Python 网络爬虫实战:抖音短视频去水印爬虫详解_亮出锋芒,剑指苍穹
我们知道,在抖音APP中下载到的视频是有水印的,这就催生出了很多抖音短视频去水印的解析网站,小程序等。所以说,抖音短视频去水印这个东西并不是什么新鲜玩意儿,甚至你可以很轻松的在网上搜到抖音去水印的程序源代码。
本文主要是从爬虫程序的角度,讲解遇到这样的问题我们应该如何分析,如何抓包,如何一步步写出自己的爬虫,让大家明白去水印的接口是怎么找到的,网上的代码是怎么写出来的。
我会尽量讲解细致一些,争取让初学者也能看懂。
话不多说,我们开始。
1. 分析问题
首先,从分享链接入手,在抖音APP中分享视频,点击复制链接,即可得到如下所示的分享文字。
1.25 GiC:/ 我把自己拍尴尬了 https://v.douyin.com/RCxwDgH/ 复制此链接,打幵Dou音搜索,直接观看视频!
其中关键的部分 https://v.douyin.com/RCxwDgH/
复制到浏览器中打开后,会跳转到一个网页
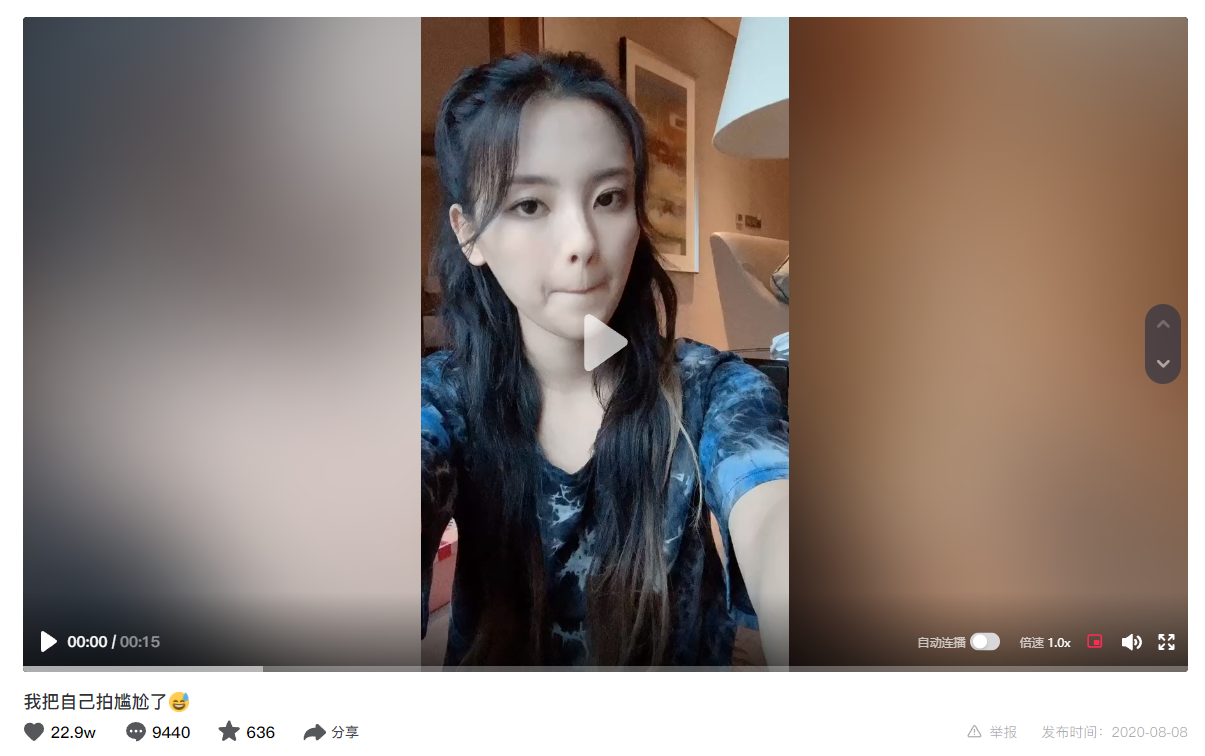
网址是: https://www.douyin.com/video/6858559656789314823?previous_page=app_code_link
我们会发现,网页中的这个视频,是没有水印的!!!
