一、为什么要学会应用 IP 代理技术二、采集海外电影信息爬虫实战2.1 选择目标网站并生成代理2.2 编写爬虫并设置代理2.3 运行爬虫2.4 处理数据2.5 完整代码 三、Roxlabs 代理及优势分析四、快速应用Roxlabs代理功能4.1 领免费流量4.2 代理类型4.3 获取代理4.4 配置代理设置4.5 开始数据采集 五、总结
一、为什么要学会应用 IP 代理技术
在数字化飞速发展的今天,网络已成为人们获取信息、交流数据的重要平台,数据成为了最宝贵的资源之一。然而许多网站和服务出于各种原因,使得有价值的数据变得难以获取;此外在互联网时代,个人隐私几乎成为了奢侈品。我们每一次浏览网站、搜索内容都可能被第三方追踪和记录,这不仅侵犯了我们的隐私权,还可能带来安全风险。

IP 代理技术的出现为以上难题提供了解决方案。简单来说,IP 代理就是将客户端的请求集中到代理服务器上,然后由代理服务器来处理这些请求并返回结果。由代理服务器代替用户与目标服务器进行通信,使得我们的网络行为更加私密,从而保护个人信息不被滥用。不仅如此,通过 IP 代理还可以轻松获取到更多的全球公开数据资源。
二、采集海外电影信息爬虫实战
在本实战案例中,我们将基于 Python 使用 Roxlabs IP 代理获取海外的 100 部电影信息。

2.1 选择目标网站并生成代理
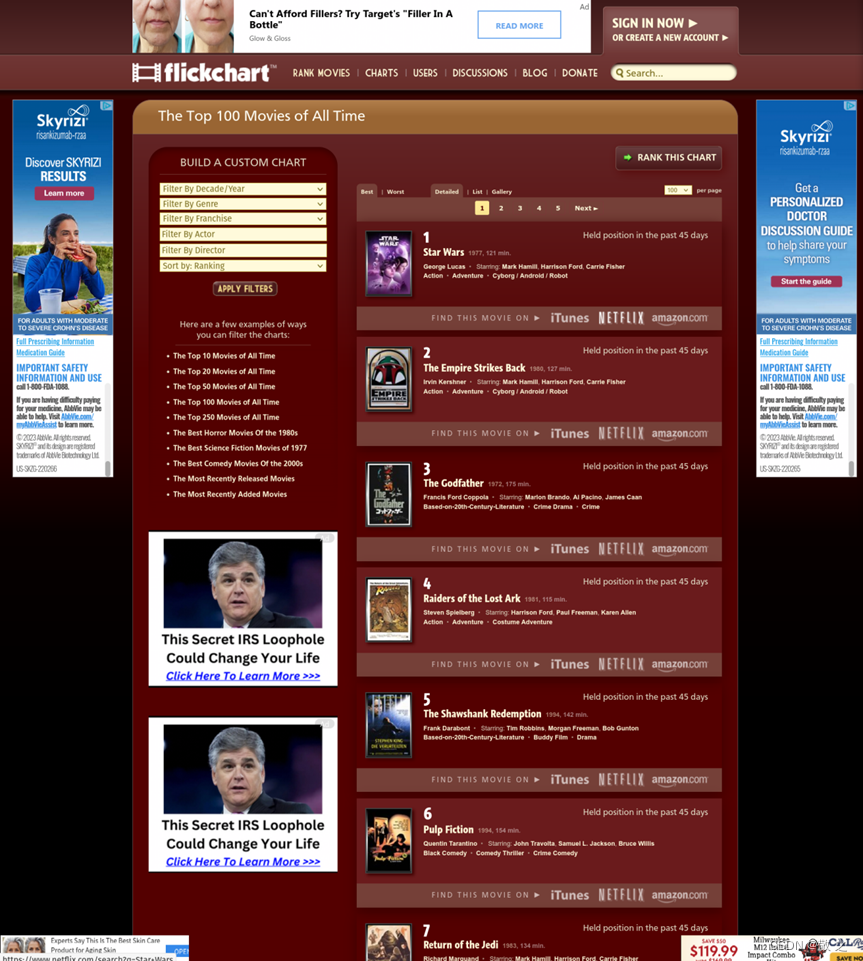
我们爬取的目标网址是 flickchart。这是一个结合了电影评价、排行与社交功能的综合性电影类网站。
进入 Roxlabs 后台设置白名单。这一步是必要的,设置白名单是为了保证本机 IP 可以对目标网站进行正常的操作。
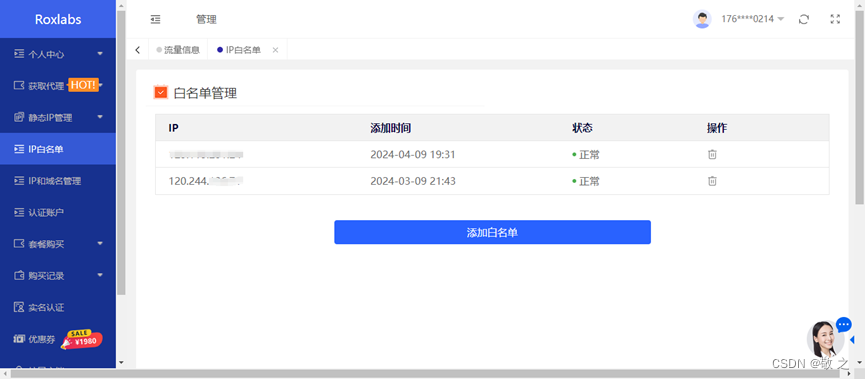
进入 Roxlabs 后台,选择“IP白名单”模块,将本机 IP 填入;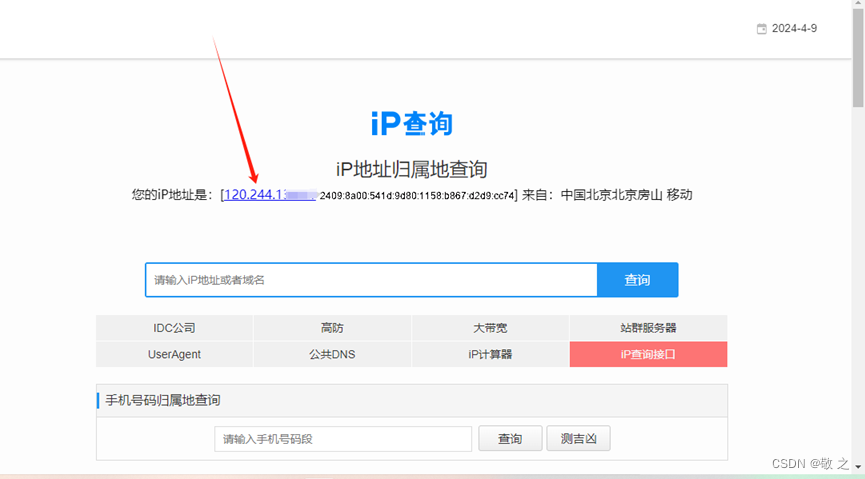
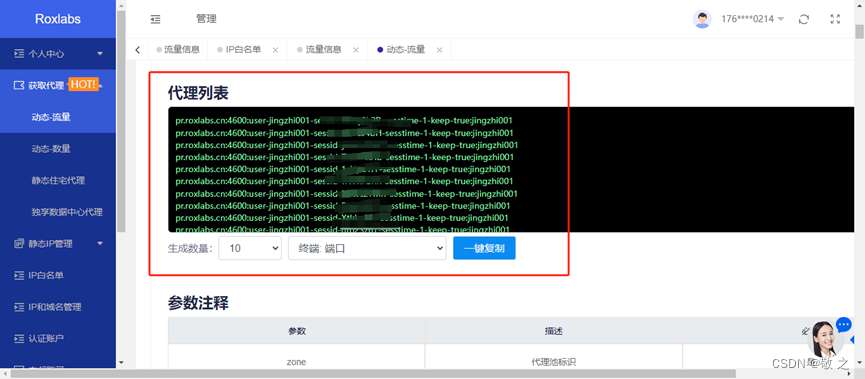
随后生成代理,相关信息会在 Roxlabs 的“获取代理”模块自动展现;
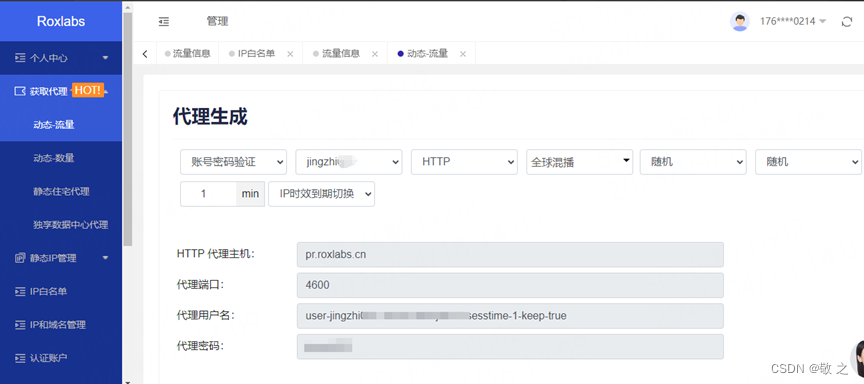
