通过yfinance访问金融数据—获取数据
yfinance介绍
yfinance是一个Python开源工具,使用Yahoo公开api访问金融数据,地址finance.Yahoo.com从2021.11.1开始停止对国内的访问服务,使用需要在国外或者使用代理请求。
三大模块:
yf.Ticker
几乎所有的方法都在Ticker模块中。
例如:将 yfinance 导入为 yf 并为特定代码(股票)创建一个代码对象:
import yfinance as yf aapl= yf.Ticker("aapl")aapl
现在可以用这个aapl股票代码对象——在其上调用各种方法。要获取历史数据,可以使用 history() 方法。
history() 方法参数:
period:要下载的数据周期(使用周期参数或使用start和end),有效周期为:“1d”、“5d”、“1mo”、“3mo”、“6mo”、“1y”、“2y”、“5y”、“10y”、“ytd”、“max”(最高点)。interval:数据间隔(1m 数据仅适用于最近 7 天的数据,最近 60 天的数据间隔 <1d),有效间隔为:“1m”、“2m”、“5m”、“15m”、“30m”、“60m”、“90m”、“1h”、“1d”、“5d”、“1wk”、“1mo”、“3mo”start:格式为 (yyyy-mm-dd) 或日期时间。•end: 格式为 (yyyy-mm-dd) 或日期时间。prepost:在结果中包涵 Pre 和 Post 常规市场数据(默认为 False)- 通常不需要将其从 False 更改。*auto_adjust:自动调整所有 OHLC(开盘价/最高价/最低价/收盘价)(默认为 True)。actions:下载股票分红和股票分割事件 (默认为True)。我们只需更改period(或者start和end)和间隔参数。
