此次练习中,我们使用Human Activity Recognition Using Smartphones数据集。它通过对参加测试者的智能手机上安装里一个传感器而采集了参加测试者每天的日常活动(ADL)。目标是将日常活动分成六类(walking, walking upstairs, walking downstairs, sitting, standing, and laying)。
该数据集也可以在Kaggle网站上获得:https://www.kaggle.com/uciml/human-activity-recognition-with-smartphones/downloads/human-activity-recognition-with-smartphones.zip
把训练文件重新命名为 Human_Activity_Recognition_Using_Smartphones_Data.csv
第一步:导入数据
查看数据类型—因为有太多的列,所以最好使用value_counts判断其中的小数数值是否需要尺度缩放检查数据中各活动类型的划分把活动类型标签编码成一个整数import pandas as pdimport numpy as npfilepath = 'Human_Activity_Recognition_Using_Smartphones_Data.csv'data = pd.read_csv(filepath)所有列的数据类型都是浮点数,除了活动标签列。
data.dtypes.value_counts()float64 561int64 1object 1dtype: int64data.dtypes.tail()angle(X,gravityMean) float64angle(Y,gravityMean) float64angle(Z,gravityMean) float64subject int64Activity objectdtype: object数据都已经全部被缩放到-1到1之间了。
data.iloc[:, :-1].min().value_counts()-1.000000 466-0.995377 2-0.999996 2-0.999893 2-1.000000 2 ... -0.999983 1-0.943439 1-0.998014 1-0.999915 1 1.000000 1Length: 93, dtype: int64data.iloc[:, :-1].max().value_counts()1.000000 4520.994731 20.805064 10.908361 10.891736 1 ... 0.990935 10.979031 10.928416 10.848031 130.000000 1Length: 110, dtype: int64检查数据中各活动类型的划分—已经比较平衡了。
data.Activity.value_counts()LAYING 1407STANDING 1374SITTING 1286WALKING 1226WALKING_UPSTAIRS 1073WALKING_DOWNSTAIRS 986Name: Activity, dtype: int64Scikit learn的分类器不接受一个稀疏矩阵作为预测列。所以,可以使用LabelEncoder将活动标签编码为整数。
from sklearn.preprocessing import LabelEncoderle = LabelEncoder()data['Activity'] = le.fit_transform(data.Activity)data['Activity'].sample(5)2098 15517 16369 02210 54029 1Name: Activity, dtype: int32第二步:划分训练数据和测试数据
可以考虑使用Scikit-learn中的StratifiedShuffleSplit,以保证划分后的数据集中每个类别个案的比例与整个数据集相同。 feature_cols = data.columns[:-1]from sklearn.model_selection import StratifiedShuffleSplit# Get the split indexesstrat_shuf_split = StratifiedShuffleSplit(n_splits=1,test_size=0.3, random_state=42)train_idx, test_idx = next(strat_shuf_split.split(data[feature_cols], data.Activity))# Create the dataframesX_train = data.loc[train_idx, feature_cols]y_train = data.loc[train_idx, 'Activity']X_test = data.loc[test_idx, feature_cols]y_test = data.loc[test_idx, 'Activity']y_train.value_counts(normalize=True)0 0.1914112 0.1869411 0.1748933 0.1667315 0.1459394 0.134085Name: Activity, dtype: float64y_test.value_counts(normalize=True)0 0.1912962 0.1867631 0.1749773 0.1668185 0.1459664 0.134180Name: Activity, dtype: float64第三步:训练模型
用所有特征训练一个基本的使用缺省参数的逻辑回归模型。分别用L1和L2正则化来训练一个模型,使用交叉验证确定超参数的值。注意,正则化模型,尤其是L1模型可能需要一定训练时间。# 请在此处填写你的代码(训练一个基本的使用缺省参数的逻辑回归模型)from sklearn.linear_model import LogisticRegressionlr = LogisticRegression(C=1e9)lr.fit(X_train, y_train)y1_pred_class = lr.predict(X_test)from sklearn.linear_model import LogisticRegressionCV# L1 正则化的逻辑回归lr_l1 = LogisticRegressionCV(Cs=10, cv=4, penalty='l1', solver='liblinear').fit(X_train, y_train)# 请在此处填写你的代码(L2 正则化的逻辑回归)lr_l2 = LogisticRegressionCV(Cs = 10, cv = 4, penalty = "l2", solver = "liblinear").fit(X_train, y_train)第四步:
