ICLR 2023 | 达摩院开源轻量人脸检测DamoFD
团队模型、论文、博文、直播合集,点击此处浏览
一、论文
本文介绍我们被机器学习顶级国际会议ICLR 2023接收的论文 “DamoFD: Digging into Backbone Design on Face Detection"
论文链接:https://openreview.net/pdf?id=NkJOhtNKX91
开源代码(欢迎点赞、收藏、转发三连啊~~~):https://github.com/ly19965/EasyFace/tree/master/face_project/face_detection/DamoFD
二、背景
1. 人脸检测问题定义
人脸检测算法是在一幅图片或者视频序列中检测出来人脸的位置,给出人脸的具体坐标,一般是矩形坐标,它是人脸关键点、属性、编辑、风格化、识别等模块的基础。学术界用来衡量人脸检测器性能的benchmark是[WiderFace](WIDER FACE: A Face Detection Benchmark),该数据集主要明确了人脸检测器面对的一些挑战,包括scale,pose,occlusion等。本文的研究问题是如何自动搜索轻量级人脸检测器的backbone?

图片来自Wider Face 官网
2. 轻量人脸检测器发展
Manual 轻量级人脸检测器设计: 早期的轻量级人脸检测器(FaceBoxes & BlazeFace)均采用Single-stage目标检测器的结构(SSD),并替换为自己手工设计的backbone模块(e.g., Faceboxes引入了Crelu,BlazeFace 引入了DW Conv )。这些方法的共同弊端是无法随着算力约束的变化而自动调整人脸检测器结构,限制了其应用场景。 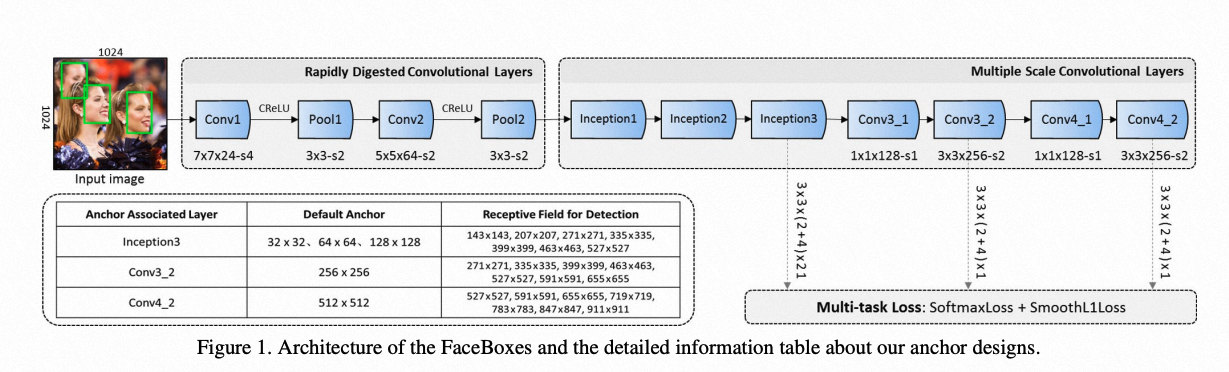 图片来自FaceBoxes 论文
图片来自FaceBoxes 论文
Nas-Based 轻量级人脸检测器: 随着Neural Architecture Search(NAS)技术的兴起,研究人员开始利用Nas来自动化设计人脸检测器的结构, e.g., SPNas in BFBox, DARTS in ASFD,RegNet in SCRFD。SCRFD借鉴了RegNet的思想确定了检测器的搜索空间,并打造了sota性能的轻量级人脸检测器。下图为SCRFD得到的在backbone上的最优算力分配区间 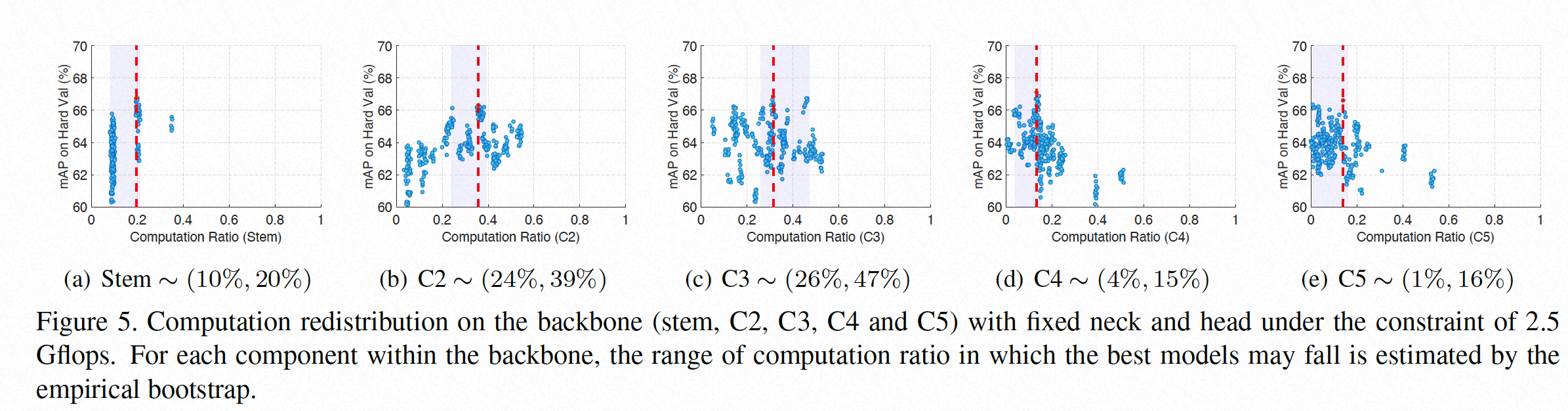 图片来自SCRFD论文
图片来自SCRFD论文
三、方法
1. Motivation
目前的Nas方法主要由两个模块组成,网络生成器和精度预测器。其中网络生成器用于生成候选的backbone结构,精度预测器用来对采样的backbone结构预测精度。由于检测和分类的任务目标不一致,前者更重视backbone stage-level (c2-c5)的表征,而后者更重视high-level(c5)的表征,这就导致了用于分类任务上的精度预测器擅长预测high-level的表征能力而无法预测stage-level的表征能力。因此,在人脸检测任务上,我们需要一个可以预测stage-level表征能力的精度预测器来更好的搜索face detection-friendly backbone。
2. Preliminaries
首先我们介绍下与我们方法相关的背景知识:


3. Method
针对如何设计可以预测stage-level表征能力的精度预测器,我们从刻画network expressivity的角度出发,创新性地提出了SAR-score来无偏的刻画stage-wise network expressivity,同时基于数据集gt的先验分布,来确定不同stage的重要性,进一步提出了DDSAR-score 来刻画detection backbone的精度。
3.1 Adopt Theorem2 to charaterize stage-level network expressivity
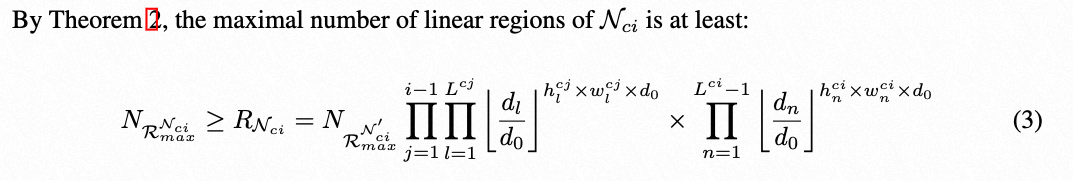
3.2 Two issues ocuur


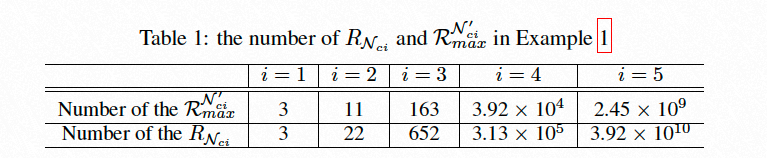
3.3 Stage-aware Expressivity Score
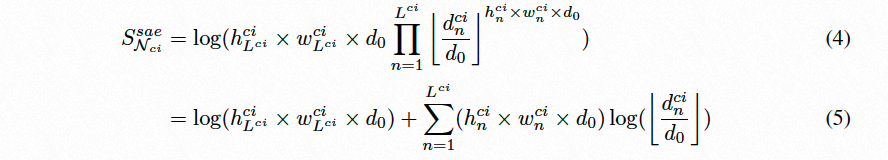
设计准则:

![]()
3.4 Filter Sensitivity Score

3.5 SAR-Score and DDSAR-Score

3.6 Serch Space and Evolutionary Architecture Search


四、结果
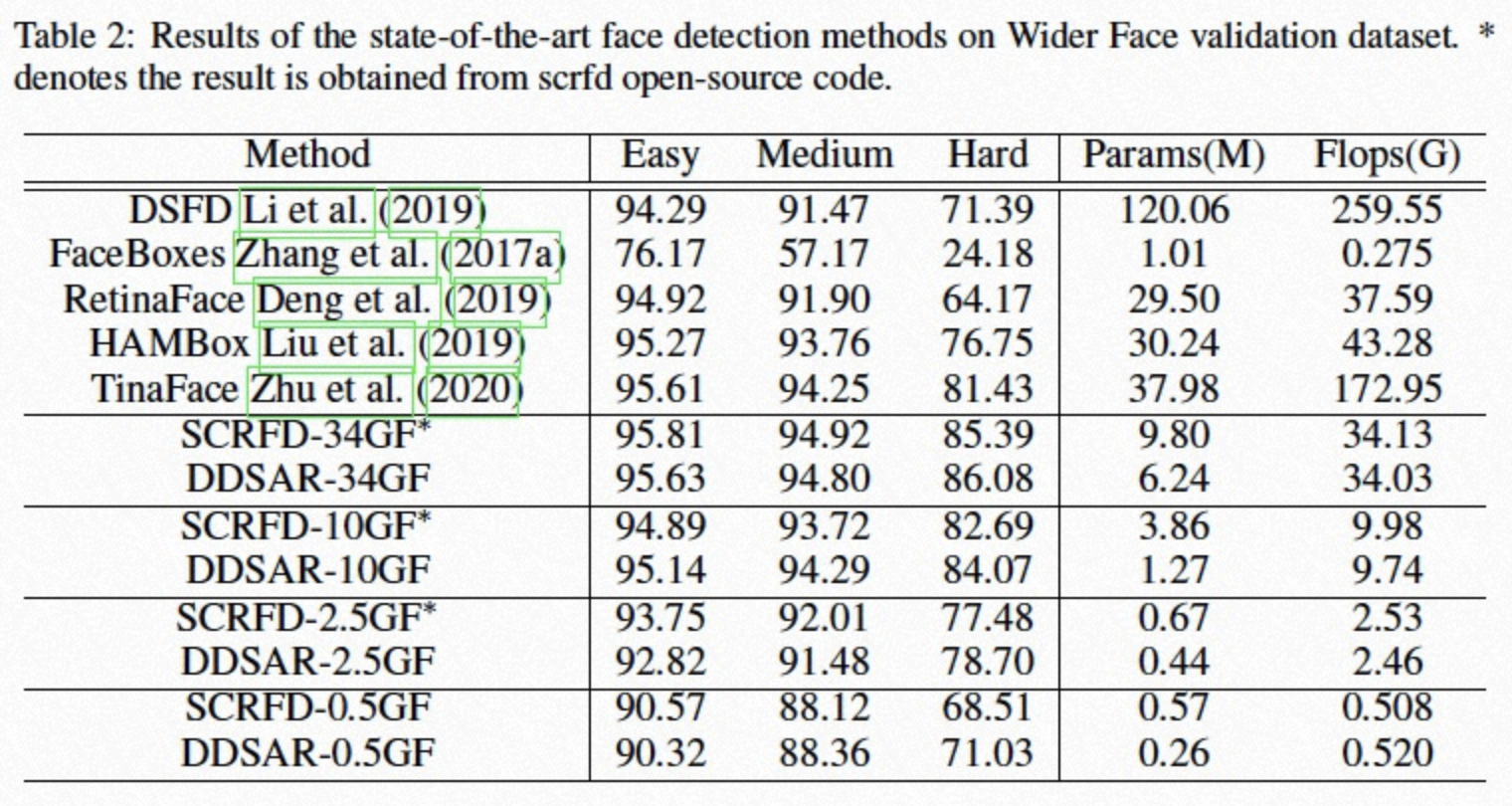
五、展望与应用
减少对超参敏感性:我们在实验的过程中发现DDSAR搜索轻量级(500m)的检测结构时对超参不太敏感,很快就会得到不错的结构,但是搜2.5G, 10G和34G Flops下的检测结构时对超参比较敏感,需要对\alpha以及搜索空间进行调整。可能原因是我们的filter sensitity score 为了加速计算过程,只能近似反应对filter size的敏感性,后续可以从其他角度优化下上述的暴力枚举过程。增强方法在不同检测任务上的普适性: 我们的DDSAR-score是用来刻画检测器表达能力的score,理论上应该在不同检测任务上都应该做的很好。我们目前只考虑了数据集gt的分布,但是不同检测数据集还有数据质量,数据集规模的差异,可以围绕data-centric的思想来对数据集的质量, 数据增强等维度来进一步建立数据集和精度预测器之间的关系,从而实现在不同检测任务上都很有效。更精准的计算网络linear region的数量: 通过linear region的数量来刻画网络的表达能力在ML领域发表了很多paper,可以尝试下更精准的bound或者exact number fo linear region。
登录后可发表评论
点击登录