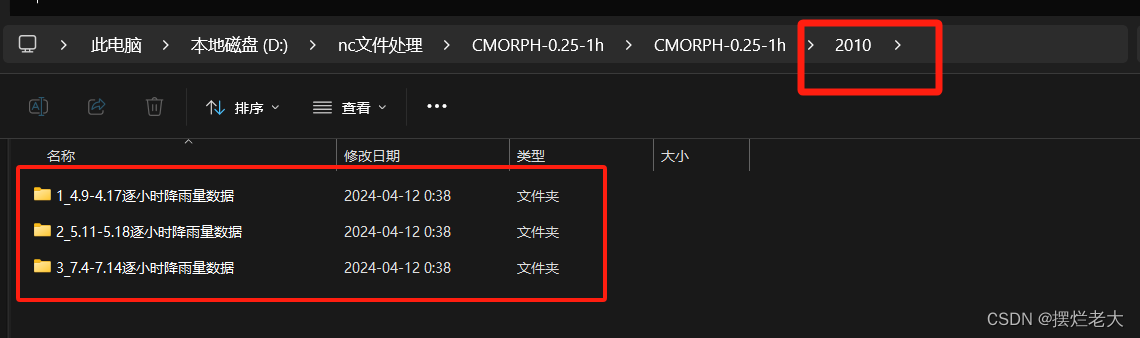
②代码介绍:
首先,我们要看一下这些nc文件里都有什么东西:
import netCDF4 as ncimport numpy as np #后续寻找合适经纬度的索引需要用到#获取相应nc数据的值nf = nc.Dataset(r'D:\nc文件处理\CMORPH-0.25-1h01\2010\CMORPH_V1.0_ADJ_0.25deg-HLY_2010040900.nc',encoding='gbk')#输出nc数据的相应含义print(nf.variables.keys())显示数据元素分别有:时间、时间范围、纬度、纬度范围、经度、经度范围、降水量。
而后,我们查看时间的具体内容:
print(nf.variables['time'][:])显示数据是以秒(seconds)计的,是从1970年1月1日0时以来的秒数。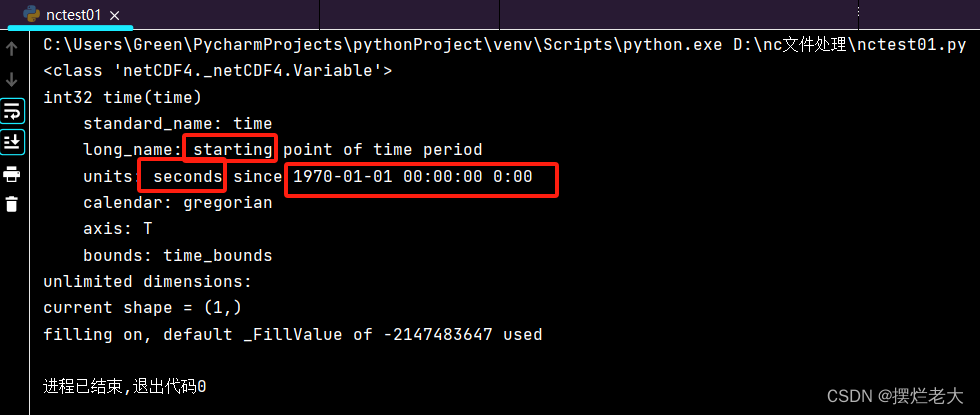
所以需要将数据转化为更直观更可读的形式:
time = nc.num2date(nf.variables['time'][:],'seconds since 1970-01-01 00:00:00').data最后,因为一幅nc数据只有一个时间,所以我们用索引0来读取其具体值,我们再输出可以发现,时间格式已经可以直观判断了:
print(time[0])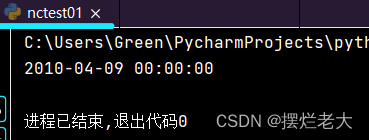
# 建立2个空列表,用于存放符合条件的经纬度的位置lst_wherelat=[]lst_wherelon=[]# 循环遍历所有纬度for i in range(len(var_data_lat)): # 要满足纬度范围26°06′N——27°24′N if var_data_lat[i] >= 26.1 and var_data_lat[i] <= 27.4: # 检索符合要求的纬度在数组中的位置,并添加到列表中 lst_wherelat.append(np.where(var_data_lat == var_data_lat[i]))# 循环遍历所有经度for j in range(len(var_data_lon)): # 要满足经度范围116°18′E——117°48′E if var_data_lon[j] >= 116.3 and var_data_lon[j] <= 117.8: # 检索符合要求的经度在数组中的位置,并添加到列表中 lst_wherelon.append(np.where(var_data_lon == var_data_lon[j]))print(lst_wherelat)print(lst_wherelon)# 检查第一个符合条件的纬度位置# where返回的是元组,元组中的元素是数组,数组中的元素是符合条件的位置# 所以两个0表示取出数组,再取出数组中的第一个元素print(lst_wherelat[0][0])
我们需要记住起始位置和结束位置(纬度:344、349;经度:465、470)
以便后续使用,把符合要求的经纬度确定下来,这样就不用每次都遍历所有经纬度了
(我们也可以直接把列表中的个元素提取到新的列表里,后续直接以此进行for循环,这里不做介绍)
下面是后续批量提取的代码,我们的格式以“行代表纬度”、“列代表经度”、“值字段是降雨量”、“sheet名以时间来命名”、“一个表里每个sheet对应一个时间”为例进行编写
import osimport pandas as pdfrom netCDF4 import Datasetimport netCDF4 as nc# 定义文件夹路径和命名Excel文件名称folder_path = r'D:\nc文件处理\CMORPH-0.25-1h01\2010'# 遍历指定文件夹下的所有子文件夹,并将它们的完整路径收集到一个列表中subfolders = [f.path for f in os.scandir(folder_path) if f.is_dir()]# 对于subfolders列表中的每个元素(即每个子文件夹的路径),执行一次循环。