文章目录
前言登录Amazon BedrockMeta Liama2 模型快速体验效果演示名词解释项目工程介绍效果演示 Meta Llama 2 API的调用打开 Amazon Cloud9 实验环境 创建环境设置环境详细信息熟悉 Amazon Cloud9 实验环境查看对应的文件目录 编写调用 Meta Llama 2 API 应用请求参数返回参数参数说明说明 操作流程讲解完整代码 总结
前言
随着生成式人工智能(AIGC)技术的蓬勃发展,技术创作者们再次涌入一个充满挑战与机遇的新领域。Amazon Bedrock 是一个专为创新者设计的平台,它提供了构建生成式人工智能应用程序所需的一切工具和资源。无论您的技术背景如何,Amazon Bedrock 都能让您快速上手并体验到最新的生成式人工智能技术。对于AI新手和希望提升技能的专家来说,Amazon Bedrock 都是一个强大的助力。
今天我们就来一场酣畅淋漓的手把手教程, 让我们快速轻松的感受生成式人工智能的构建
登录Amazon Bedrock
点击链接 如下图所示点击开始实验
进入操作页面开启生成式ai 之旅吧!!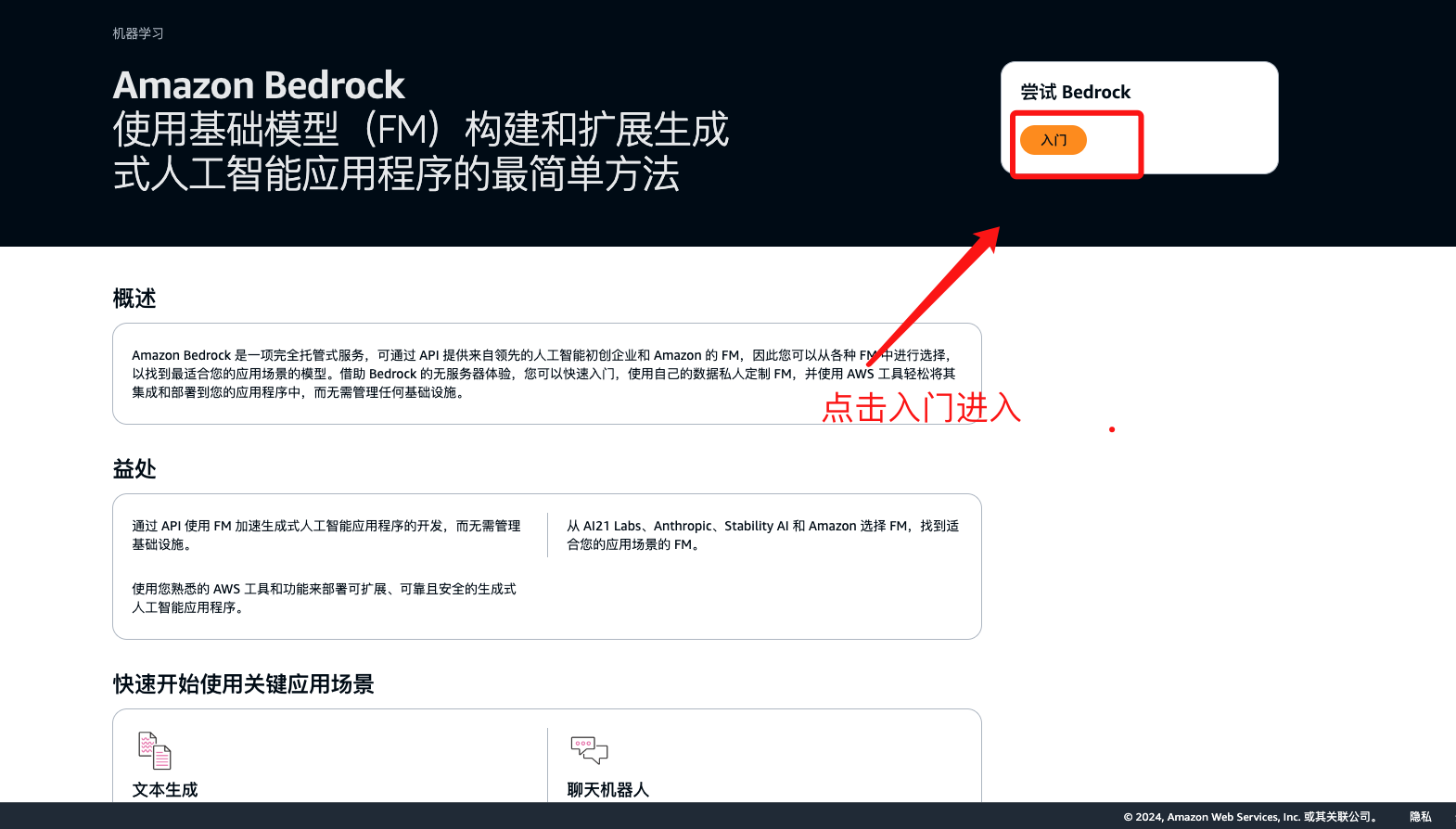
Meta Liama2 模型快速体验
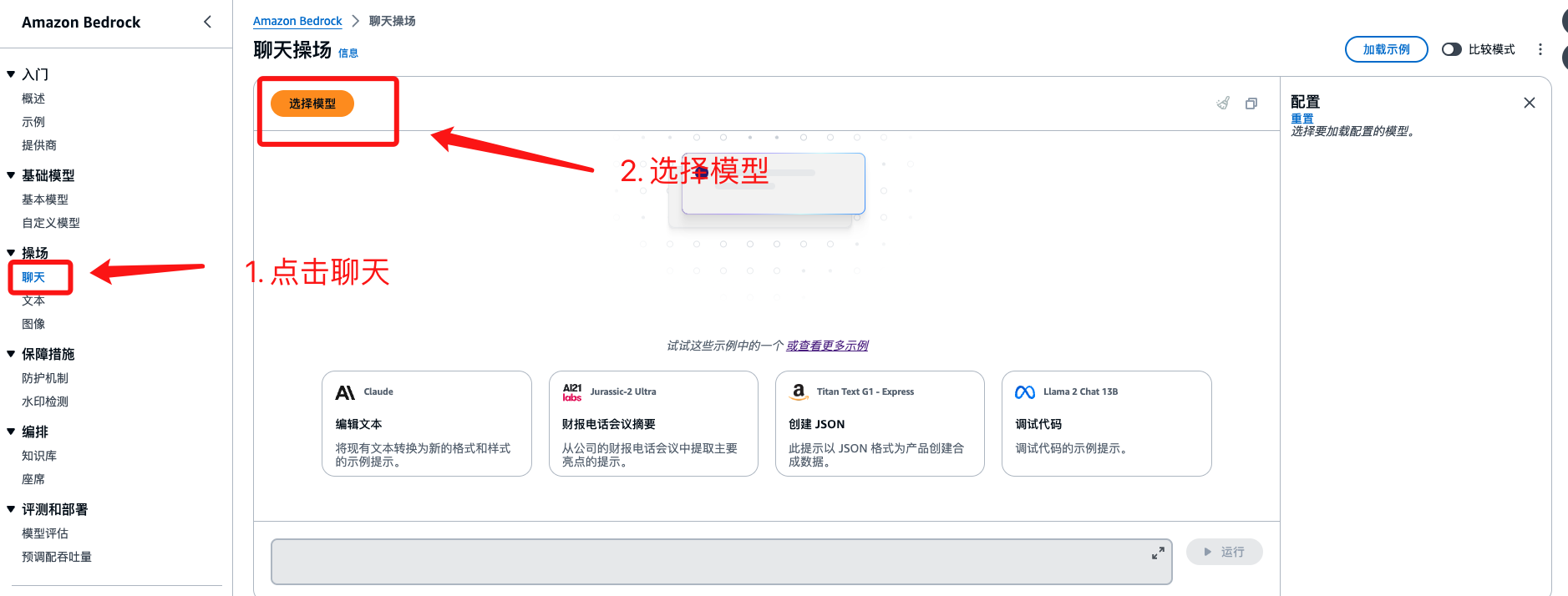
模型这里我们选择 Meta => LIama2 Chat 70B 吞吐量 按需即可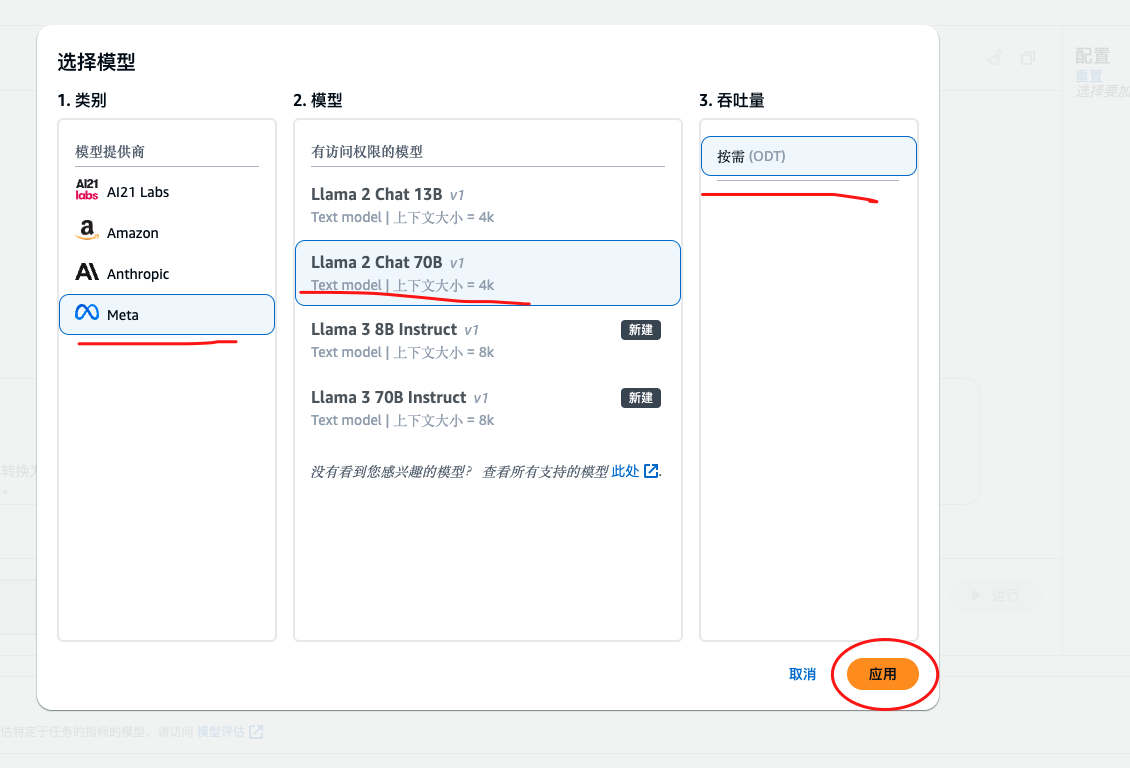
选择完成之后 点击应用
效果演示
当我们点击应用之后 效果如下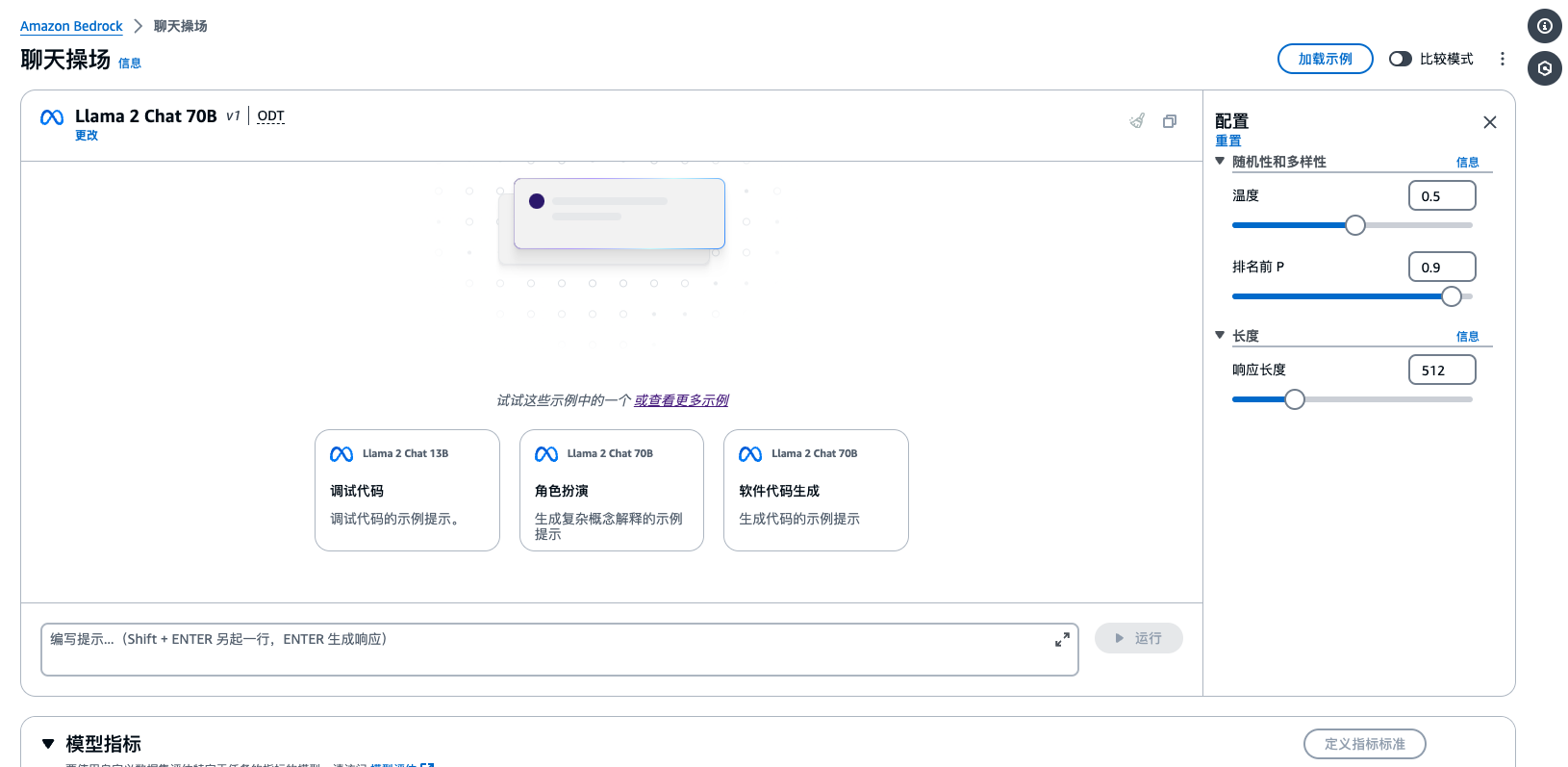
名词解释
| 名称 | 解释 |
|---|---|
| 随机性和多样性 | 通过将输出限制为更可能的结果或改变输出概率分布的形状来影响生成的响应的变化。 |
| 长度 | 通过指定结束响应生成的最大长度或字符序列来限制响应。 |
项目工程介绍
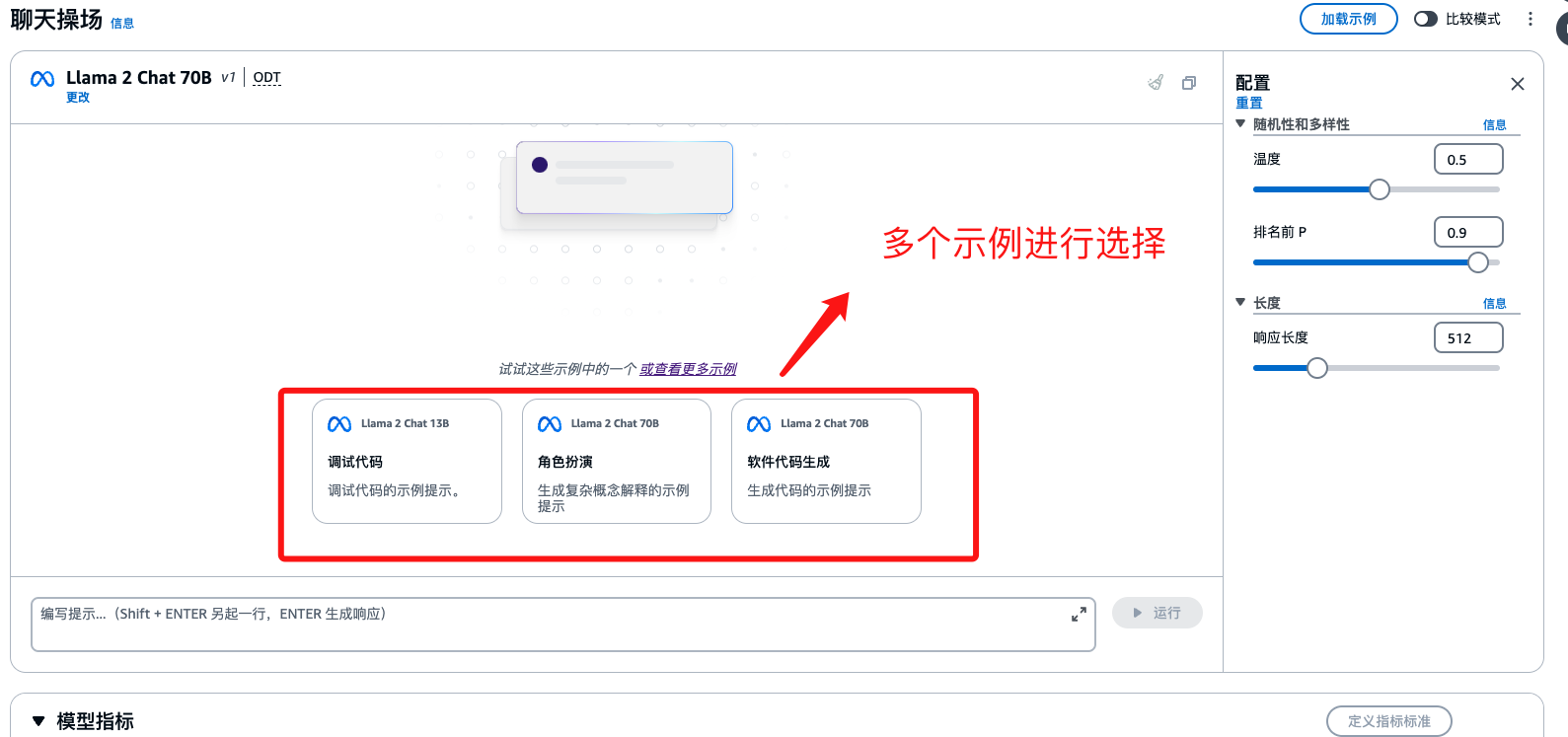
效果演示
我提出的问题是 : JavaScript 中如和理解闭包
