C++ 引用(&)的超详细解析(小白必看系列)
目录
一、前言
二、引用的概念介绍
三、引用的五大特性
? 引用在定义时必须初始化
? 一个变量可以有多个引用
? 一个引用可以继续有引用
? 引用一旦引用一个实体,再不能引用其他实体
? 可以对任何类型做引用【变量、指针…】
四、引用的两种使用场景
1、做参数
a.案例一:交换两数
b.案例二:单链表的头结点修改【SLNode*& p】
2、做返回值【⭐⭐⭐】
① 引入:栈区与静态区的对比
② 优化:传引用返回【权力反转】
③ 理解:引用返回的危害 - 造成未定义的行为【薛定谔的猫?】
④ 结语:正确认识【传值返回】与【传引用返回】
五、传值、传引用效率对比
1、函数传参对比
2、返回值的对比
六、常引用
1、权限放大【×】
2、权限保持【✔】
3、权限缩小【✔】
4、拓展
4.1如何给常量取别名
4.2临时变量具有常性(重点)
5、 对权限控制的用处
七、引用与指针的区别总结
八、总结与提炼
九、共勉
一、前言
本次博客来讲解以下C++ 的 引用 是如何运用的。那么问题来了,为什么要用到引用?用C语言中的指针不是挺好的吗 ?
其实,在C语言中的指针会引发很多的难题,比如【两数交换】的时候因为函数内部的概念不会引发外部的变化,使得我们需要传入两个需要交换数的地址,在函数内部进行解引用才可才可以交换二者的值
另一块就是在数据结构中的【单链表】,面对二级指针的恐惧?是否还伴随在你的身边,因为考虑到要修改单链表的头结点,所以光是传入指针然后用指针来接受还不够,面对普通变量要使用一指针来进行修改,那对于一级指针就需要用到二级指针来进行修改,此时我们就要传入一级指针的地址,才可以在函数内部真正得修改这个单链表的结构
所以,为了解决上述简化上述问题,C++中引入了一大特性 —— 【引用】,在学习了引用之后,就不要担心是否要传入变量的地址还是指针的地址啦,然后我们一起来学习吧!

二、引用的概念介绍
引用不是新定义一个变量,而是给已存在变量取了一个别名,编译器不会为引用变量开辟内存空间,它和它引用的变量共用同一块内存空间
比如:李逵,在家称为"铁牛",江湖上人称"黑旋风"。【水浒108将各个有称号】

❓那要怎么去“引用”呢?❓
此时需要使用到我们在C语言中学习到的一个操作符叫做[&],它是【按位与】,也是【取地址】,但是在C++中呢,它叫做【引用】
❓ 它的语法是怎样的呢?❓
类型& 引用变量名(对象名) = 引用实体;
int a = 10;int& b = a; // b 是 a 的别名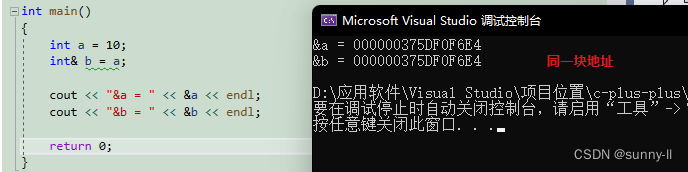