例如,要获取 Apple 在 02/06/2020 和 07/06/2020(英国格式)之间的 1 分钟历史数据,我们只需使用我们创建并运行的股票代码对象:
aapl_historical = aapl.history(start="2023-02-05", end="2023-02-11", interval="1m")aapl_historical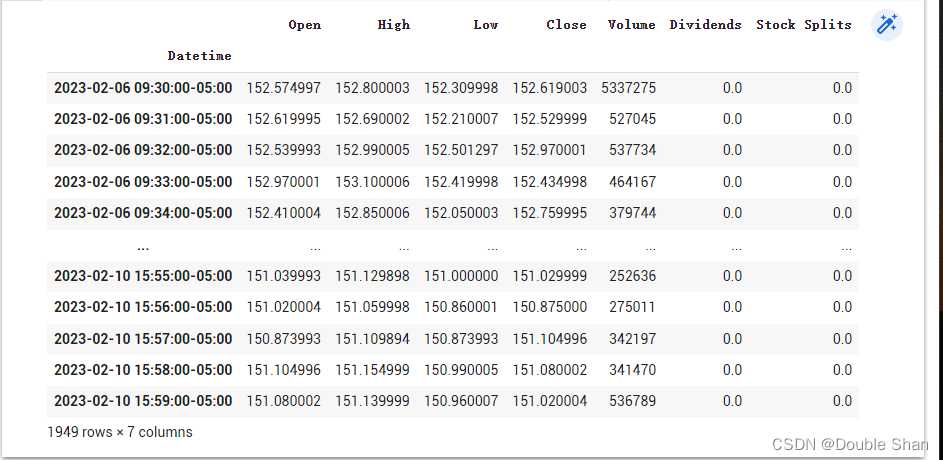
查询公司分红和拆股信息:
aapl.actions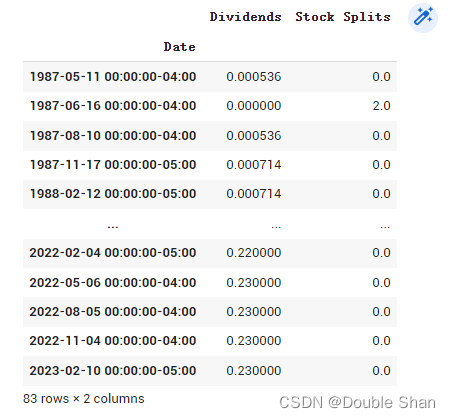
获得公司财报
aapl.financialsyf.download
一次下载多个股票的历史数据
采用与股票代码上的history()方法大致相同的参数,其他参数如下:group_by:按列或股票代码分组(‘column/ticker’,默认为’column’)。threads:使用线程进行大规模下载(True/False/Integer。proxy:如果要使用代理服务器下载数据的代理 URL(可选,默认为 None)。例如,要一次性获取 Amazon、Apple 和 Google 的数据,我们可以运行:
data = yf.download("AMZN AAPL GOOG", start="2017-01-01", end="2017-04-30") data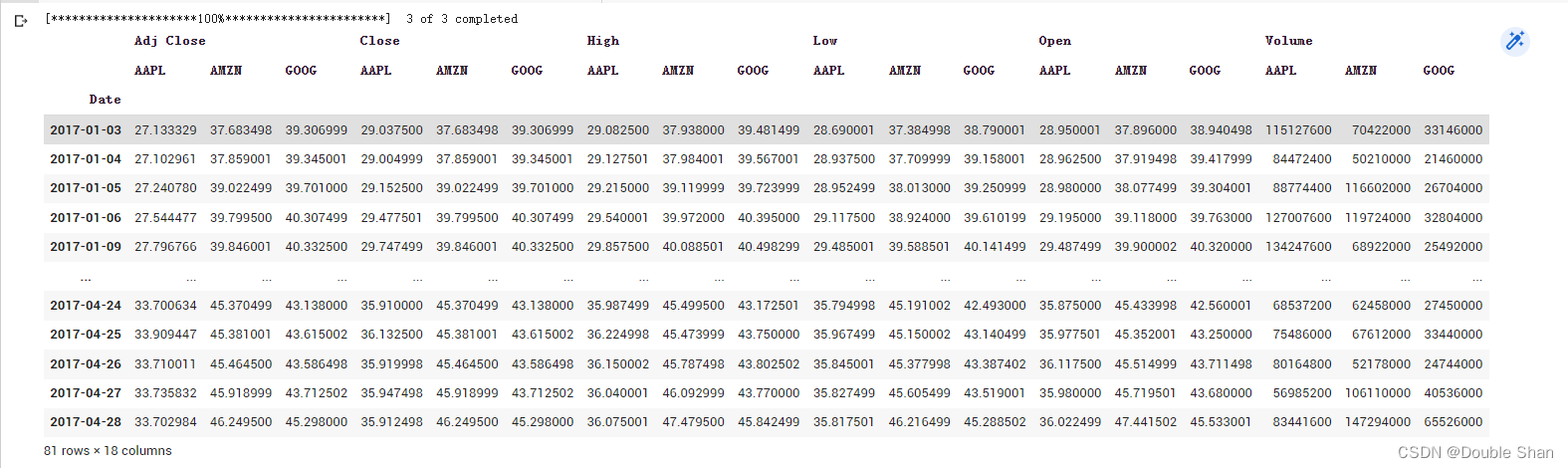
如果我们想按股票代码而不是开盘价/最高价/最低价/收盘价进行分组,我们可以这样做:
data = yf.download("AMZN AAPL GOOG", start="2017-01-01",end="2017-04-30", group_by='tickers')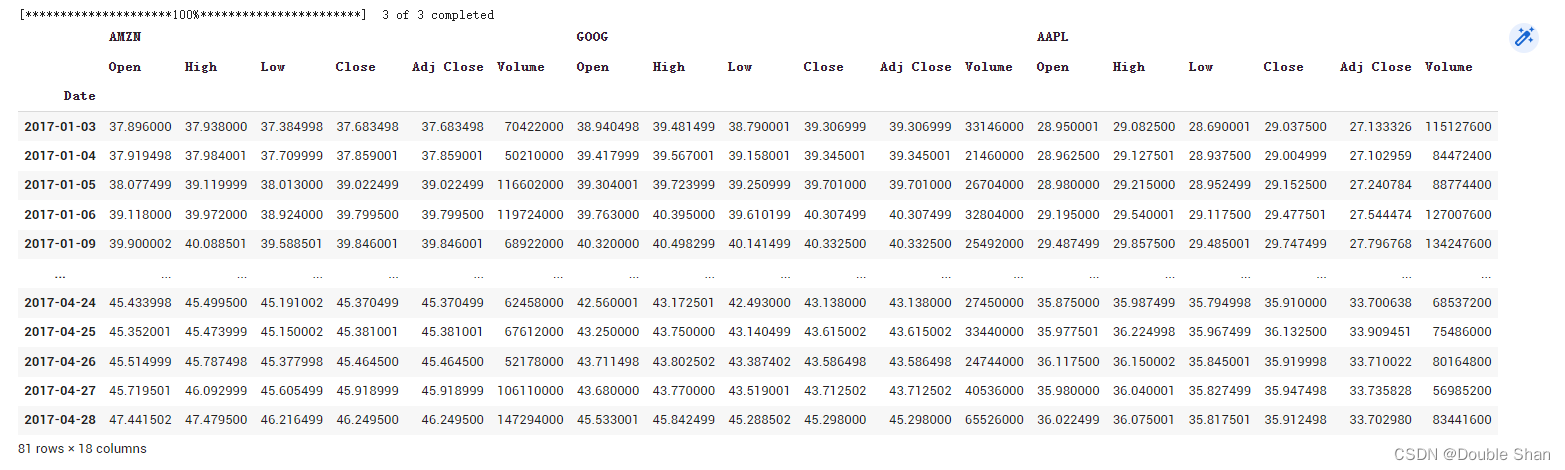
用 yfinance 库下载期权数据