也就是说,我们只需要把网页中的这个视频下载下来就可以了。
1.1 手动操作完成视频去水印
如果你想手动下载的话,其实很简单。
打开浏览器的开发者工具,切换到 Network,过滤器选择 Media,然后刷新网页,这时候就会发现抓到一个请求包。
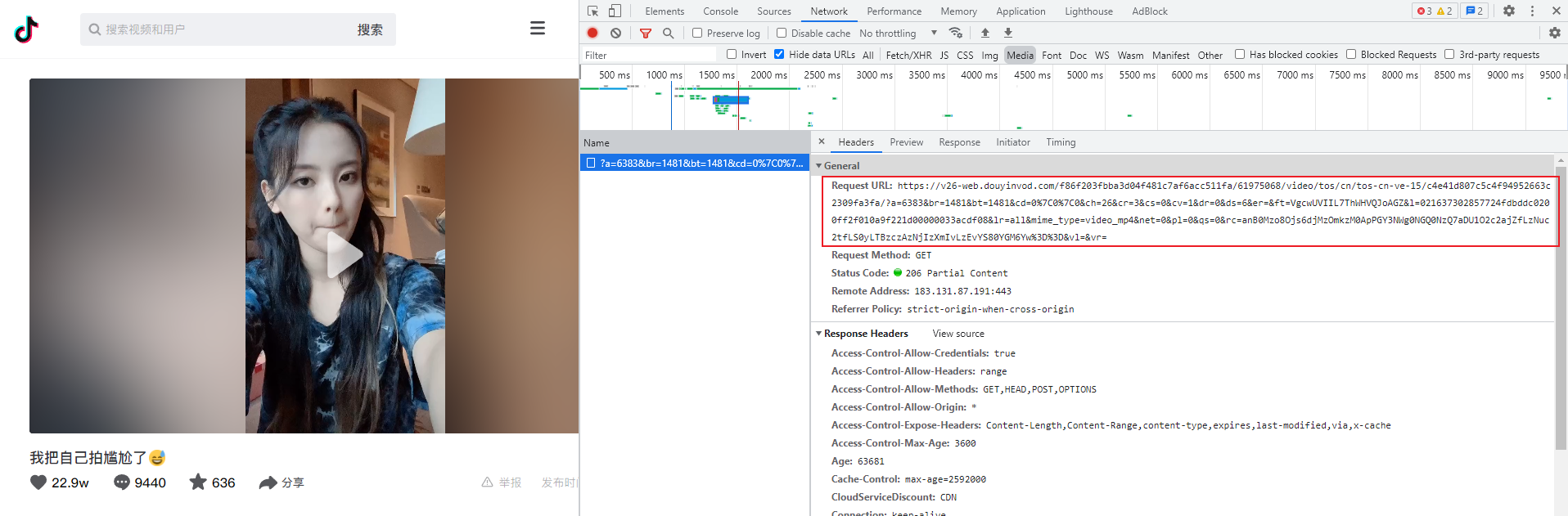
复制 URL 打开,鼠标右键,视频另存为就可以下载了。
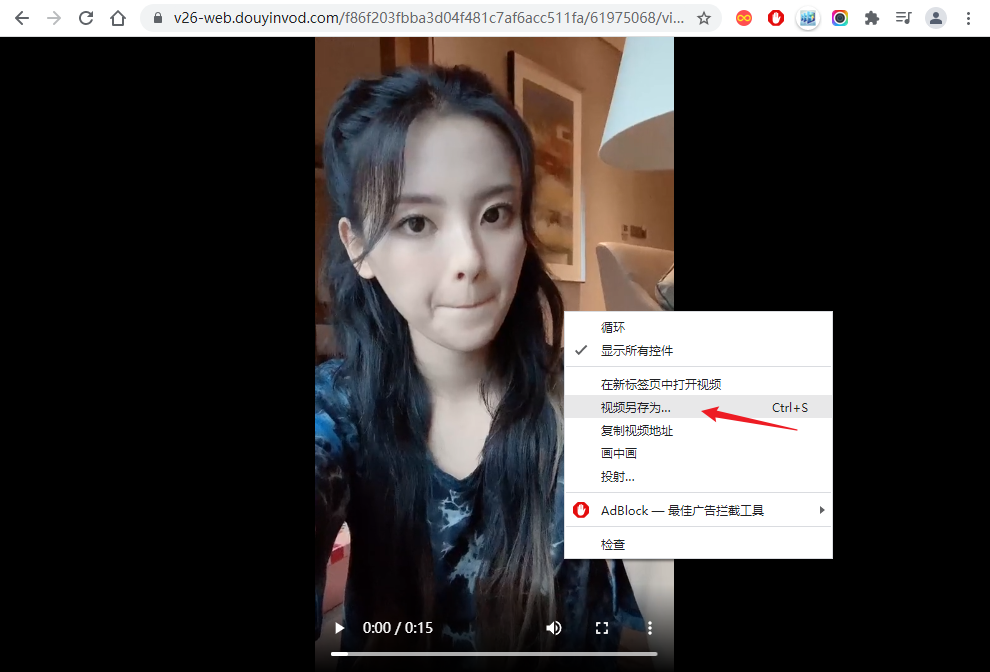
无水印视频链接:https://v26-web.douyinvod.com/f86f203fbba3d04f481c7af6acc511fa/61975068/video/tos/cn/tos-cn-ve-15/c4e41d807c5c4f94952663c2309fa3fa/?a=6383&br=1481&bt=1481&cd=0%7C0%7C0&ch=26&cr=3&cs=0&cv=1&dr=0&ds=6&er=&ft=VgcwUVIIL7ThWHVQJoAGZ&l=021637302857724fdbddc0200ff2f010a9f221d00000033acdf08&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=anB0Mzo8Ojs6djMzOmkzM0ApPGY3NWg0NGQ0NzQ7aDU1O2c2ajZfLzNuc2tfLS0yLTBzczAzNjIzXmIvLzEvYS80YGM6Yw%3D%3D&vl=&vr=
如果大家临时有视频去水印的需求,又不想写代码时,可以试试这个方法。
1.2 用代码完成视频去水印
手动抓包确实简单有效,但是我们目标还是想用代码的方式,来实现一键解析和视频下载。这样纯手动下载显然达不到我们的要求。
我们重新回过头来捋一捋。
首先,我们访问 https://v.douyin.com/RCxwDgH/ 网址时,会重定向跳转到一个别的网址。
这个重定向的过程在浏览器中是一瞬间完成的,这个过程中发生了什么我们并不清楚,不过我们可以通过 Python 来发起请求。
import requests
headers = {
"user-agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 13_2_3 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.0.3 Mobile/15E148 Safari/604.1",