三、引用的五大特性
? 引用在定义时必须初始化
? 一个变量可以有多个引用
? 一个引用可以继续有引用
? 引用一旦引用一个实体,再不能引用其他实体
? 可以对任何类型做引用【变量、指针…】
? 引用在定义时必须初始化
首先来看第一个,若是定义了一个引用类型的变量int&,那么就必须要去对其进行一个初始化,指定一个其引用的对象,否则就会报错 int a = 10;int& b = a;int& c;
? 一个变量可以有多个引用
对于第二个特定,通俗一点来说就是b引用了a,那么b等价于a;此时c也可以引用a,那么c也等价于a,此时a == b == c你可以无限对a进行引用,直到把操作系统的内存申请光为止(应该没那么狠吧) int a = 10;int& b = a;int& c = a;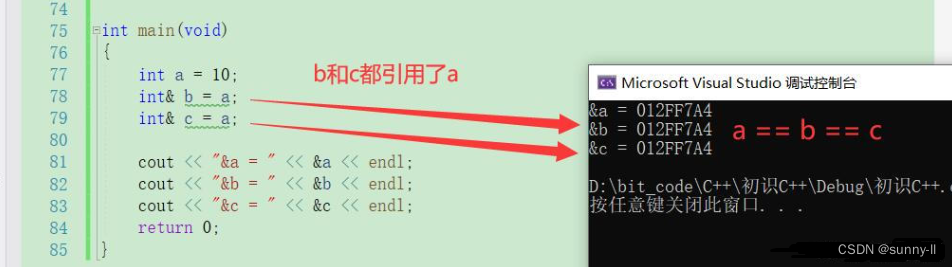
? 一个引用可以继续有引用
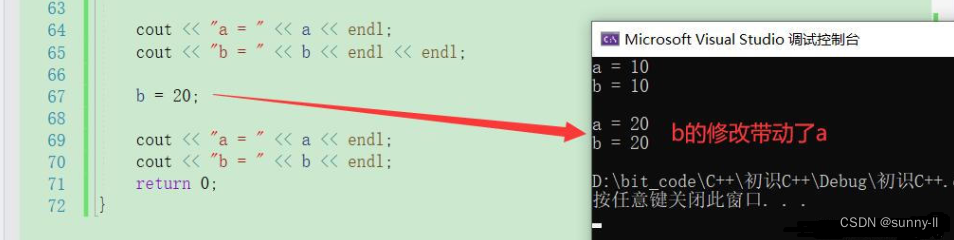
对于第三个特性而言,其实就是一个传递性。当一个变量引用了另一个变量之后,其他变量还可以再对其进行一个引用。通过运行就可以看出它们也都是属于同一块空间int a = 10;int& b = a;int& c = b;
? 引用一旦引用一个实体,再不能引用其他实体
这个特性很重要【⭐】,要牢记。因为上面有说到对于引用而言在定义时必须初始化,那么在定义结束完后它就已经引用了一个值,无法在对其去进行修改了,这是非法的!int a = 10;int c = 20;int& b = a;int& b = c;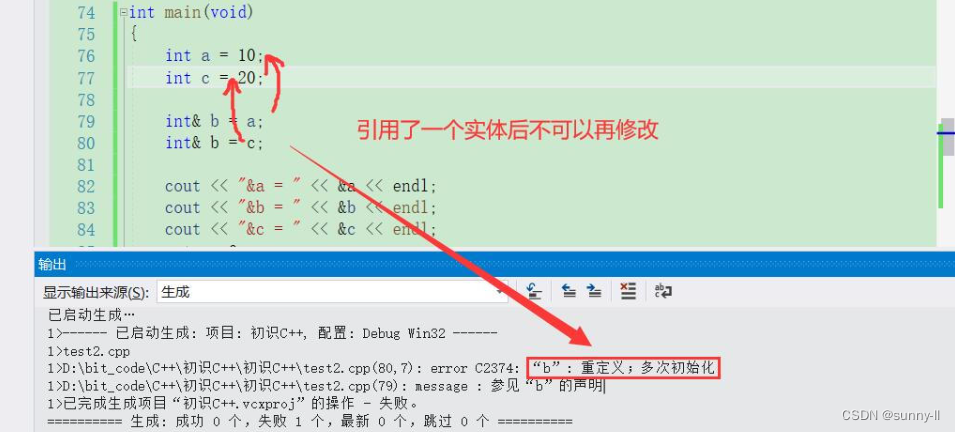
? 可以对任何类型做引用【变量、指针…】
最后一点特性作为拓展。上面我们介绍了对于变量而言可以有引用,当然除了整型之外其他类型也是可以的看到下面c1是double类型,c2引用c1,所以c2也是double类型的。其他类型可以自己试试看 double c1 = 3.14;double& c2 = c1;然后我们重点来说说有关指针这一块的引用【⭐】
int a = 10;int* p = &a;int*& q = p;int*代表q是一个指针类型,&则表示指针q将会去引用另一个指针 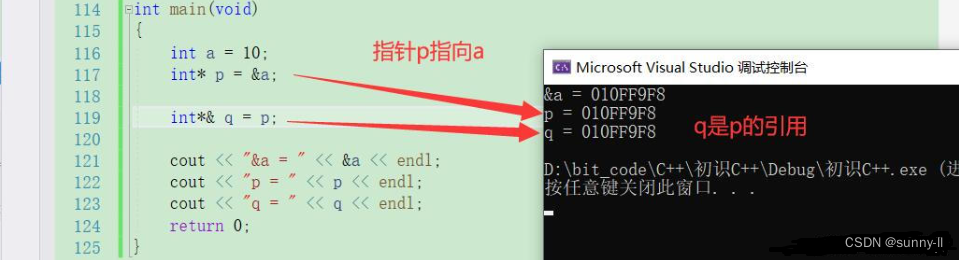
以上就是有关C++中的引用所要介绍的特性,还望读者牢记?