回复如下: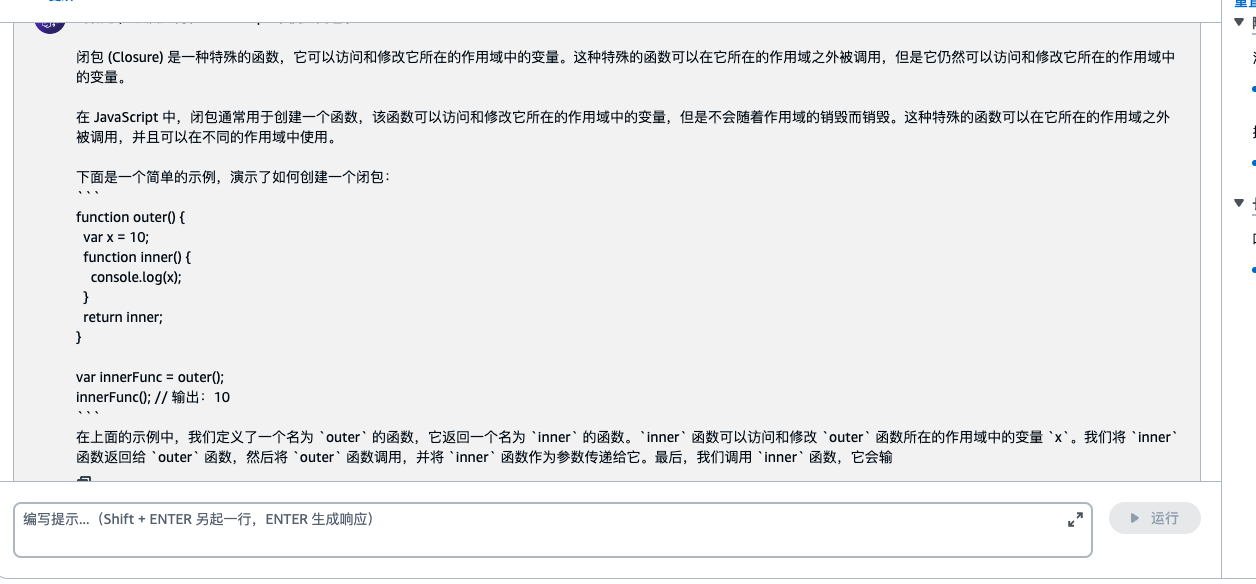
对于代码解释看起来还是有点东西的哦!!
Meta Llama 2 API的调用
打开 Amazon Cloud9 实验环境
打开控制台,搜索Cloud9, 点击进入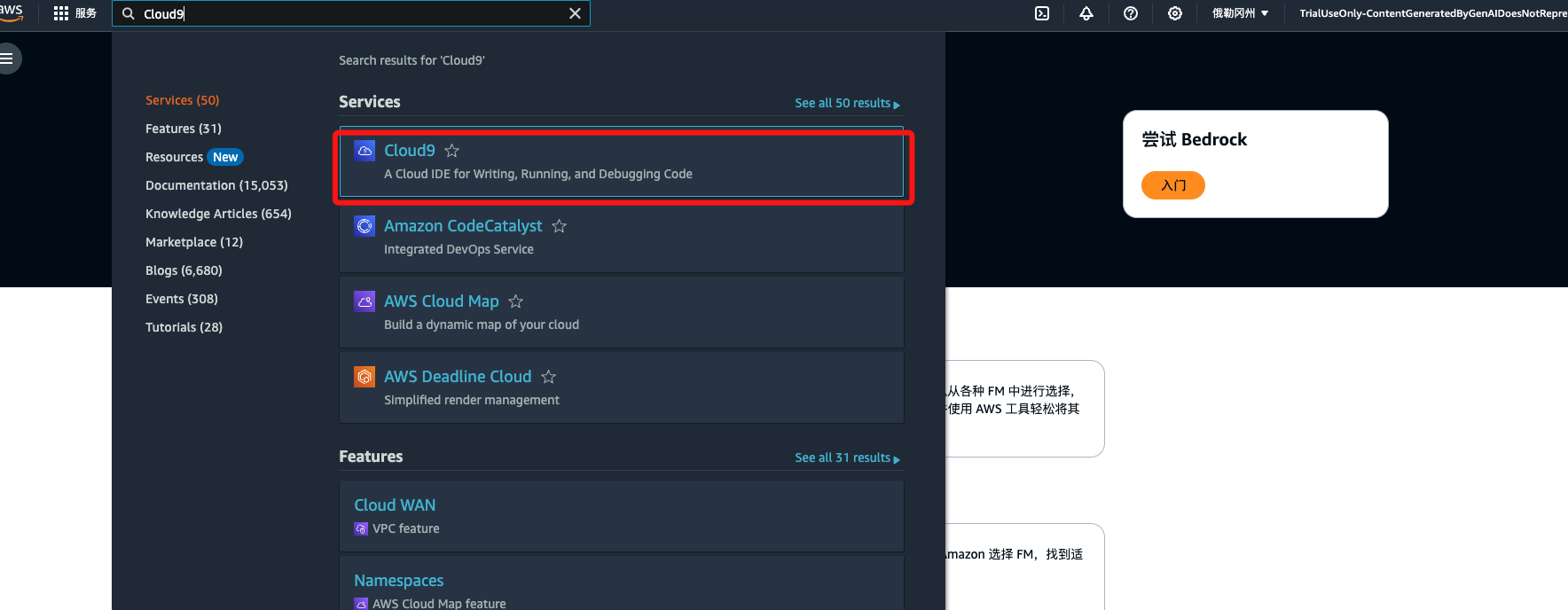
创建环境
设置环境详细信息
设置名称为 bedrock设置实例类型 t3.small平台 Ubuntu Server 22.04 LTS超时 30 分钟温馨提示:
实验环境中仅限选择Cloud9 EC2实例为 t3.small (2 GiB RAM + 2 vCPU)基于不浪费的原则,创建Cloud9的时候,超时时间只能选择默认的30分钟的选项,且Cloud9实例数量也将自动审核,如果发现异常会关闭Cloud9实例,甚至封禁账号,务必注意文明实验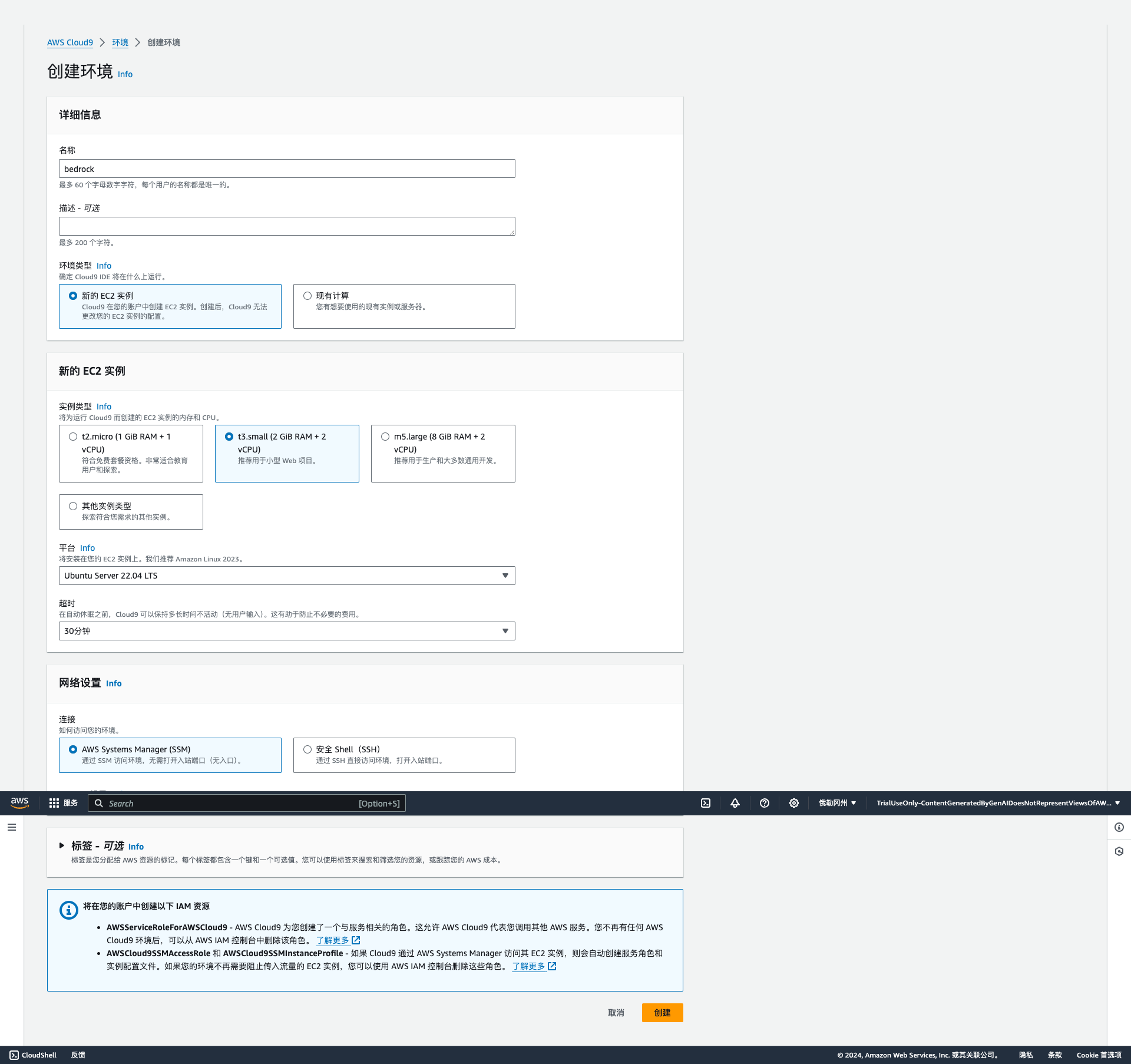
熟悉 Amazon Cloud9 实验环境
首次进入 Cloud9 实验环境中需要等待加载