}
url = "https://v.douyin.com/RCxwDgH/"
# 禁止重定向,设置 allow_redirects=False
r = requests.get(url, headers=headers, allow_redirects=False)
print(r.text)
运行结果,是一个 a 标签,href 便是重定向后的地址。

不过,关于重定向的情况,一般我们获取它的 r.headers 在其中查找 location 的值。
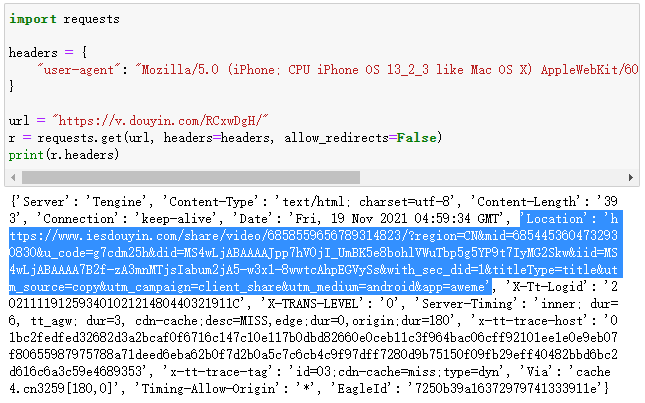
获取到重定向后的地址之后,我们访问该地址。
https://www.iesdouyin.com/share/video/6858559656789314823/?region=CN&mid=6854453604732930830&u_code=g7cdm25h&did=MS4wLjABAAAAJpp7hV0jI_UmBK5e8bohlVWuTbp5g5YP9t7IyMG2Skw&iid=MS4wLjABAAAA7B2f-zA3mnMTjsIabum2jA5-w3x1-8wwtcAhpEGVySs&with_sec_did=1&titleType=title&utm_source=copy&utm_campaign=client_share&utm_medium=android&app=aweme
注:这里有个小坑,如果你用 PC 浏览器直接访问这个地址的话,它又会跳转到另一个网址 https://www.douyin.com/video/6858559656789314823?previous_page=app_code_link ;而用手机浏览器访问的话,地址则维持不变(在开发者工具中,点击图中箭头所指的位置,可以切换成手机浏览器模式)。
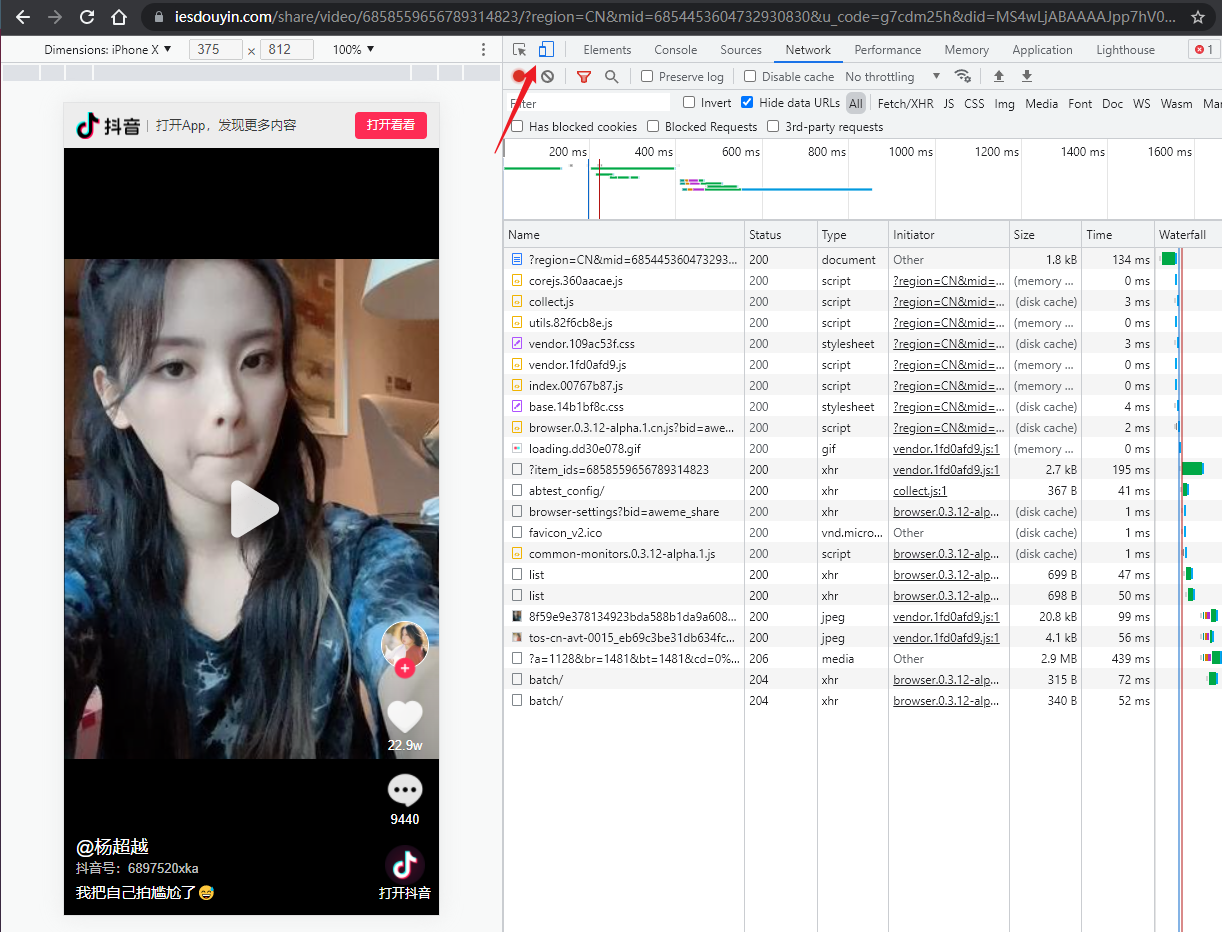
而我们破解无水印短视频的关键接口,在手机浏览器模式下访问才能抓到。
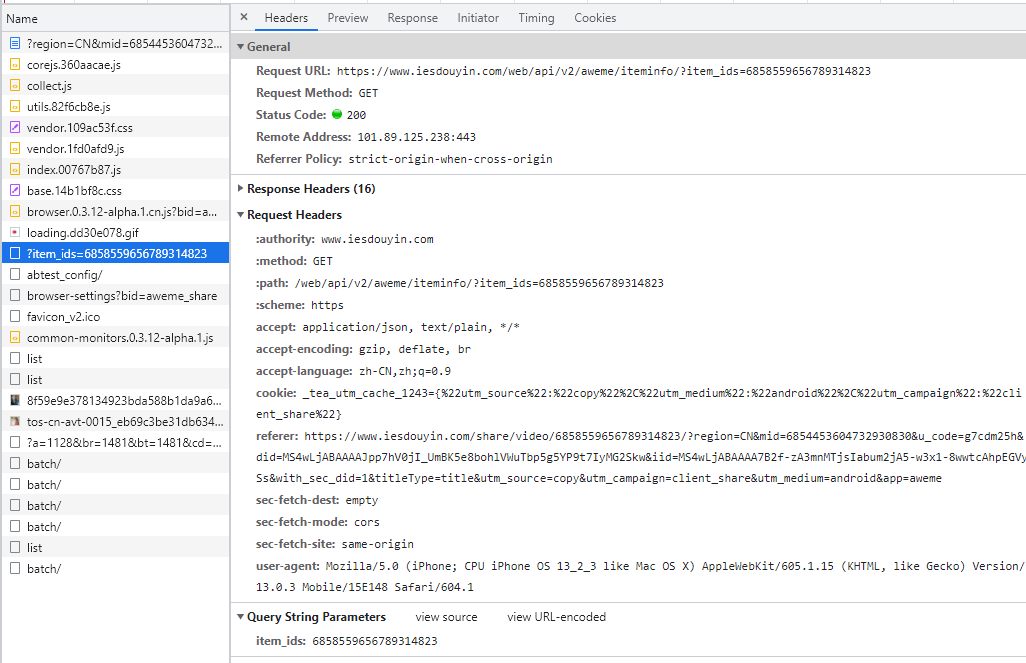
视频信息接口:https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids=6858559656789314823
只有一个参数 item_ids,而它的值在前面重定向的链接中可以获取到。
