【C++】unordered_set 容器的最全解析(什么是unordered_set?unordered_set的常用接口有那些?)
目录
一、前言
二、预备知识
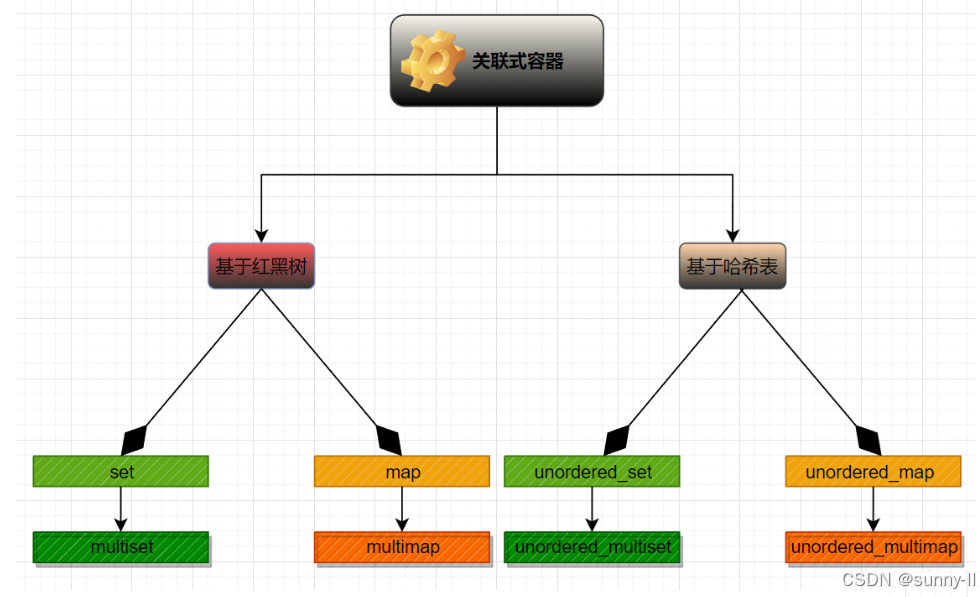
?关联式容器?
?键值对?
?哈希结构的关联式容器?
三、unordered_set 详解
?unordered_set 的介绍
?unordered_set 的构造
?unordered_set 的使用
? insert
?find
? erase
?size
?empty
?swap
?count
?迭代器
?set 和 unordered_set 的区别
?性能测试
四、常考面试题
五、共勉
一、前言
【unordered_set】 是 STL 中的容器之一,不同于普通容器,它的查找速度极快,常用来存储各种经常被检索的数据,因为容器的底层是【哈希表】。除此之外,还可以借助其特殊的性质,解决部分难题。
二、预备知识
在正式学习 unordered_set 之前,首先要有一些预备知识,否则后面可能看不懂相关操作
?关联式容器?
在以往的 【STL 容器】学习中,我们接触到的都是 序列式容器,比如 string、vector、list、deque 等,序列式容器的特点就是 底层为线性序列的数据结构,就比如 list,其中的节点是 线性存储 的,一个节点存储一个元素,其中存储的元素都可序,但未必有序
<key, value> 的 键值对,这就意味着可以按照 键值大小 key 以某种特定的规则放置于适当的位置,关联式容器 没有首尾的概念,因此没有头插尾插等相关操作,本文中学习的 unordered_set 就属于 关联式容器 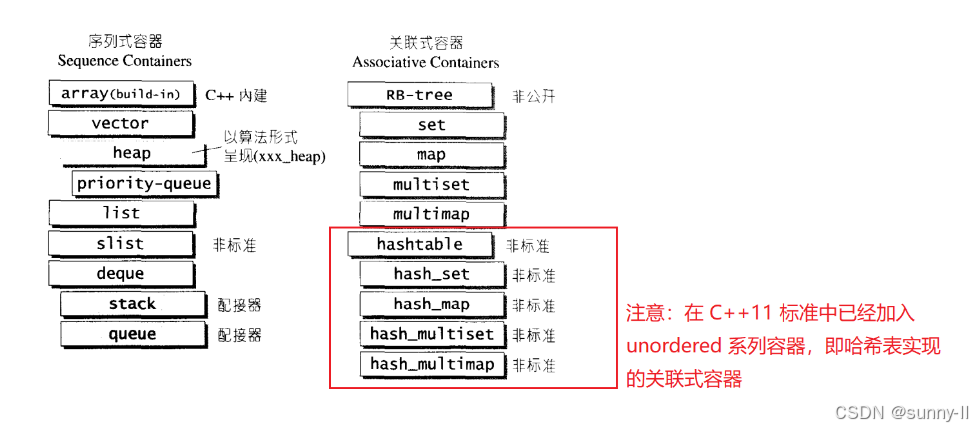
注意: stack、queue 等适配器也属于序列式容器,因为他们的底层是 deque 等容器
?键值对?