此时前期准备工作就完成了。
2.2 编写爬虫并设置代理
先写一个简单的爬虫框架;
# 使用requests库获取网页原始内容import requests# 首先定义爬取的网址target_url = "https://www.flickchart.com/charts.aspx?perpage=100"# 设置请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"}response = requests.get(target_url, headers=headers)if response.status_code == 200: print(response.text)随后添加和设置代理,这里需要用到 Roxlabs 生成的代理列表;
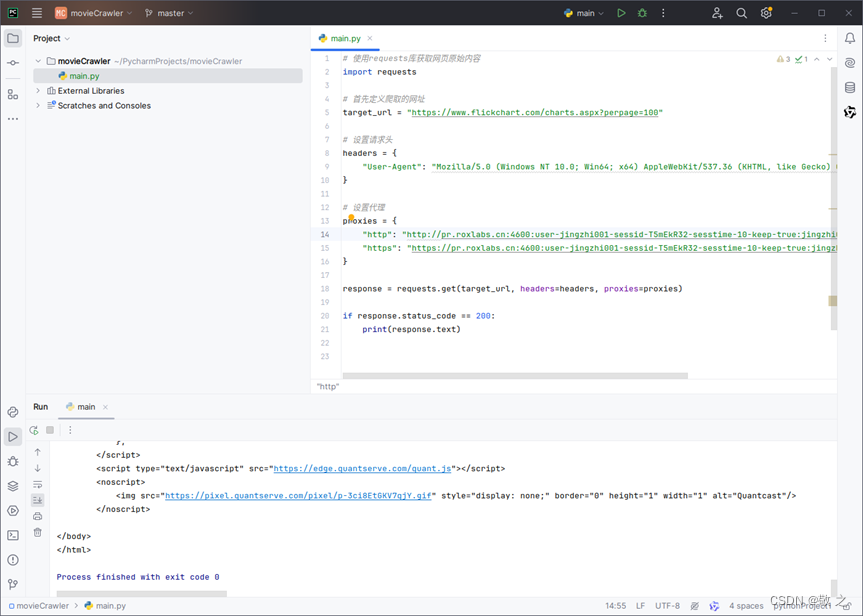
# 使用requests库获取网页原始内容import requests# 首先定义爬取的网址target_url = "https://www.flickchart.com/charts.aspx?perpage=100"# 设置请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"}# 设置代理proxies = { "http": "http://pr.roxlabs.cn:4600:user-jingzhi001-sessid-T5mEkR32-sesstime-10-keep-true:jingzhi001", "https": "https://pr.roxlabs.cn:4600:user-jingzhi001-sessid-T5mEkR32-sesstime-10-keep-true:jingzhi001"}response = requests.get(target_url, headers=headers, proxies=proxies)if response.status_code == 200: print(response.text)2.3 运行爬虫
运行代码,可以看到结果正常输出;