无水印视频链接就在 item_list[0] -> video -> play_addr -> url_list[0]。
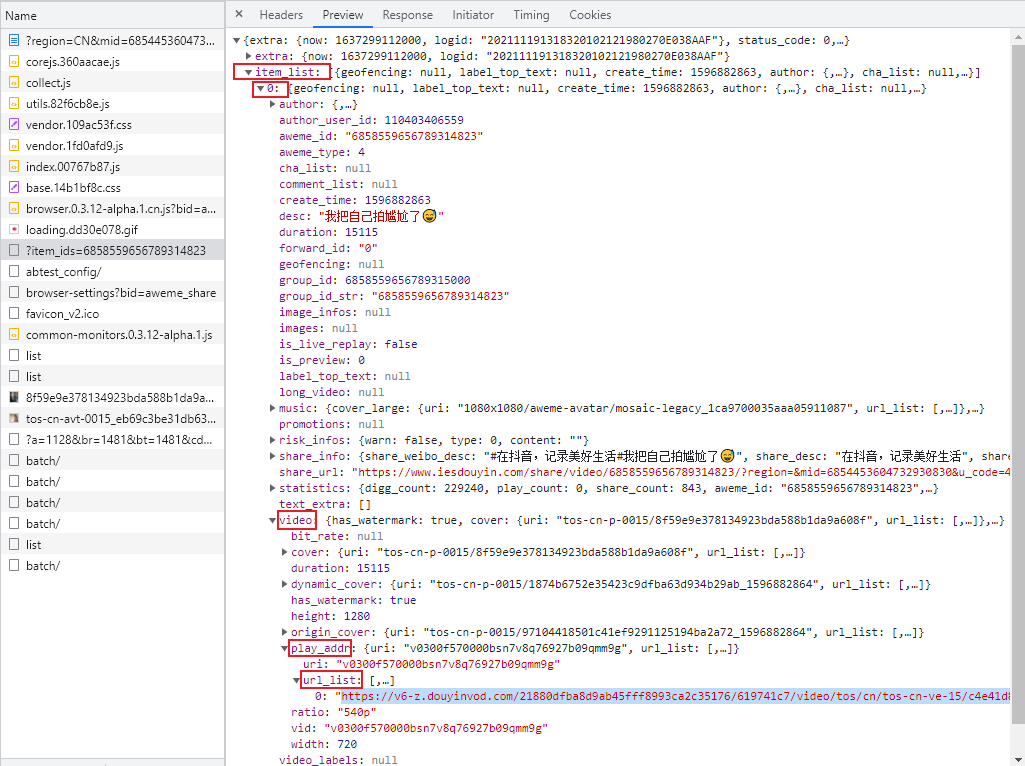
无水印视频链接:https://v6-z.douyinvod.com/21880dfba8d9ab45fff8993ca2c35176/619741c7/video/tos/cn/tos-cn-ve-15/c4e41d807c5c4f94952663c2309fa3fa/?a=1128&br=1481&bt=1481&cd=0%7C0%7C0&ch=96&cr=0&cs=0&cv=1&dr=0&ds=6&er=&ft=5f4rKJmmnPNJ2Xh7ThWwkXAGfdH.Co5TpBZc&l=202111191318320102121980270E038AAF&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=anB0Mzo8Ojs6djMzOmkzM0ApPGY3NWg0NGQ0NzQ7aDU1O2cpaHV2fWVuZDFwekA2ajZfLzNuc2tfLS0yLTBzczAzNjIzXmIvLzEvYS80YGM6Y29zYlxmK2BtYmJeYA%3D%3D&vl=&vr=
上述我们通过两种方法,手动抓包和代码的方式获取到了抖音去水印的视频链接。
2. 编码环节
接下来我们编写代码,完成我们的爬虫程序。
首先是一些准备工作,导入需要的库
import requests
import json
根据 短分享链接 获取重定向后的 长分享链接 的函数
def get_share_url(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3904.108 Safari/537.36",
}
try:
r = requests.get(url, headers=headers, allow_redirects=False)
return r.headers['location']
except Exception as e:
print("解析失败")
print(e)
根据 长分享链接 获取 无水印视频下载链接 的函数
def get_video_url(url):
try:
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3904.108 Safari/537.36",