四、引用的两种使用场景
1、做参数
a.案例一:交换两数
还记得我们在C语言中学习过的【交换两数】吗?需要传入两个变量的地址,从而可以在函数内部通过指针的解引用来访问到所指向变量的那块地址从而对里面的内部进行一个修改
相信这也是我们在初次学习指针时接触的一个东西,也是最经典的一块内容,那除了使用【指针】的这种形式,你还有没有其他的方法呢?没错,就是使用我们刚学的引用
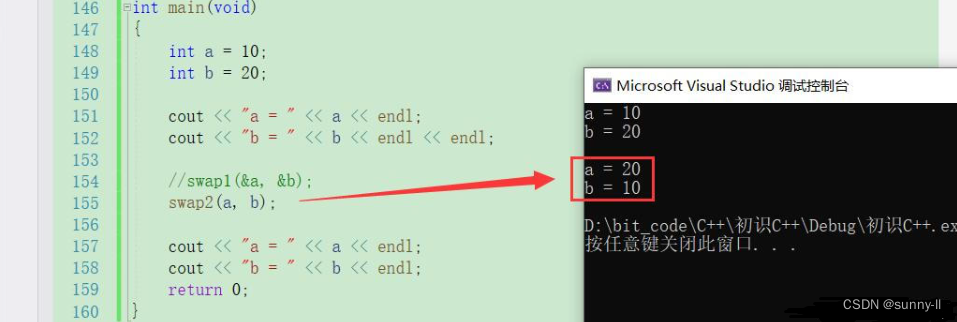
void swap1(int* px, int* py){int t = *px;*px = *py;*py = t;}swap1(&a, &b);void swap2(int& x, int& y){int t = x;x = y;y = t;}swap2(a, b);通过运行结果来看确实也可以起到交换两数的功能
b.案例二:单链表的头结点修改【SLNode*& p】
在讲解引用的特性时,我说到了引用的类型不仅仅限于普通变量,还可以是指针。但上面说的是普通指针,接下去我们来说说结构体指针,也涉及到了引用类型在做参数时的场景
看到如下一段代码,我定义了一个链表结点的结构体,还记得我们在链表章节学习过的头插,因为涉及到会修改链表的头结点,因此函数内部的修改不会导致外部一起修改,继而我们需要传入这个链表的地址,然后使用二级指针来进行接收,相信这一块一定令很多小伙伴非常头疼?
typedef struct SingleNode {struct SingleNode * next;int val;}SLNode;void PushFront(SLNode** SList, int x){SLNode* newNode = BuyNode(x);newNode->next = *SList;*SList = newNode;}int main(void){SLNode* slist;PushFront(&slist, 1);return 0;}此时
PushFront()内部我们也可以去做一个修改,直接使用形参SList即可,无需考虑到要对二级指针进行解引用变为一级指针 void PushFront(SLNode*& SList, int x){SLNode* newNode = BuyNode(x);newNode->next = SList;SList = newNode;}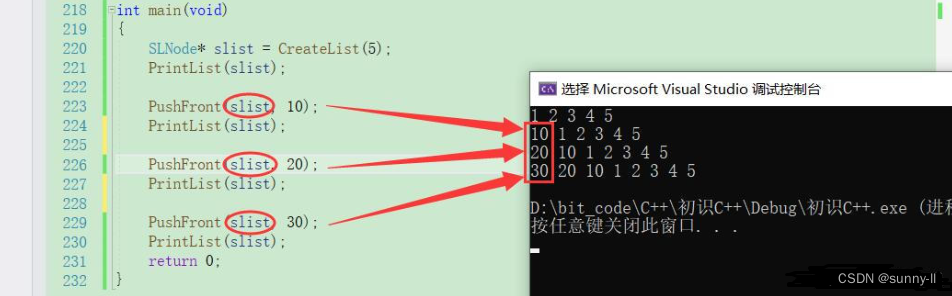
2、做返回值【⭐⭐⭐】
首先看一下,下面的两个Count函数,你觉得它们哪里不太一样呢?