最后试着查找一部电影名字看看是否获取到了所需要的数据,比如搜《The Empire Strikes Back》;
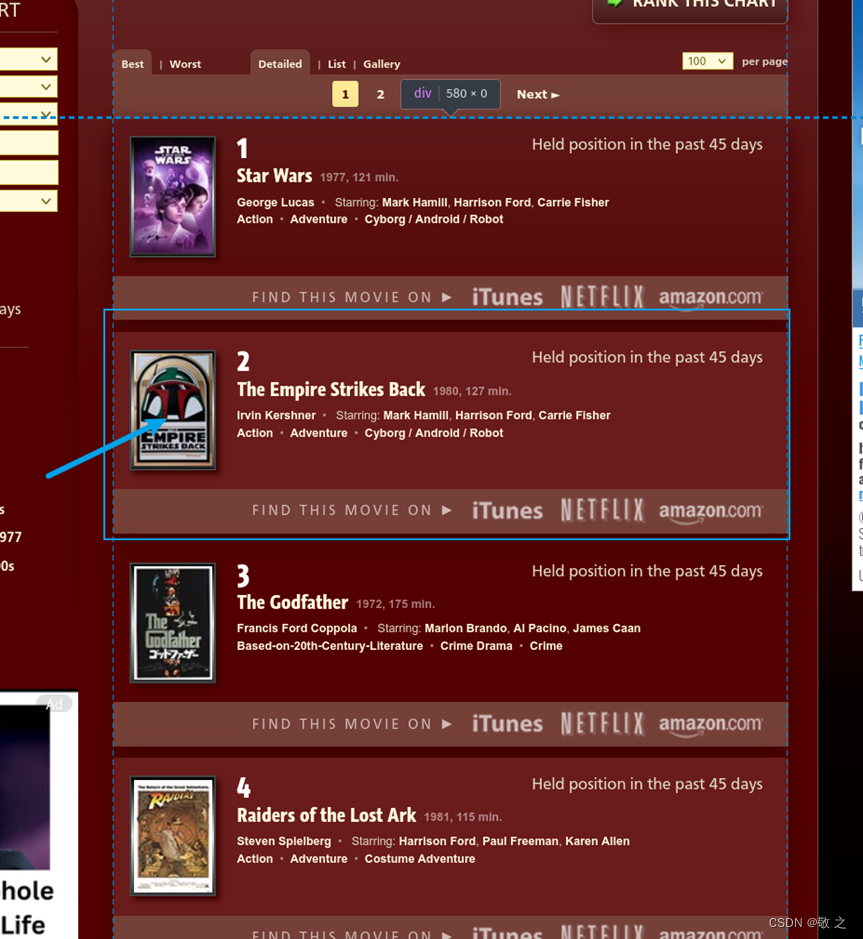
搜索发现结果无误;
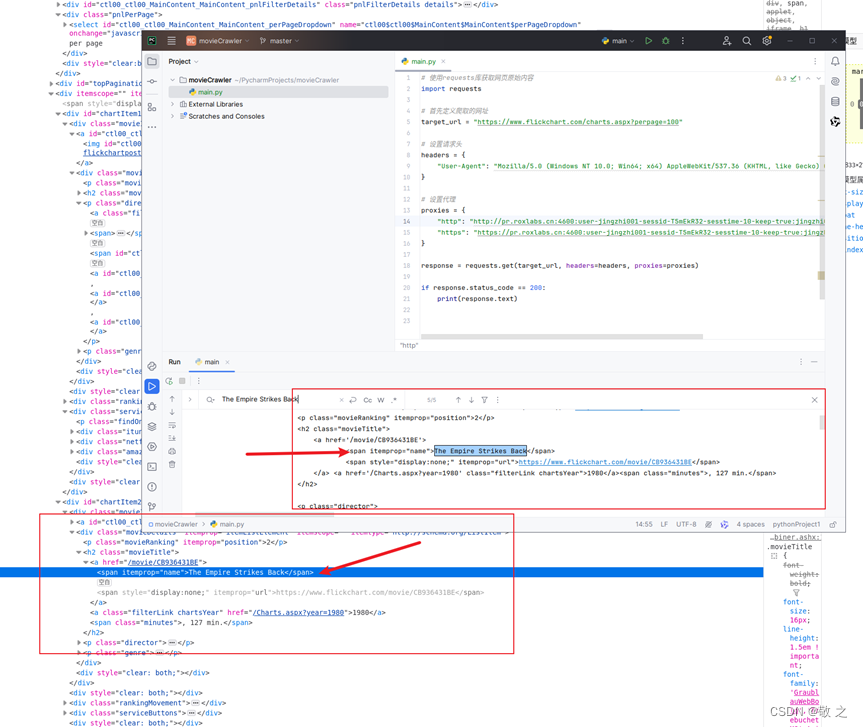
可以查出结果说明爬虫没有问题,已经获得需要的数据,接下来就应该处理数据了。
2.4 处理数据
处理网页数据这里使用的工具是 BeautifulSoup。步骤如下:
导入包;
# 使用BeautifulSoup库解析网页内容from bs4 import BeautifulSoup解析网页;
if response.status_code == 200: soup = BeautifulSoup(response.text, "html.parser")确定网页结构;
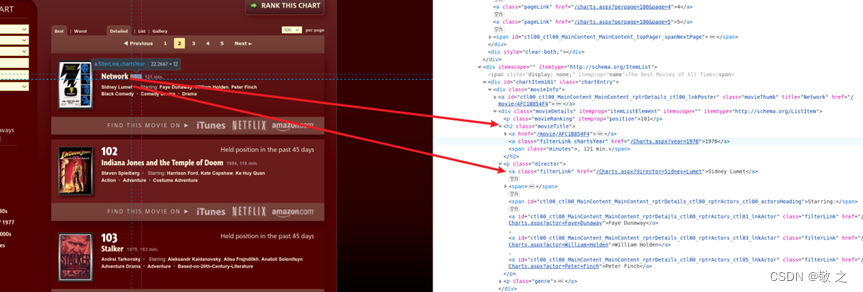
开始解析,首先定义一个电影列表;
movie_list = []然后解析数据;
# 寻找元素div,类名为chartEntry,下面的movieInfofor movie in soup.find_all("div", class_="chartEntry"): # 将类名movieTitle的文本内容获取到 movie_title = movie.find("h2", class_="movieTitle") # 电影名是movie_title下第一个a标签的文本内容 movie_name = movie_title.find("a").text # movie_name有两行,第一行是电影名,第二行是链接,拆分 _, movie_name, movie_url, _ = movie_name.split("\n") # 电影上映年份是在movie_title的第二个a标签的文本内容 movie_year = movie_title.find_all("a")[1].text # p标签类名为director,下的第一个a标签文本内容是导演名 movie_director = movie.find("p", class_="director").find("a").text接下来再加入电影列表;