简而言之,期权是赋予交易者权利但没有义务在特定日期或之前以特定价格购买(看涨)或出售(看跌)他们所代表的标的资产的合约。
option_chain()方法:
它将参数作为输入: date:(YYYY-MM-DD),到期日。如果 None 返回所有期权数据。并且有 opt.calls 和 opt.puts 方法。
如何获得到期日期;
aapl.options 
获取对话数据:
opt = aapl.option_chain(date='2020-07-24') opt.calls 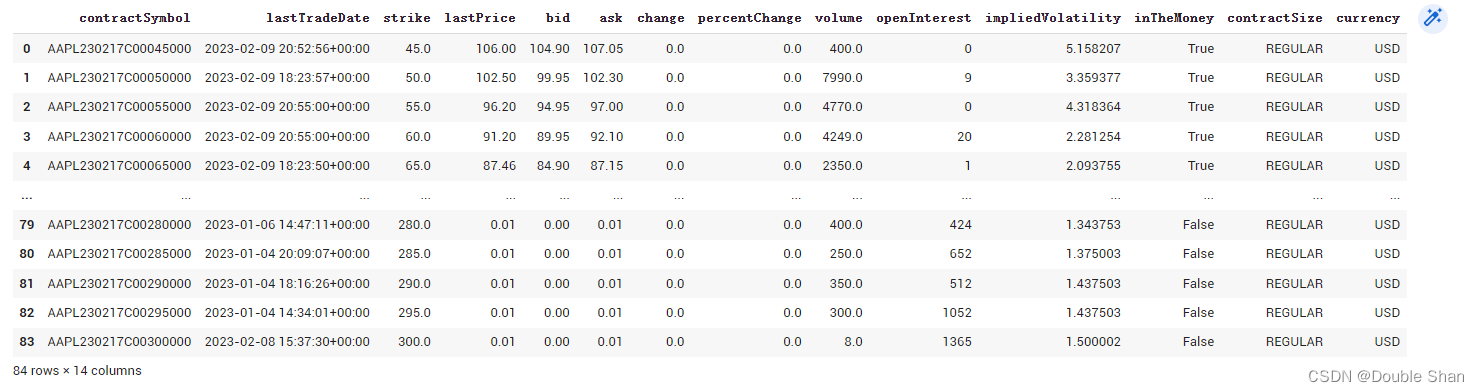
如何获得看跌期权数据:
opt.puts 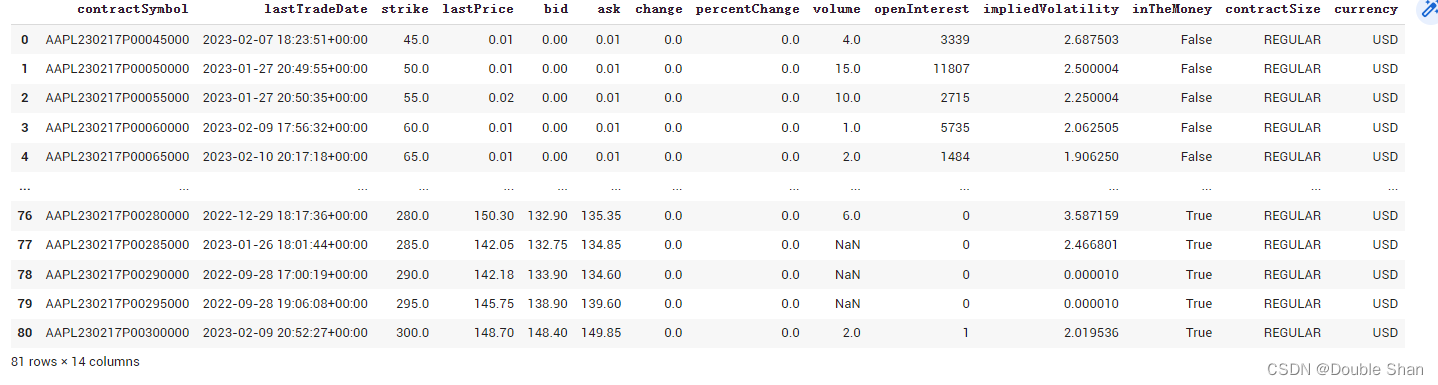
最后, opts 本身会返回一个包含调用和将数据放在一起的代码对象。
pandas_datareader
pandas库提供了专门从财经网站获取金融数据的API接口,可作为量化交易股票数据获取的另一种途径,该接口在urllib3库基础上实现了以客户端身份访问网站的股票数据。需要注意的是目前模块已经迁徙到pandas-datareader包中,因此导入模块时需要由import pandas.io.data as web更改为import pandas_datareader.data as web
DataReader方法介绍
查看Pandas的操作文档可以发现,第一个参数为股票代码,苹果公司的代码为"AAPL",国内股市采用的输入方式“股票代码”+“对应股市”,上证股票在股票代码后面加上“.SS”,深圳股票在股票代码后面加上“.SZ”。DataReader可从多个金融网站获取到股票数据,如“Yahoo! Finance” 、“Google Finance”等,这里以Yahoo为例。第三、四个参数为股票数据的起始时间断。返回的数据格式为DataFrame.