① 引入:栈区与静态区的对比
int Count(){int n = 0;n++;// ...return n;}int Count(){static int n = 0;n++;// ...return n;}
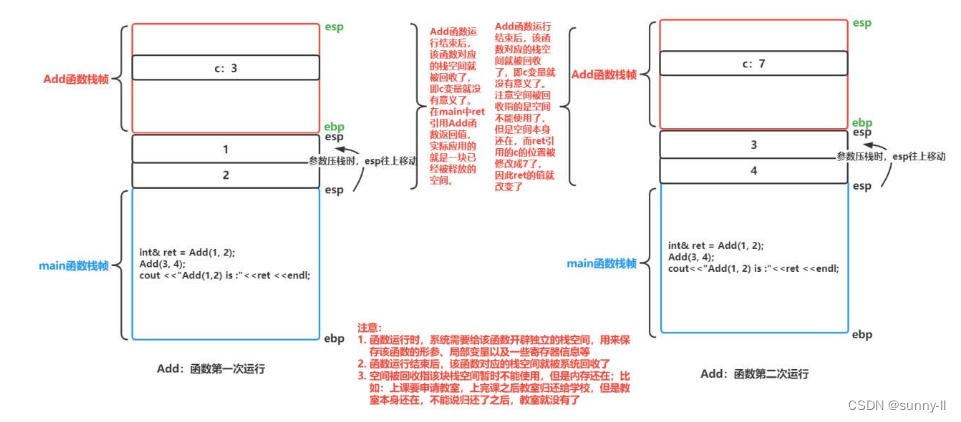
上面通过画出两个Count()函数的堆栈图了解到了函数中临时变量和静态变量所在空间是不同的,那当执行完这个函数之后其所在栈帧一定会销毁,此时又会发生怎样的故事呢?我们继续看下去
首先你必须要清楚的一些点:
当我们定义变量 / 创建函数 / 申请堆内存的空间时,系统会把这块空间的使用权给到你?,那么这块空间你在使用的时候是被保护的?,被人无法轻易来访问、入侵你的这块空间。但是当你将这个空间销毁之后,它并不是不存在了、被粉碎了,只是你把对于这块空间的使用权还给操作系统了,不过这块空间还是存在的,因此你可以通过某种手段访问到这块空间?,由于操作系统又收回了这块空间的使用权,继而它便可以对其进行再度分配给其他的进程,那它就可能又属于别人了所以你通过某种手段去访问这个空间的时候其实属于一种非法访问⚠,可是呢这种非法访问又不一定会报错,就像之前我们说到过的数组越界、访问野指针都不一定会存在报错。为什么?因为编译器对于程序的检查是一种【抽查行为】,不一定能百分百查到,所以你在通过某些手段又再次访问到这块空间后所做的一些事都是存在一种【随机性】的上面所说的这些还望读者一定要牢记!!!因为这对于下文的理解以及后续的学习都是非常有帮助的好,接下去我们回归正题,继续来说一说有关函数栈帧销毁之后这个返回值是如何给到这个外界的值做接收的。相信你在本小节一开始讲到的这些内容之后再来看下图一定是非常得清晰
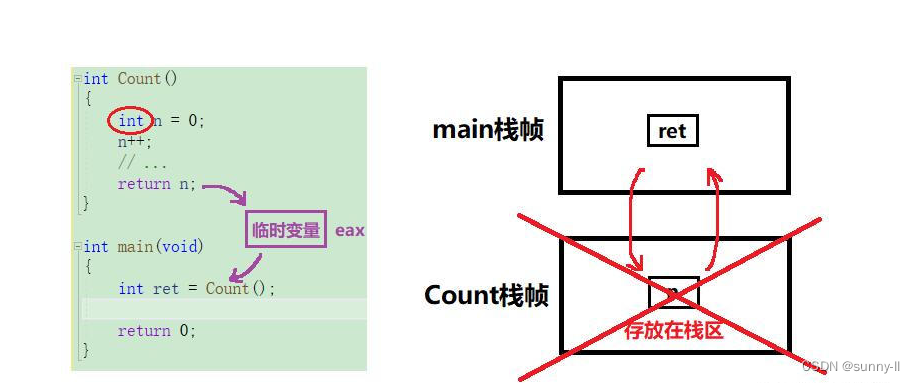
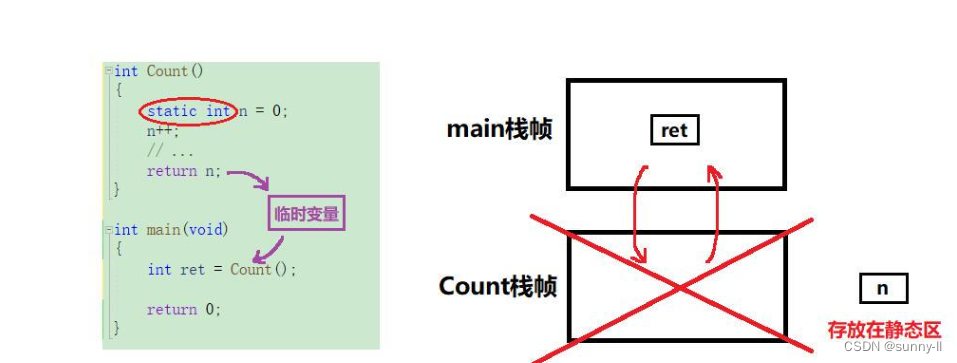
【总结一下】:
当需要将函数中的临时变量返回时,无论这个变量是在栈区、堆区或者静态区开辟空间,都会通过一个临时变量去充当返回值【小一点的话可能是寄存器eax,大一点可能是在上一层栈帧开好的】然后再返回给外界的值做接受 ② 优化:传引用返回【权力反转】
通过上面的示例你应该会觉得对于【栈区】而言使用临时变量返回还是合情合理的,可以【静态区】为什么也要通过临时变量来返回呢,这不是多此一举吗?