movie_list.append({ "name": movie_name, "year": movie_year, "director": movie_director, "url": movie_url,})由于这个网站一共有 5 页,所以这里将 target_url 修改了一下;
# 首先定义爬取的网址page_index = 1target_url = f"https://www.flickchart.com/charts.aspx?perpage=100&page=${page_index}"然后将爬取的这里定义成了一个函数;
def get_movie_list(): global page_index, target_url response = requests.get(target_url, headers=headers) if response.status_code == 200: # ... 后面的代码输出电影;
for page_index in range(1, 5): get_movie_list()为了方便,最后将爬取到的电影写入 CSV 文件;
# 写出到csv文件import csvwith open("movie_list.csv", "w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=["name", "year", "director", "url"]) writer.writeheader() writer.writerows(movie_list)print("写入完成")最后运行代码,结果如下,电影列表已经列了出来;
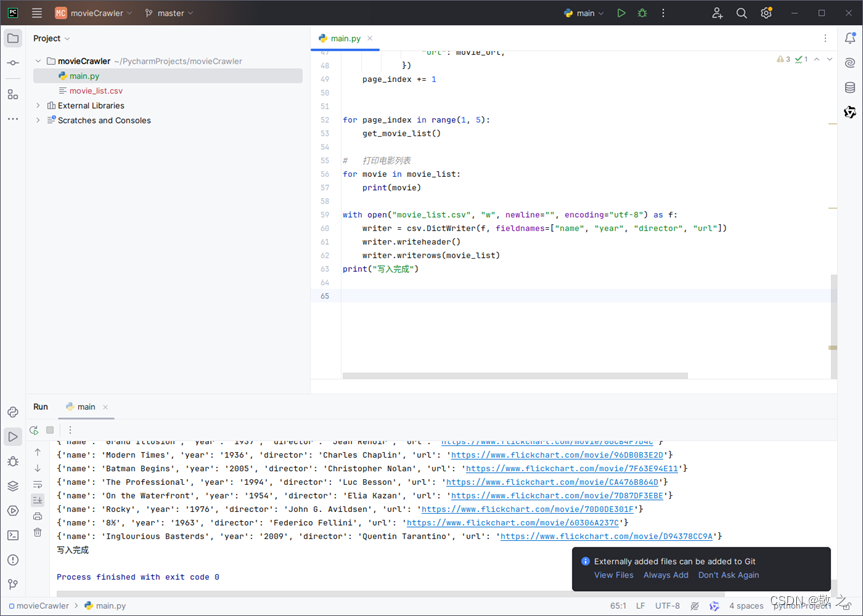
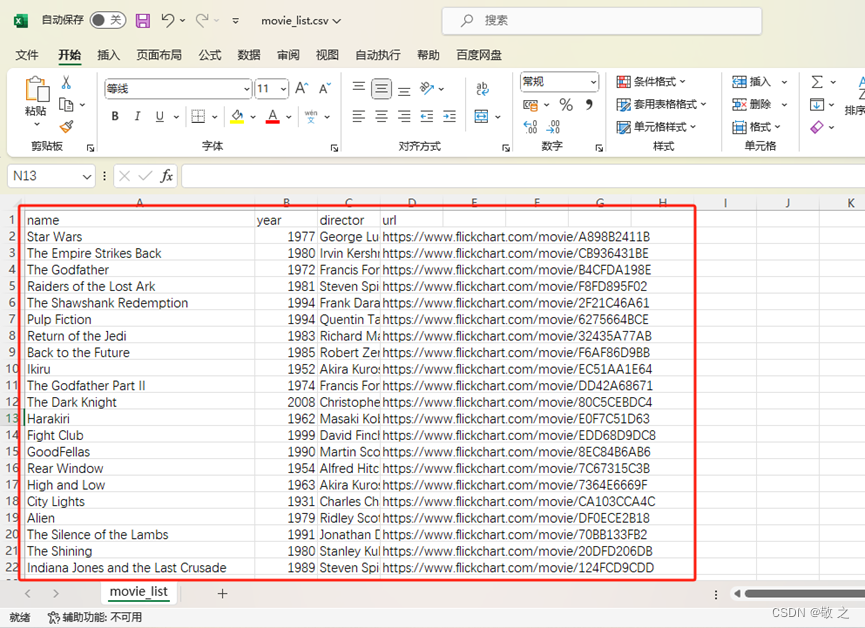
打开 CSV 文件看看,效果不错。至此整个海外电影爬虫实战结束。
2.5 完整代码