!pip3 install pandas_datareader --upgradeimport pandas_datareader as web #载入数据,雅虎网中的601318.ss股票,从2020-01-01到2020-03-18的数据start_date='2020-01-01'end_date='2020-03-18'data=web.data.DataReader('601318.ss','yahoo',start_date,end_date)data.head()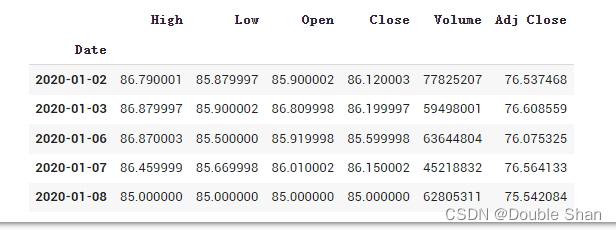
参考:yfinance介绍 pandas_datareader
实例
pip install yfinanceimport yfinance as yfimport pandas as pdDOW_30_TICKER = [ "AXP", "AMGN", "AAPL", "BA", "CAT", "CSCO", "CVX", "GS", "HD", "HON", "IBM", "INTC", "JNJ", "KO", "JPM", "MCD", "MMM", "MRK", "MSFT", "NKE", "PG", "TRV", "UNH", "CRM", "VZ", "V", "WBA", "WMT", "DIS", "DOW",]class YahooDownloader: #通过雅虎金融API接口提供获取日常股票数据 def __init__(self,start_date:str,end_date:str,ticker_list:list):#构造函数,用来实例化对象 self.start_date=start_date self.end_date=end_date self.ticker_list=ticker_list def fetch_data(self,proxy=None): #抓取数据,返回pd.DataFrame 7 columns:A date,open,high,low,close,volume and tick symbol data_df=pd.DataFrame() for tic in self.ticker_list: temp_df=yf.download(tic,start=self.start_date,end=self.end_date,proxy=proxy) temp_df['tic']=tic data_df=data_df.append(temp_df) print("刚下载的数据:") print(data_df.head(5)) data_df = data_df.reset_index() #会将原来的索引index作为新的一列,使日期作为新的一列 print("使日期作为新的一列:") print(data_df.head(5)) try: #修改列名 data_df.columns=["date","open","high","low","close","adjcp","volumn","tic",] #使用调整后的收盘价去代替收盘价 data_df["close"]=data_df["adjcp"] #删除调整后的收盘价那一列 data_df=data_df.drop(labels="adjcp",axis=1) except NotImplementedError: print("the features are not supported currently") #创建一周中的天数(星期一是0,星期天是6):Pandas.Series.dt.dayofweek data_df['day']=data_df['date'].dt.dayofweek #时间字符串转换为年月日方法,可以容易过滤 data_df['date']=data_df.date.apply(lambda x:x.strftime("%Y-%m-%d")) #去除读入的数据中(DataFrame)含有NaN的行。 data_df=data_df.dropna() data_df=data_df.reset_index(drop=True)#重置索引 print("处理后的数据:") print(data_df.head(5)) print("Shape of DataFrame: ", data_df.shape) # print("Display DataFrame: ", data_df.head()) data_df = data_df.sort_values(by=["date", "tic"]).reset_index(drop=True) return data_df df = YahooDownloader(start_date = TRAIN_START_DATE, end_date = TRADE_END_DATE, ticker_list = DOW_30_TICKER).fetch_data()结果显示:
登录后可发表评论
点击登录