那有什么办法可以免去这种拷贝的过程,直接将得出的结果返回回去呢?那就是引用返回int& Count(){static int n = 0;n++;// ...return n;}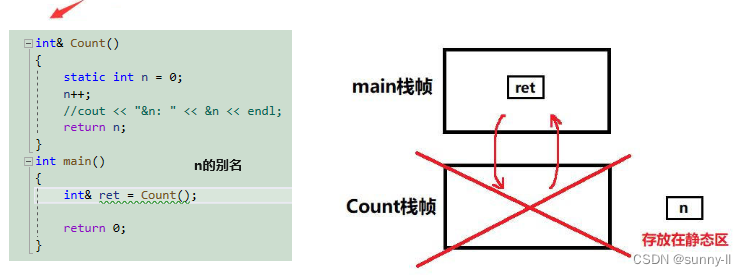
这里ret和n的地址一样,也就意味着ret其实就是n的别名。综上,传值返回和传引用的返回的区别如下:
传值返回:会有一个拷贝传引用返回:没有这个拷贝了,返回的直接就是返回变量的别名③ 理解:引用返回的危害 - 造成未定义的行为【薛定谔的猫?】
在上面,我介绍到了一种对函数返回进行优化的方法 ——> 传引用返回,于是有的同学就觉得它很高大上,因此所以函数都使用了传引用返回,你认为可以吗?
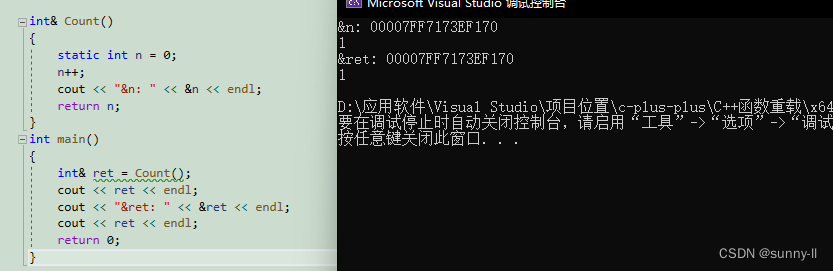
来看看下面这段代码,你认为它的输出结果是什么呢?是1吗❓ 还是随机值❓ 亦或者是其他值int& Count(){int n = 0;n++;cout << "&n: " << &n << endl;return n;}int main(){int& ret = Count();cout << ret << endl;cout << "&ret: " << &ret << endl;cout << ret << endl;return 0;}
正确的写法
int& Count(){static int n = 0;n++;cout << "&n: " << &n << endl;return n;}int main(){int& ret = Count();cout << ret << endl;cout << "&ret: " << &ret << endl;cout << ret << endl;return 0;}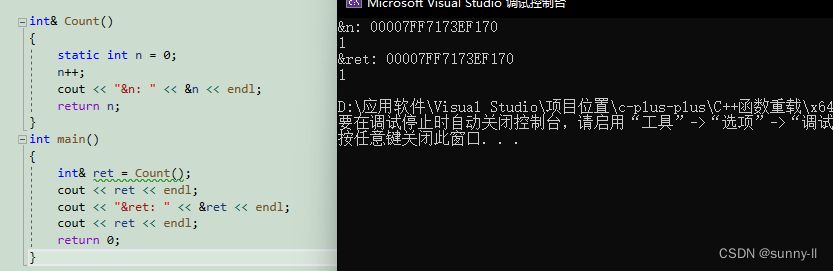
总结: 引用返回 主要对于像静态变量、全局变量等这些出了作用域不会销毁的对象,就可以使用【传引用返回】
在举一个例子:
// 注意: static 只能初始化以此int& Add(int a, int b){ int c = 0;c = a + b;return c;}int main(){int& ret = Add(1, 2);Add(3, 4); // static 只能初始化以此 所以值不会变printf("Hello\n");cout << "Add(1, 2) is :" << ret << endl; // 随机值return 0;}
此时因为 c 出栈之后就会被销毁掉,所以输出的就是一个随机值。
进行改进 加入 static
// 注意: static 只能初始化以此int& Add(int a, int b){ static int c = 0;c = a + b;return c;}int main(){int& ret = Add(1, 2);cout << "Add(1, 2) is :" << ret << endl; // 3Add(3, 4); // static 只能初始化以此 所以值不会变printf("Hello\n");cout << "Add(1, 2) is :" << ret << endl; // 7return 0;}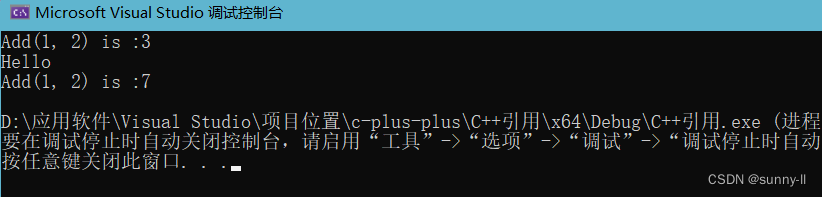