# 使用requests库获取网页原始内容import requests# 使用BeautifulSoup库解析网页内容from bs4 import BeautifulSoup# 写出到csv文件import csv# 首先定义爬取的网址page_index = 1target_url = f"https://www.flickchart.com/charts.aspx?perpage=100&page=${page_index}"# 设置请求头headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36"}# 设置代理# proxies = {# "http": "http://pr.roxlabs.cn:4600:user-jingzhi001-sessid-T5mEkR32-sesstime-10-keep-true:jingzhi001",# "https": "https://pr.roxlabs.cn:4600:user-jingzhi001-sessid-T5mEkR32-sesstime-10-keep-true:jingzhi001"# }movie_list = []def get_movie_list(): global page_index, target_url response = requests.get(target_url, headers=headers) if response.status_code == 200: soup = BeautifulSoup(response.text, "html.parser") # 寻找元素div,类名为chartEntry,下面的movieInfo for movie in soup.find_all("div", class_="chartEntry"): # 将类名movieTitle的文本内容获取到 movie_title = movie.find("h2", class_="movieTitle") # 电影名是movie_title下第一个a标签的文本内容 movie_name = movie_title.find("a").text # movie_name有两行,第一行是电影名,第二行是链接,拆分 _, movie_name, movie_url, _ = movie_name.split("\n") # 