张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 » 内存 - 第7页
Android 开发——JVM复习小结_黎程雨的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 642次
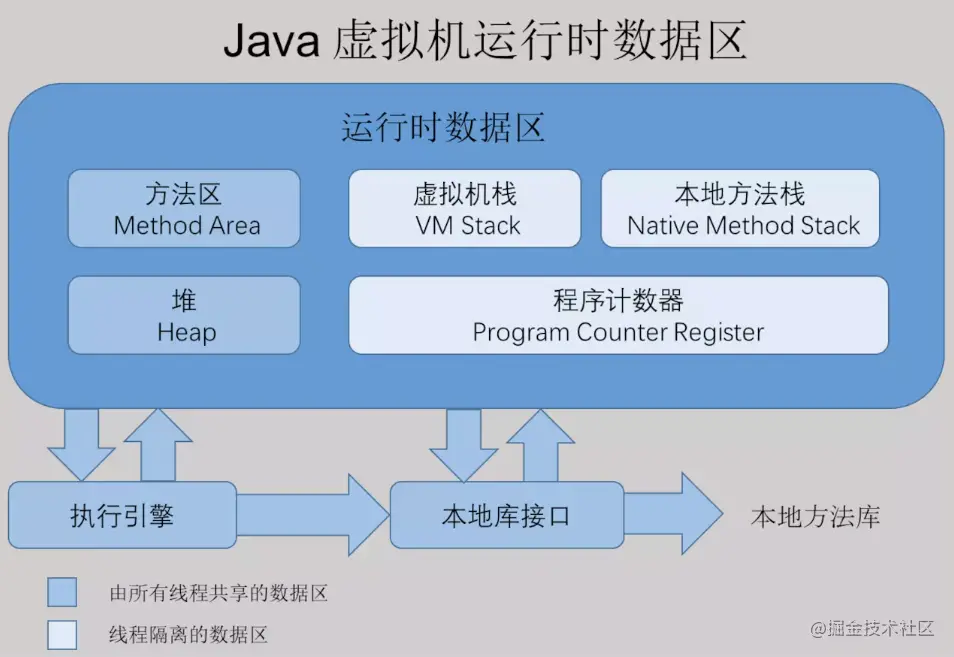
JVM运行时数据区域根据《Java虚拟机规范(JavaSE7版)》规定,Java虚拟机所管理的内存如下图所示。程序计数器内存空间小,线程私有.字节码解释器工作时就是通过改变程序计数器的值来选取下一条需要执行指令的字节码指令(主要是取下一条指令的字节码文件).分支,循环,跳转,异常处理,线程恢复等基础功能都依赖程序计数器来完成.如果线程正在执行一个Java方法,这个计数器记录的是正在执行的虚拟机字节码指令的地址;如果正在执行的是Nati
android匿名共享内存原理浅读_深耕安全技术研究
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 715次

理论基础android系统在应用程序框架层中提供了两个C++类MemoryHeapBase和MemoryBase来创建和管理匿名共享内存。如果一个进程需要与其他进程共享一块完整的匿名共享内存,那么就可以通过使用MemoryHeapBase类类创建这块匿名共享内存。如果一个进程创建一块匿名共享内存后,只希望与其他进程共享其中的一部分,那么就可以通过MemoryBase类来创建这块匿名共享内存。IMemory.h:定义内存相关类的接口ÿ
JVM之常见内存溢出(OutOfMemoryError)异常 ❤️ 每日积累【Day 26】_asd1358355022的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 673次
JVM之常见内存溢出(OutOfMemoryError)异常在《java虚拟机规范中》,除了程序计数器之外,虚拟内存的其他地方几个运行时区域都有可能发生OutOfMemoryError(OOM内存溢出)的情况.1、java堆内存溢出java堆内存使用于存储对象实例的,如果持续新建对象,切保证通过GCcRoots到这些对象一直是可达的(入下就是集合中存有对象一直
redis(七)、运维配置注意_先熬半个月的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 690次
一、开发运维的陷阱一、Linux配置优化一般来说,人们会比较关注redis本身得一些配置优化,例如AOF和RDB得配置优化、数据结构的配置优化,但往往会忽略掉操作系统的配置为redis服务提供更好的运行环境。1、内存分配控制(1)、vm.overcommit_memory有时在启动redis时可能会出现这样的日志:#WARNINGovercommit_memoryissetto0!Backgroundsavemayfailunderlowmemorycondition.Tofixthisiss
2021Java面试题库大全(内部资源)_code_javaer的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 702次
前言:由于篇幅有限,只展示了部分知识点,如需更多电子资源,无偿共享欢迎评论区留言+1!或者加文尾助理微信!(备注007)腾讯的Java面试题TCP和UDP的区别,TCP为什么是三次握手,不是两次。答:1、因为tcp是全双工协议,区别在于前者可靠,后者不可靠,以及效率更高。 Dubbo面试题dubbo和dubbox之间的区别?答:Dubbox和Dubbo本质上没有区别,
Java面试题超详细整理《JVM篇》_龙源IT 的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 670次
JVM由那些部分组成,运行流程是什么?JVM的由以下几部分组成:类加载器(ClassLoader):Java的动态类加载功能由ClassLoader子系统处理。它加载,链接。并在运行时(而非编译时)首次引用类时初始化类文件。运行时数据区(RuntimeDataArea):Java虚拟机在执行Java程序的过程中会把它管理的内存分为若干个不