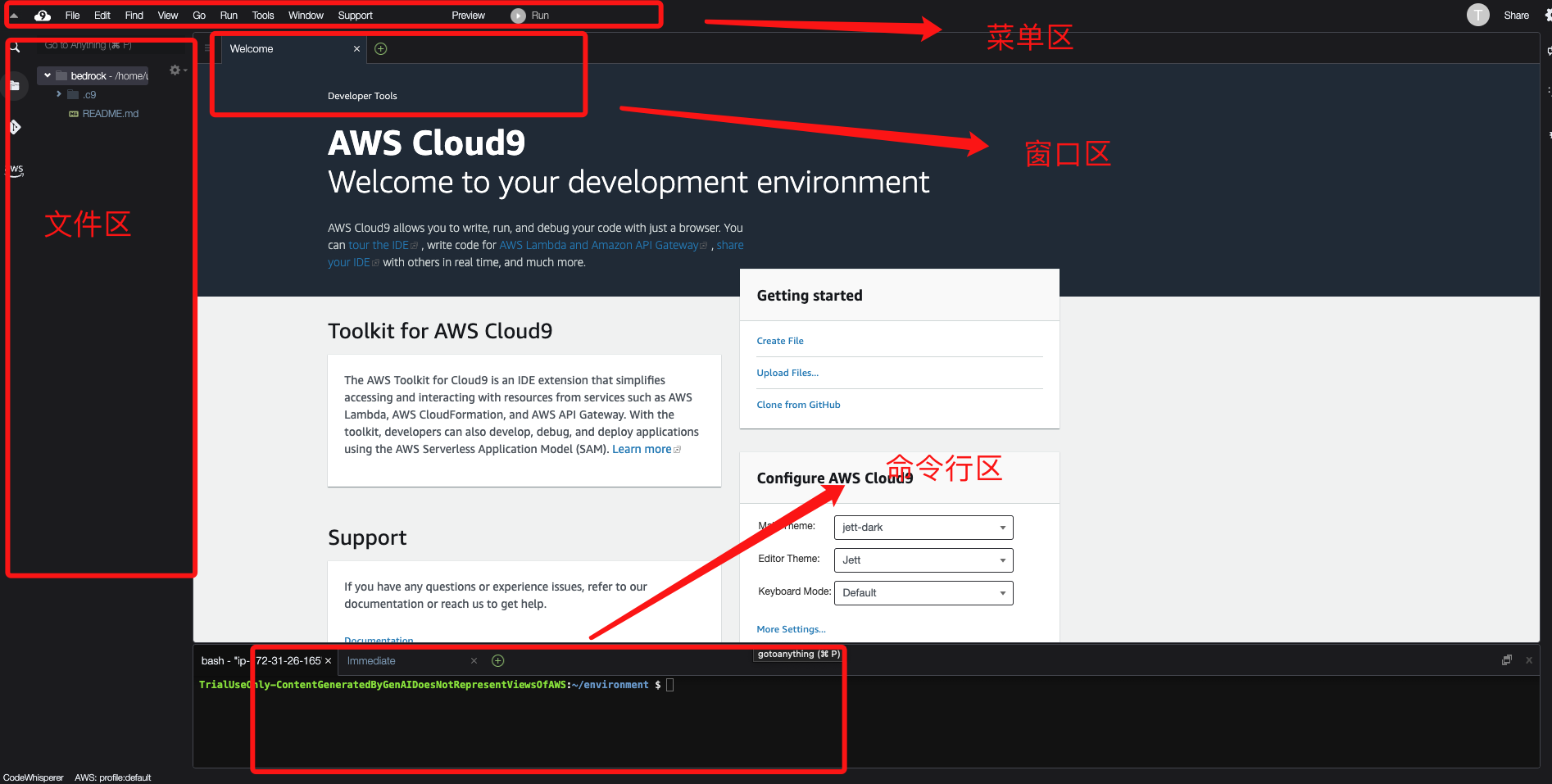
在Amazon Cloud9 IDE中,选择 终端
在终端中输入如下命令
cd ~/environment/curl 'https://dev-media.amazoncloud.cn/doc/workshop.zip' --output workshop.zipunzip workshop.zip等待解压完成
查看对应的文件目录
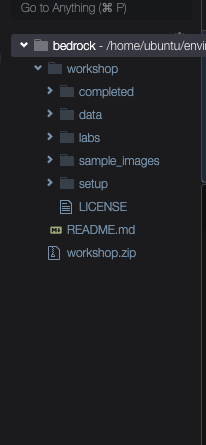
继续使用 终端,安装实验所需的环境依赖项
pip3 install -r ~/environment/workshop/setup/requirements.txt -U
编写调用 Meta Llama 2 API 应用
请求参数
| 参数 | 说明 |
|---|---|
| prompt复制 | 要传递给模型的提示,这是必填项。 |
| temperature复制 | 降低响应的随机性,默认值为0.5,取值范围是0到1。 |