电影上映年份是在movie_title的第二个a标签的文本内容 movie_year = movie_title.find_all("a")[1].text # p标签类名为director,下的第一个a标签文本内容是导演名 movie_director = movie.find("p", class_="director").find("a").text movie_list.append({ "name": movie_name, "year": movie_year, "director": movie_director, "url": movie_url, }) page_index += 1for page_index in range(1, 5): get_movie_list()# 打印电影列表for movie in movie_list: print(movie)with open("movie_list.csv", "w", newline="", encoding="utf-8") as f: writer = csv.DictWriter(f, fieldnames=["name", "year", "director", "url"]) writer.writeheader() writer.writerows(movie_list)print("写入完成")三、Roxlabs 代理及优势分析
在以上的案例当中,我们的整个过程是基于 Roxlabs 代理实现的,用到了 Roxlabs 的 IP 白名单功能和动态住宅 IP 资源。
作为一个专注于为用户提供高质量数据采集代理资源的服务平台,我经过实际上手使用和综合多家 IP 代理商进行对比,发现 Roxlabs 具有多重优势:
全球覆盖和超大资源量。Roxlabs 的代理网络遍布全球 200 多个国家和地区,拥有超过 1000 万的真实住宅 IP 资源。这种广泛的覆盖和庞大的IP资源池使得 Roxlabs 能够满足多种业务需求。
不限并发会话。Roxlabs 支持无限并发会话,高带宽,无需额外费用,满足您的业务拓展需求。
城市级定位。Roxlabs 提供国家、城市和州级精准定位 IP,支持 HTTP(S)/Socks5 代理协议。