10W+字C语言硬核总结(一),值得阅读收藏!_C语言与CPP编程的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 564次
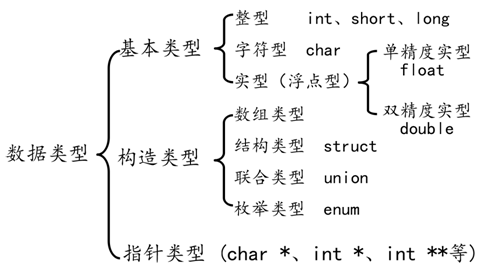
一.C语言概述欢迎大家来到c语言的世界,c语言是一种强大的专业化的编程语言。程序员必备硬核资料,点击下载1.1C语言的起源贝尔实验室的DennisRitchie在1972年开发了C,当时他正与kenThompson一起设计UNIX操作系统,然而,C并不是完全由Ritchie构想出来的。它来自Thompson的B语言。1.2使用C语言的理由在过去的几十年中,c语言已成为最流行和最重要的编程语言之一。它之所以得到发展,是因为人们尝试使用它后都喜欢它。过去很多年中,许多人从c语言转而使用更强大的c++语言&#x
Java岗大厂面试百日冲刺
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 662次
大家好,我是陈哈哈,北漂五年。相信大家和我一样,都有一个大厂梦,作为一名资深Java选手,深知面试重要性,接下来我准备用100天时间,基于Java岗面试中的高频面试题,以每日3题的形式,带你过一遍热门面试题及恰如其分的解答。 一路走来,随着问题加深,发现不会的也愈来愈多。但底气着实足了不少,相信不少朋友和我一样,日积月累才是最
有关C语言内存管理的一些总结_Z_FIEND°的博客
发布 : zsy861 | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 593次
C语言内存管理总结 文章目录目录C语言内存管理总结文章目录前言一、内存管理简介以及常见的内存使用错误二、内存分类1.栈区(stack)2.全局区3.常量区4.堆区(heap)三、malloc(),calloc(),realloc()函数1.malloc:2.calloc:3.realloc:四、strcpy(),memcpy(),memmove()函数1.strcpy:2.memcpy:3.memmove:4.memset:五、栈区&
细谈Go变量的内存分布_菜刚RyuGou的专栏
发布 : zsy861 | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 555次
我们程序中的变量大多被分配在内存的两个区域:statck和heap。stack和heap首先让我们一起来回顾一下进程的内存分配:我们写的程序代码跑起来后,会是一个进程;OS会给我们的进程分配内存;内存结构大致如下:OS给一个进程分配的内存空间大致可以分为:代码区、全局数据区、栈(stack)、堆(heap)、环境变量区域以及中间空白的缓冲区六个部分。其中,数据的增长路径除栈(stack)是由高到低之外,其余的均是由低到高(可看图中数据箭头)。我们思考一下,为什么栈(stack)区这么特殊和其他区域路
search zhannei
最新文章
-
- 重生后送外卖,捡到的失忆女友竟是豪门千金
- 最没用的儿子
- 我在星际直播年代文里当团宠
- 穿成对照组前妻,我带娃上综艺摆烂
- 极寒末世我囤百亿物资,坐看前夫一家冻成狗
- 出狱后,我透视鉴宝养女儿
- 互换曝光后,双胞女帝非我不可
- 人间一渡劫相思
- 全文金牌律师老公纵容秘书害死我妈后,我让他身败名裂了爽文(楚行之沈南乔)列表_全文金牌律师老公纵容秘书害死我妈后,我让他身败名裂了爽文
- 侯府贤妻主母糙汉一堂亲(沈时微陆沉),侯府贤妻主母糙汉一堂亲
- 完结文夫君为了给小妾美容养颜,竟取我妹妹的心头血列表_完结文夫君为了给小妾美容养颜,竟取我妹妹的心头血(苏晚陆景琛陆景渊)
- 林汐陆川小说名字_九零:钱多事少,老公不回家真香无删去广告精彩章节手机内在线试读
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1