| top_p复制 | 忽略可能性较小的选项,默认值为0.9,取值范围是0到1。 |
| max_gen_len复制 | 生成响应的最大令牌数,默认值为512,取值范围是1到2048。 |
返回参数
{ "generation": "\n\n<response>", "prompt_token_count": int, "generation_token_count": int, "stop_reason" : string}参数说明说明
| 参数 | 解释意思 |
|---|---|
| 生成 | 指生成的文本。 |
| prompt_token_count复制 | 表示提示中的代币数量。 |
| generation_token_count复制 | 代表生成的文本中的标记数量。 |
| stop_reason复制 | 用于说明响应停止生成文本的原因。其可能的值为:1、stop 意味着模型已结束为输入提示生成文本。2、length表示生成的文本的词元长度超过了对 InvokeModel(如果需要对输出进行流式传输,则为 InvokeModelWithResponseStream)的调用中的 max_gen_len 值。此时响应会被截断为 max_gen_len 个词元。可考虑增大 max_gen_len 的值并重试。 |
操作流程讲解
打开workshop/labs/api文件夹,打开文件bedrock_api.py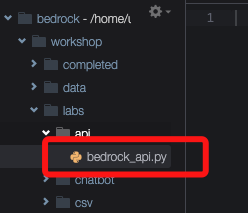
import jsonimport boto3session = boto3.Session()bedrock = session.client(service_name='bedrock-runtime') #初始化Bedrock客户端库我们将确定要使用的模型、提示和指定模型的推理参数。
bedrock_model_id = "meta.llama2-70b-chat-v1" #设置模型 prompt = "说一下冒泡排序的原理?" #提示词body = json.dumps({ "prompt": prompt, "max_gen_len": 