自定义 IP 时效。Roxlabs 动态住宅支持 1-1440 分钟自定义 IP 时效,可以根据业务需求自主设定会话时长,自由设置 API 提取导出格式。
数据统计功能。Roxlabs 个人中心实时统计代理使用数据,我们可以随时查看账户余额信息和流量使用情况,支持添加多个 IP 白名单和认证账户,更有 IP 管理、认证账户管理等功能。
高性价比。动态住宅流量套餐支持 免费试用 ,流量不过期,低至¥5/G。可以根据自己的需求选择不同的代理类型和套餐,Roxlabs 还提供定制化服务,满足特定业务场景的个性化需求。
基于以上优势,Roxlabs 在爬虫采集、跨境电商、市场调研、网络安全等方面都有着相当成熟的解决方案。
四、快速应用Roxlabs代理功能
为了让大家更深入的了解 Roxlabs,在这里快速演示一下它的使用功能。
4.1 领免费流量
访问 Roxlabs 的官方网站 roxlabs.cn 进行注册并登录账号;
注册成功后进行实名认证,认证完成流量直接到账,个人认证赠送 500MB 流量,企业认证赠送 1G 流量;
4.2 代理类型
根据业务需求选择适合自己的代理套餐,Roxlabs 为用户提供动态住宅 IP、静态住宅 IP、独享数据中心 IP 等多种优质代理资源;
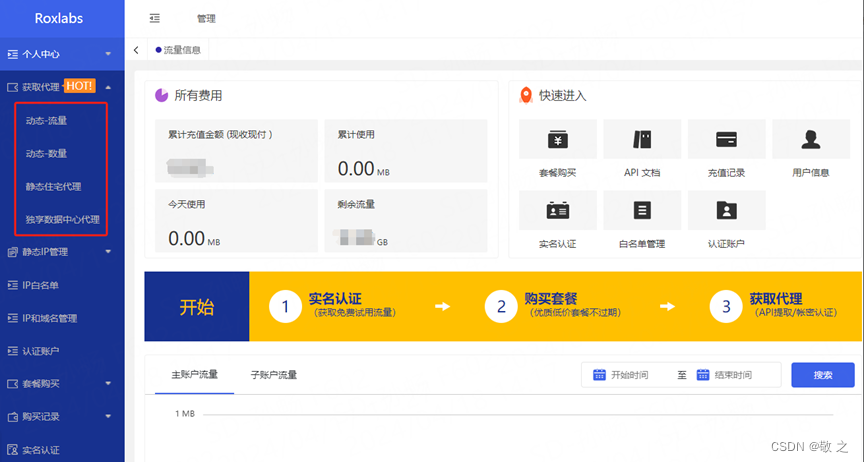
4.3 获取代理
获取代理有两种方式,一种是 API 提取,另一种是账密认证。
现在演示账密认证方式获取代理;
使用账密认证首先需要在 Roxlabs 个人后台“认证账户”板块添加认证账户;
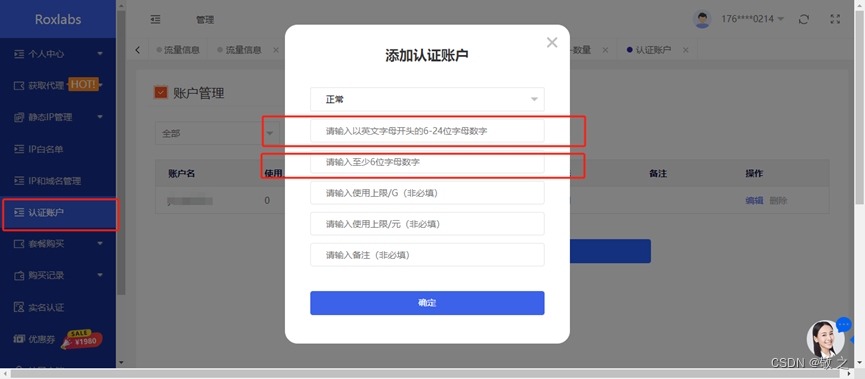
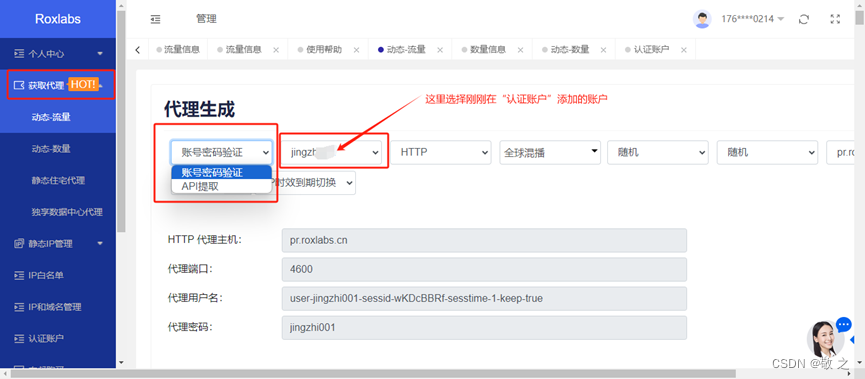
然后进入“获取代理”板块,选择“账号密码验证”生成方式,选择我们刚刚添加的认证账户;
此时获取到的 IP 就显示在本页面的代理列表中了;
4.4 配置代理设置
使用代码(Python)设置代理如下:
import _threadimport timeimport requests# 设置请求头headers = { "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_3 like Mac OS X) AppleWebKit/603.3.8 (KHTML, like Gecko) Mobile/14G60 MicroMessenger/6.5.19 NetType/4G Language/zh_TW",}# 测试地址mainUrl = 'https://ipinfo.io'def testUrl(): # 设置帐密代理 proxy = { 'http': 'http://认证账户名:认证账户密码@代理服务器地址:代理服务器端口', 'https': 'http://认证账户名:认证账户密码@代理服务器地址:代理服务器端口', } try: res = requests.get(mainUrl, headers=headers, proxies=proxy, timeout=10) print(res.status_code, res.text) except Exception as e: print("访问失败", e) pass# 开启10个线程进行测试for i in range(0, 10): _thread.start_new_thread(testUrl, ()) time.sleep(0.1)time.sleep(10)4.5 开始数据采集
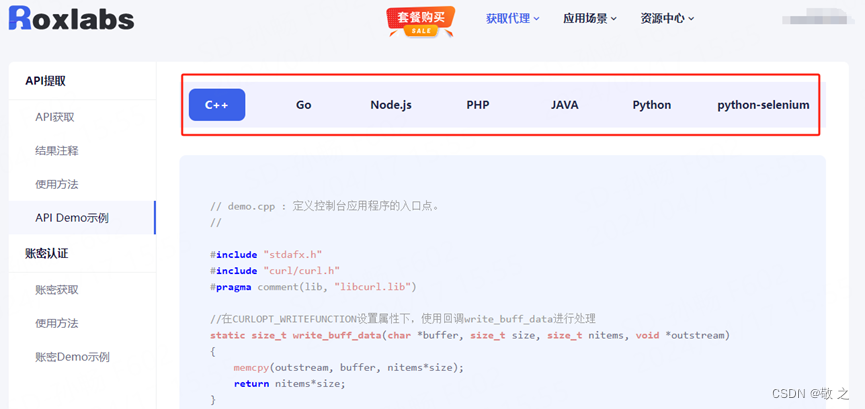
代理设置完成后就可以开始进行数据采集了。选择自己擅长的采集工具,在进行数据采集的过程中,我们也可以随时访问 Roxlabs 的个人中心,查看代理的使用情况。
Java、Node、PHP 等代码设置方式参见 Roxlabs 官网。
五、总结
作为一个专注于提供高质量住宅 IP 代理服务的平台,Roxlabs 为用户提供了一个全球范围访问网络的新视角。其全球覆盖、高质量服务、强大的数据采集能力以及严格的合规性和安全性保障,使得它成为了许多企业和个人在进行在线活动和数据采集时的首选工具。无论是保护个人隐私还是进行商业分析,Roxlabs 都能够为用户提供专业、可靠的代理解决方案。
注册领取免费流量,更多代理应用教程详见 Roxlabs官网 。