输出上面训练出的三个模型中每个特征的系数;并绘制成图来比较它们的差异 (每个类别一张图)# 请在此处填写你的代码(输出各模型训练到的特征系数值)print("lr_coef_:", lr.coef_)print("lr_l1_coef_:", lr_l1.coef_)print("lr_l2_coef_:", lr_l2.coef_)lr_coef_: [[-4.12196415e-01 5.06623963e-02 2.03181674e-01 ... -2.54567346e+00 -1.26940147e+00 -1.09109777e+00] [-1.97604207e-01 4.95823843e-02 1.21677586e-01 ... -1.58853770e+00 -5.62850705e-01 -7.64842812e-01] [-6.81924154e-02 -1.37914996e-03 -2.55900298e-04 ... 2.33229351e+00 4.40336018e-01 -8.25917629e-01] [ 1.07887742e-01 -5.50986235e-02 -7.41960666e-02 ... 4.70983186e-01 4.47067484e-01 9.09309679e-01] [ 5.21966134e-01 8.24998941e-02 -7.66338173e-04 ... -8.27678238e-03 1.19138181e-01 9.06582221e-01] [ 4.81391614e-02 -1.26266901e-01 -2.49640955e-01 ... 1.33921125e+00 8.25710489e-01 8.65966313e-01]]lr_l1_coef_: [[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 -1.37423471e-02] [ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 4.38176896e-02] [ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 -5.13700279e-02] [ 0.00000000e+00 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 -1.77831740e-03] [ 7.03980012e-01 0.00000000e+00 0.00000000e+00 ... 0.00000000e+00 0.00000000e+00 2.01422949e-04] [-2.02008109e+00 -8.34909177e+00 -3.29578262e+00 ... 4.02040351e+00 3.20405969e+00 1.82634113e-02]]lr_l2_coef_: [[-1.03725936e-01 5.50632453e-03 6.33482873e-02 ... -3.88543365e-01 -1.92209170e-01 -5.84902049e-02] [ 1.05758725e-01 -1.17717948e-01 -3.03955359e-01 ... -2.31378407e+00 -2.32401778e-01 3.43900793e-02] [ 8.61767183e-03 2.40843471e-01 1.25792887e-01 ... 2.54368464e+00 3.31422840e-01 -4.26759836e-02] [-3.09551146e-01 -1.46430474e-01 2.88589498e-01 ... -4.62980616e-01 1.34359794e-01 1.33067417e-03] [ 6.71720746e-01 1.43032935e-01 2.24426200e-01 ... -4.58979021e-01 -1.02600733e-01 8.06089631e-03] [-4.68800629e-01 -7.34170993e-01 -8.65869923e-01 ... 1.86878293e+00 7.99875615e-01 1.58405200e-02]]# 请在此处填写你的代码(绘制6张图)import matplotlib.pyplot as pltplt.figure(1, figsize = (30, 10))plt.subplot(231)plt.scatter(feature_cols, lr.coef_[0])plt.scatter(feature_cols, lr_l1.coef_[0])plt.scatter(feature_cols, lr_l2.coef_[0])plt.subplot(232)plt.scatter(feature_cols, lr.coef_[1])plt.scatter(feature_cols, lr_l1.coef_[1])plt.scatter(feature_cols, lr_l2.coef_[1])plt.subplot(233)plt.scatter(feature_cols, lr.coef_[2])plt.scatter(feature_cols, lr_l1.coef_[2])plt.scatter(feature_cols, lr_l2.coef_[2])plt.subplot(234)plt.scatter(feature_cols, lr.coef_[3])plt.scatter(feature_cols, lr_l1.coef_[3])plt.scatter(feature_cols, lr_l2.coef_[3])plt.subplot(235)plt.scatter(feature_cols, lr.coef_[4])plt.scatter(feature_cols, lr_l1.coef_[4])plt.scatter(feature_cols, lr_l2.coef_[4])plt.subplot(236)plt.scatter(feature_cols, lr.coef_[5])plt.scatter(feature_cols, lr_l1.coef_[5])plt.scatter(feature_cols, lr_l2.coef_[5])<matplotlib.collections.PathCollection at 0x226adc34af0>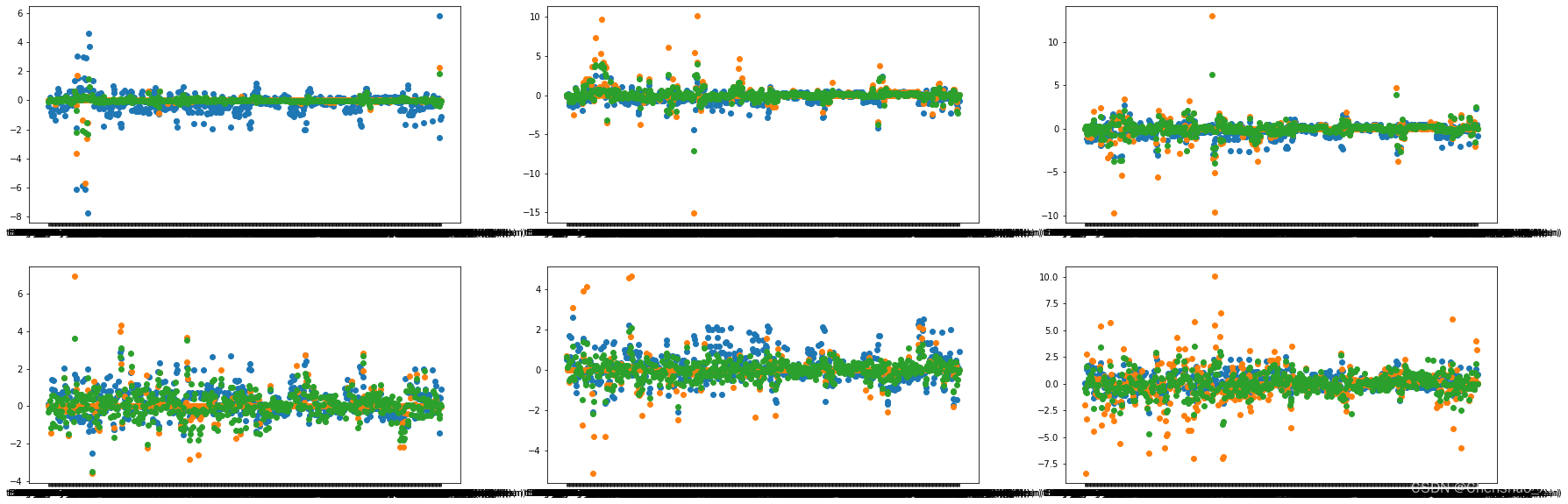