}
vid = url.split("/?")[0].split("video/")[1]
xhr_url = f'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={vid}'
r = requests.get(xhr_url, headers=headers).json()
video_url = r['item_list'][0]['video']['play_addr']['url_list'][0]
return video_url
except Exception as e:
print("解析失败")
print(e)
下载视频的函数
def download_video(url):
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3904.108 Safari/537.36",
}
try:
r = requests.get(url, headers=headers)
with open('video.mp4', 'wb') as f:
f.write(r.content)
except Exception as e:
print("下载失败")
print(e)
以及主函数
if __name__ == "__main__":
# 抖音APP分享的短链接
url = "https://v.douyin.com/RCxwDgH/"
share_url = get_share_url(url)
video_url = get_video_url(share_url)
download_video(video_url)
print("下载完成")
整理一下代码,完整代码如下:
import requests
import json
headers = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3904.108 Safari/537.36",
}
def get_share_url(url):
try:
r = requests.get(url, headers=headers, allow_redirects=False)
return r.headers['location']
except Exception as e:
print("解析失败")
print(e)
def get_video_url(url):
if not url:
return
try:
vid = url.split("/?")[0].split("video/")[1]
xhr_url = f'https://www.iesdouyin.com/web/api/v2/aweme/iteminfo/?item_ids={vid}'
r = requests.get(xhr_url, headers=headers).json()
video_url = r['item_list'][0]['video']['play_addr']['url_list'][0]
return video_url
except Exception as e:
print("解析失败")
print(e)
def download_video(url, name):
if not url:
return
try:
r = requests.get(url, headers=headers)
with open(name + '.mp4', 'wb') as f:
f.write(r.content)
print("下载完成")
except Exception as e:
print("下载失败")
print(e)
if __name__ == "__main__":
# 抖音APP分享的短链接
url = "https://v.douyin.com/RCxwDgH/"
name = "video2"
share_url = get_share_url(url)
video_url = get_video_url(share_url)
download_video(video_url, name)
print("Finished")
3. 结果展示和总结
3.1 运行结果
运行代码,可以成功解析并下载到无水印视频。

3.2 总结
在这个爬虫的研究过程中,让我有几点收获,跟大家分享一下
-
网址重定向问题,可以在
requests.get函数中,设置参数allow_redirects=False来禁止重定向,这样我们可以细致的了解到 url 请求的整个过程。 -
headers中的user-agent不同,获取到的数据可能也不同,本文的爬虫即是这样,使用 PC浏览器和手机浏览器的UA,会跳转至不同的页面。
如果文章中有哪里没有讲明白,或者讲解有误的地方,欢迎在评论区批评指正,或者扫描下面的二维码,加我微信,大家一起学习交流,共同进步。

登录后可发表评论
点击登录