④ 结语:正确认识【传值返回】与【传引用返回】
好了,看到这里,相信你对引用做返回值的使用场景应该有了很深刻的理解,来做个总结
如果你觉得很难理解,那说明你是个正常人,C++引用这一块尤其是做函数返回值的时候是最难理解的,但是通过画图去理解分析就会好很多了,通过画出这个函数的栈帧图就可以很清晰地看明白所有的一切
最后的话再带读者来回顾一下【传值返回】和【传引用返回】
传值返回:如果已经还给系统了,随着当前作用域的结束而一起销毁的 传引用返回:只要是出了当前作用域不会销毁,并且函数栈帧销毁不影响其生命周期【全局变量、静态变量、上一层栈帧、malloc的】五、传值、传引用效率对比
在上一模块,我介绍了有关引用的两种使用场景,相信你在学习了之后也是一头雾水,学它有什么用呢?和普通的传值有何区别?本模块就来对【传值】和【传引用】这两种方式来做一个对比
1、函数传参对比
首先我们来看看以值和引用分别作为函数参数有什么不同#include <time.h>struct A { int a[10000];};void TestFunc1(A a){}void TestFunc2(A& a){}void TestRefAndValue(){A a;// 以值作为函数参数size_t begin1 = clock();for (size_t i = 0; i < 10000; ++i){TestFunc1(a);}size_t end1 = clock();// 以引用作为函数参数size_t begin2 = clock();for (size_t i = 0; i < 10000; ++i){TestFunc2(a);}size_t end2 = clock();// 分别计算两个函数运行结束后的时间cout << "TestFunc1(A)-time:" << end1 - begin1 << endl << endl;cout << "TestFunc2(A&)-time:" << end2 - begin2 << endl;}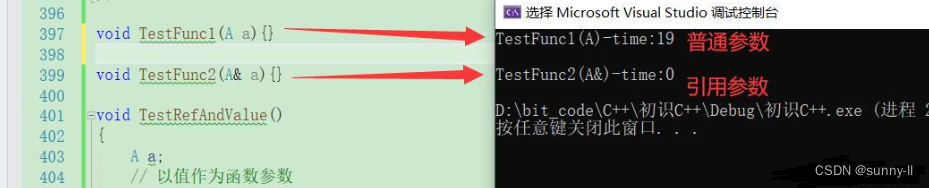
2、返回值的对比
不过呢,这个时间其实还看不出引用的强大之处,我们通过另一个场景,来看看值返回与引用返回二者的差距是否会大一些
// 值返回A TestFunc1() {return a; }// 引用返回A& TestFunc2(){ return a;}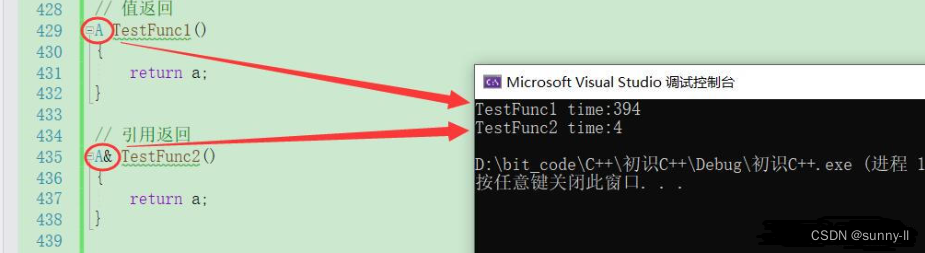
六、常引用
看到这里之后你对C++中的【引用】应该是有一个很清晰的概念了,也知道了它的强大之处。接下去我来普及一个东西叫做【常引用】,也是引用里面很重要的一块知识点
1、权限放大【×】
权限放大 —— 用普通的变量替代只读变量
首先来看下下面这段代码,你认为什么地方有问题?