第五步:预测数据
将每个模型预测的类别和概率值都保存下来。# 请在此处填写你的代码lr_pred_prob = lr.predict_proba(X_test)lr_l1_pred_prob = lr_l1.predict_proba(X_test)lr_l2_pred_prob = lr_l2.predict_proba(X_test)array([[9.99999993e-001, 7.42909015e-009, 4.11242095e-022, 1.72199687e-110, 7.92318349e-117, 1.25352049e-118], [2.28654820e-039, 1.12754892e-032, 1.49849650e-030, 3.04091495e-009, 7.21093140e-006, 9.99992786e-001], [1.01631928e-023, 9.99517697e-001, 4.82303397e-004, 1.14668778e-090, 5.97293981e-097, 7.29740533e-101], ..., [5.82445006e-025, 1.57488491e-004, 9.99842512e-001, 2.47445986e-094, 1.43492169e-100, 5.22894472e-103], [5.07457042e-028, 9.99375236e-001, 6.24763971e-004, 9.56127218e-090, 4.24679878e-094, 1.04128353e-097], [1.07819125e-062, 3.31123144e-052, 1.86904909e-049, 9.99999819e-001, 1.81046086e-007, 1.23086753e-011]])第六步:评价模型
对每个模型,分别计算下面的各评测指标值:
accuracyprecisionrecallfscoreconfusion matrix# 请在此处填写你的代码from sklearn import metrics#基本的使用缺省参数的逻辑回归模型print("confusion matrix:", metrics.confusion_matrix(y_test, y1_pred_class))print("accruacy:", metrics.accuracy_score(y_test, y1_pred_class))print("precision:", metrics.precision_score(y_test, y1_pred_class, average = "micro"))print("recall:", metrics.recall_score(y_test, y1_pred_class, average = "micro"))print("fscore:", metrics.f1_score(y_test, y1_pred_class, average = "micro"))confusion matrix: [[422 0 0 0 0 0] [ 0 366 20 0 0 0] [ 0 15 397 0 0 0] [ 0 0 0 368 0 0] [ 0 0 0 0 295 1] [ 0 0 0 2 0 320]]accruacy: 0.9827742520398912precision: 0.9827742520398912recall: 0.9827742520398912fscore: 0.9827742520398912# 使用L1 正则化的逻辑回归模型y2_pred_class = lr_l1.predict(X_test)print("confusion matrix:", metrics.confusion_matrix(y_test, y2_pred_class))print("accruacy:", metrics.accuracy_score(y_test, y2_pred_class))print("precision:", metrics.precision_score(y_test, y2_pred_class, average = "micro"))print("recall:", metrics.recall_score(y_test, y2_pred_class, average = "micro"))print("fscore:", metrics.f1_score(y_test, y2_pred_class, average = "micro"))confusion matrix: [[422 0 0 0 0 0] [ 0 370 16 0 0 0] [ 0 15 397 0 0 0] [ 0 0 0 368 0 0] [ 0 0 0 0 296 0] [ 0 0 0 0 1 321]]accruacy: 0.985494106980961precision: 0.985494106980961recall: 0.985494106980961fscore: 0.985494106980961# 使用L2 正则化的逻辑回归模型y3_pred_class = lr_l2.predict(X_test)print("confusion matrix:", metrics.confusion_matrix(y_test, y3_pred_class))print("accruacy:", metrics.accuracy_score(y_test, y3_pred_class))print("precision:", metrics.precision_score(y_test, y3_pred_class, average = "micro"))print("recall:", metrics.recall_score(y_test, y3_pred_class, average = "micro"))print("fscore:", metrics.f1_score(y_test, y3_pred_class, average = "micro"))confusion matrix: [[422 0 0 0 0 0] [ 0 368 18 0 0 0] [ 0 13 399 0 0 0] [ 0 0 0 368 0 0] [ 0 0 0 0 296 0] [ 0 0 0 1 0 321]]accruacy: 0.985494106980961precision: 0.985494106980961recall: 0.985494106980961fscore: 0.985494106980961