for i, subfolder in enumerate(subfolders): # 从子文件夹路径中提取前12个字符(洪水场次号_起始月日-终止月日)作为文件名 file_name = os.path.basename(subfolder)[:12] + ".xlsx" #将当前工作目录和指定的文件名 file_name 连接起来,形成一个完整的文件路径 file_name = os.path.join(os.getcwd(), file_name) # Use os.path.join to handle paths# 创建一个新的 ExcelWriter 对象 writer = pd.ExcelWriter(file_name, engine='xlsxwriter') # 获取子文件夹中的所有 NetCDF 文件 nc_files = [os.path.join(subfolder, f) for f in os.listdir(subfolder) if f.endswith('.nc')] # 循环遍历每个nc文件 for nc_file in nc_files: # 打开nc文件 nf = Dataset(nc_file, encoding='gbk') var_data_time = nc.num2date(nf.variables['time'][:], 'seconds since 1970-01-01 00:00:00').data # 获取变量的数据 var_data_lat = nf.variables['lat'][:].data var_data_lon = nf.variables['lon'][:].data var_data_cmorph = nf.variables['cmorph'][:].data # 提取数据 lst = [] # 循环所有经度 # 注意:为什么先循环经度? # 这是因为这样就可以保证1个经度值对应6个纬度值,方便后续二维表的创建 for i in range(464,471): #range(start,stop),从start数据开始,末位数据不包含stop # 我要循环所有纬度 for j in range(344, 350): lst.append(var_data_cmorph[0, j, i]) # 创建 DataFrame data = pd.DataFrame({'116.375': lst[6:12], '116.625': lst[12:18], '116.875': lst[18:24], '117.125': lst[24:30], '117.375': lst[30:36], '117.625': lst[36:42]}) # 添加纬度列 data[''] = ['26.125', '26.375', '26.625', '26.875', '27.125', '27.375'] # 使用 insert() 方法将新列插入到指定位置(在第一列位置) data.insert(0, '', data.pop('')) sheet_names = [str(dt).replace(':', '_').replace(' ', '_') for dt in var_data_time] # 将 DataFrame 写入 Excel 的不同 sheet 中 data.to_excel(writer, sheet_name=sheet_names[0], index=False) # 关闭nc文件 nf.close() # 保存并关闭ExcelWriter对象 writer.save() writer.close()运行之后会弹出类似于( FutureWarning: save is not part of the public API, usage can give unexpected results and will be removed in a future version writer.save())的警告,不用担心,这是在说writer.save()这个方法即将淘汰,但是Excel文件会正常生成在代码所在的同一个文件夹里。
打开Excel文件发现格式符合要求:
以上是全部内容,初次创作,欢迎大家评论区留言、批评指正。