变量b对a进行了引用,这一点肯定不会有问题;不过问题就出在这个变量对c的引用,有同学说:“为什么呢?不都是引用吗?”那你就要注意到这个const了,首先对于【const】关键字修饰的变量具有常性,是不可以被随意修改的,但此时变量d引用了c,那么c和d就从属于同一块地址了,不过变量d不具有常性,因此它是可以被修改的。那么这个时候就会产生歧义了,也就出现了问题 这种引用形式叫做【权限放大】,本来我这个c是不具有再度修改权限的,但是你引用了我,那就可以修改了,这也就破坏了原先的规则?int a = 1;int& b = a;const int c = 2;int& d = c;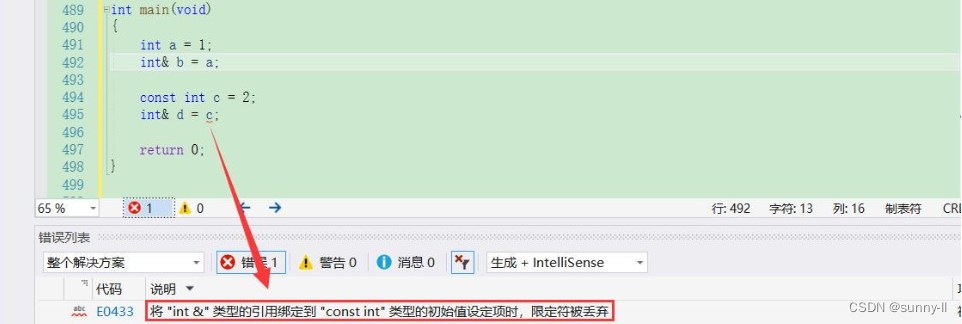
2、权限保持【✔】
那我们修改一下,不要让权限放大了,给变量d也加上一个常属性,让他俩一样,看看是否可行const int c = 2;const int& d = c;
3、权限缩小【✔】
权限缩小 —— 用只读的变量替代普通变量
那既然权限保持不会出现问题,若是我现在将权限缩小会不会出现问题呢?int c = 2;const int& d = c;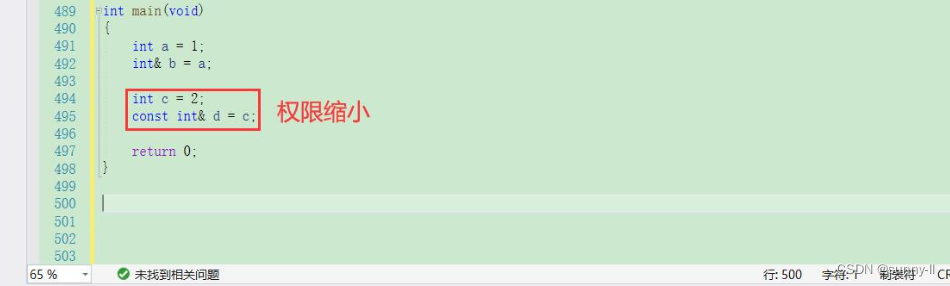
4、拓展
4.1如何给常量取别名
可以给常量取别名吗?
int& c = 20; // err其实是不可以直接进行取别名的,但是我们加上const就可以了:
const int& c = 20; // right4.2临时变量具有常性(重点)
看如下代码:
double d = 2.2;int& e = d;此刻的 e 是否为 d 的别名?

很明显不可以,编译器发生错误。但是我加上const,发现它竟然就不会出错了:
怎么解释上述代码呢?这就需要我们先回顾下C语言的类型转换
C++本身是在C语言的基础上走的,C语言在相似类型是允许隐式类型转换的。大给小会截断,小给大会提升。看如下代码:
double d = 2.2;int f = d;编译器运行后:
这里的会丢失数据其实就是会丢失精度
这里在把d的值赋给f时并不是直接赋值的,会把d的整数部分取出来,赋值给一个临时变量,该临时变量大小4个字节,随后再把这个临时变量给给f
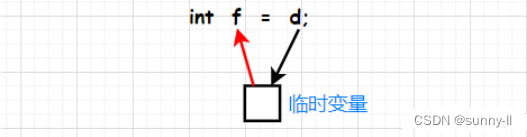
临时变量具有常性,就像被const修饰了一样,不能被修改
谈到这,你就应该能够理解上文的这段代码为什么要加上const才能编译通过:double d = 2.2;const int& e = d;答案很简单, 这里e引用的是临时变量,临时变量具有常性,不能直接引用, 否则就是放大了权限,加上const才能保证其权限不变
可能又会有人提问了,那为什么这段代码在赋值的时候不加上const呢?
double d = 2.2;int f = d;此时又有人提问了,那么此时的e还是对d的引用吗?
double d = 2.2;const int& e = d;
5、 对权限控制的用处
这里简单提下,例如这个传参的问题。
如若函数写出普通的引用,那么很多参数可能会传不过来:

仔细看这段代码,只有a能正常传过去,后面的均传不过去,因为后面传的参数均涉及权限放大,固然编译器会出错
但是当我们在函数的形参那加上const呢?