2048, "temperature":0.5, "top_p":0.9}) response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求response_body = json.loads(response.get('body').read()) response_text=response_body['generation'] #从 JSON 中返回相应数据print(response_text)cd ~/environment/workshop/labs/apipython bedrock_api.py8 运行结果如下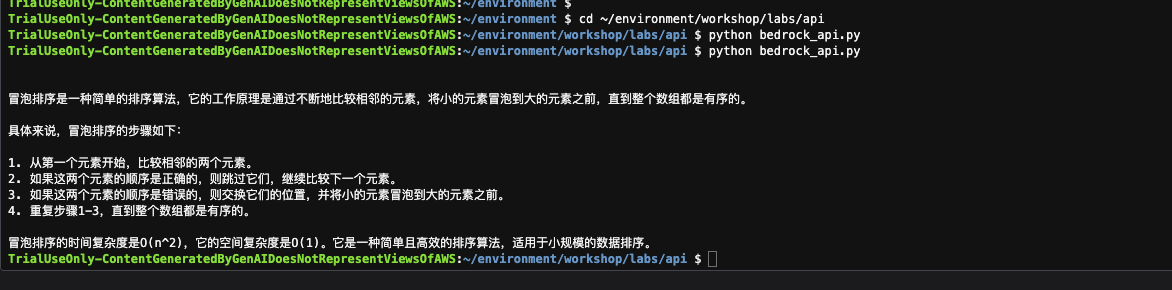
完整代码
import jsonimport boto3session = boto3.Session()bedrock = session.client(service_name='bedrock-runtime') #初始化Bedrock客户端库bedrock_model_id = "meta.llama2-70b-chat-v1" #设置模型 prompt = "说一下冒泡排序的原理?" #提示词body = json.dumps({ "prompt": prompt, "max_gen_len": 2048, "temperature":0.5, "top_p":0.9}) response = bedrock.invoke_model(body=body, modelId=bedrock_model_id, accept='application/json', contentType='application/json') #发送调用请求response_body = json.loads(response.get('body').read()) response_text=response_body['generation'] #从 JSON 中返回相应数据print(response_text)是不是很简单呢
总结
随着生成式人工智能的逐渐火爆, 期待小伙伴们也快快的加入进来体验一番吧!!