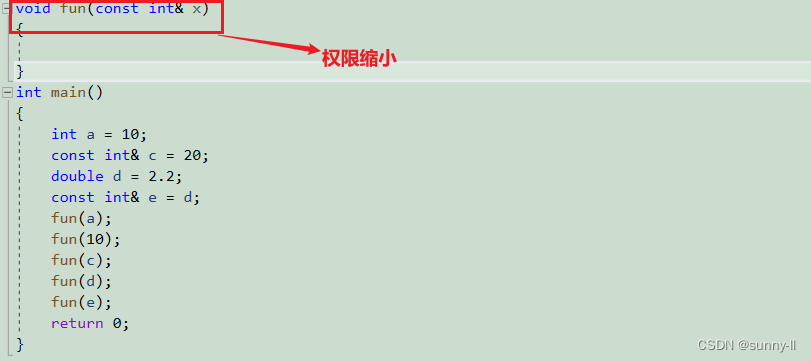
加了const后编译器就不会报错了
七、引用与指针的区别总结
引用和指针的不同点:
引用概念上定义一个变量的别名,指针存储一个变量地址引用在定义时必须初始化,指针没有要求引用在初始化时引用一个实体后,就不能再引用其他实体,而指针可以在任何时候指向任何一个同类型实体没有NULL引用,但有NULL指针在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节)引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小有多级指针,但是没有多级引用访问实体方式不同,指针需要显式解引用,引用编译器自己处理引用比指针使用起来相对更安全接下来就上述指针与引用不同点做详细解析:
引用在定义时必须初始化,指针没有要求int& r; //err 引用没有初始化int* p; //right 指针可以不初始化double d = 2.2;double& r = d;cout << sizeof(r) << endl; //8
在底层实现上实际是有空间的,因为引用是按照指针方式来实现的。
int main(){int a = 10;//语法角度而言:ra是a的别名,没有额外开空间//底层的角度:它们是一样的方式实现的int& ra = a;ra = 20;//语法角度而言:pa存储a的空间地址,pa开了4/8字节的空间//底层的角度:它们是一样的方式实现的int* pa = &a;*pa = 20;return 0;}我们来看下引用和指针的汇编代码对比:
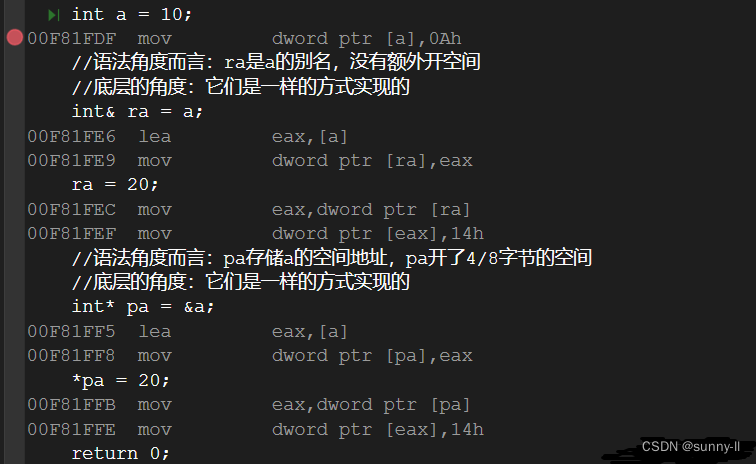
通过反汇编我们可以看出:引用是按照指针方式来实现的。
八、总结与提炼
最后,来总结一下本文所学习的内容?
首先我们了解了什么是引用,知晓了原来引用就是【取别名】,主体与被引用体使用的都是同一块空间接下去学习了有关引用的五大特性,知道了在定义时必须初始化一个变量可以有多个引用一个引用可以继续有引用用一旦引用一个实体,再不能引用其他实体可以对任何类型做引用有了基本的概念和理解之后,我们就开始真正地使用引用,关注到它被使用的两种场景,分别是:① 做参数;② 做返回值;这一模块讲解地非常细致,里面不仅包含引用相关的很多难点,而且还有一些内存空间相关的知识,特别是对于【引用做返回值】这一块读者一定要细细品味?了解了引用的两种使用场景后,便通过传值、传引用去分别比较了在这两种场景下二者的差距,很明显引用还是更胜一筹,比较拷贝是需要耗费的时间接下去拓展了一点,说了引用的另一块知识点 ——【常引用】,我们日常在使用引用的时候,一定要注意千万不可将权限放大,只可做到权限保持或者是权限缩小最后的最后,又去对比了指针和引用二者区别所在,知道了原来在底层的实现中【引用】和【指针】其实差不太多,都是需要开辟空间的。但二者还是存在很多的区别,都得读者列出来了,这些都是在笔试面试当中常考的内容,还望谨记!九、共勉
以下就是我对C++ 引用(&)的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新对C++ 类和对象的理解,请持续关注我哦!!!

登录后可发表评论
点击登录