【键值对】是 一种用来表示具有一一对应关系的结构,该结构中一般只包含两个成员变量:key 和 value,前者表示 键值,后者表示 实值 关联式容器的实现离不开【键值对】
因此在标准库中,专门提供了这种结构 pair 定义如下 :
//SGI 版 STL 中的实现template <class T1, class T2>struct pair { typedef T1 first_type; typedef T2 second_type; T1 first; T2 second; pair() : first(T1()), second(T2()) {} pair(const T1& a, const T2& b) : first(a), second(b) {} #ifdef __STL_MEMBER_TEMPLATES template <class U1, class U2> pair(const pair<U1, U2>& p) : first(p.first), second(p.second) {}#endif};pair 中的 first 表示 键值,second 则表示 实值,在给 【关联式容器】 中插入数据时,可以构建 pair 对象 比如下面就构建了一个 键值 key 为 string,实值 value 为 int 的匿名 键值对 pair 对象
pair<string, int>("hehe", 123);make_pair,可以根据传入的参数,去调用 pair 构建对象并返回 make_pair("hehe", 123);//构建出的匿名对象与上面的一致make_pair 的定义如下所示:
template <class T1,class T2>pair<T1,T2> make_pair (T1 x, T2 y){ return ( pair<T1,T2>(x,y) );}?哈希结构的关联式容器?
所以在 C++ 标准中,共提供了四种 哈希结构的关联式容器
unordered_setunordered_multisetunordered_mapunordered_multimap 关于 树形结构的关联式容器 将在 二叉搜索树 中学习
树型结构与哈希结构的关联式容器功能都是一模一样的,不过 哈希结构查找比树型结构快得多 -> O(1)
注:
STL 中选择的树型结构为 红黑树 RB-Tree树型结构中的元素 中序遍历 后有序,而哈希结构中的元素无序 三、unordered_set 详解
在C++98中,STL提供了底层为 红黑树结构 的一系列关联容器,在查询时效率可以达到 log(N)。但是在较差的情况下 ,需要比较红黑树的高度次,当树中节点非常多的时候,查询效率也会不理想达到 log(N)
最好的查询是,进行很少的比较次数就能够将元素找到,因此在C++11中,STL又提供了 4 个 unordered系列的关联式容器。
?unordered_set 的介绍
unordered_ set 是 存储 没有特定顺序的唯一元素的容器,允许基于它们的值快速检索单个元素。
在 unordered_ set 中,元素的值与唯一标识它的键同时存在。 键是不可变的,因此,unordered_ set 中的元素在容器中不能被修改,但是它们可以被插入和删除。在内部,unordered_ set 中的元素不按任何特定顺序排序,而是根据它们的哈希值组织到桶中,以允许直接根据它们的值快速访问单个元素(平均平均时间复杂度恒定)。 unordered_ set 容器在通过键访问单个元素时比 set容器更快,尽管它们在通过元素子集进行范围迭代时通常效率较低。 容器中的迭代器至少是前向迭代器。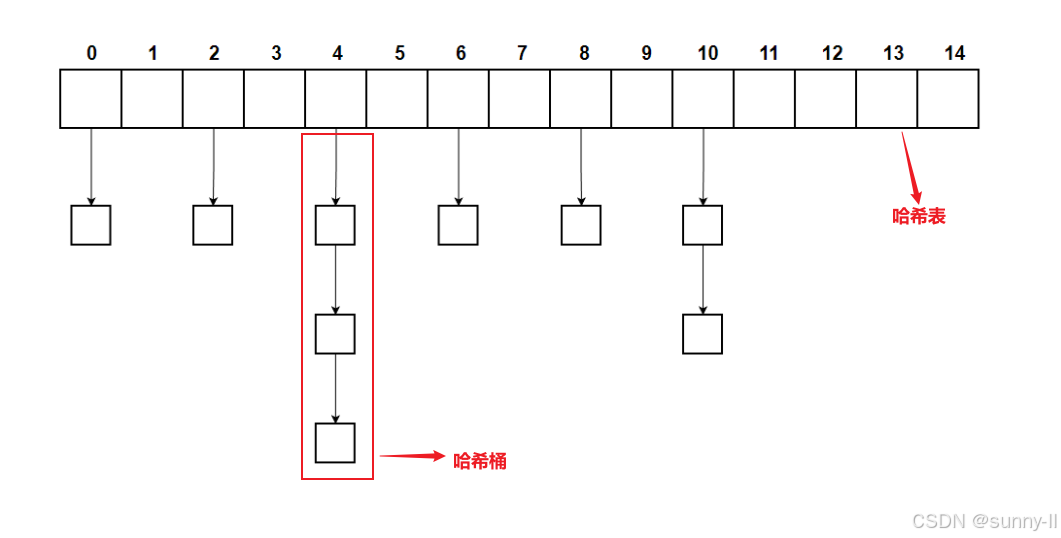
?unordered_set 的构造
构造一个 unordered_ set 容器对象,根据使用的构造函数版本初始化其内容,我们主要掌握3种方式即可:
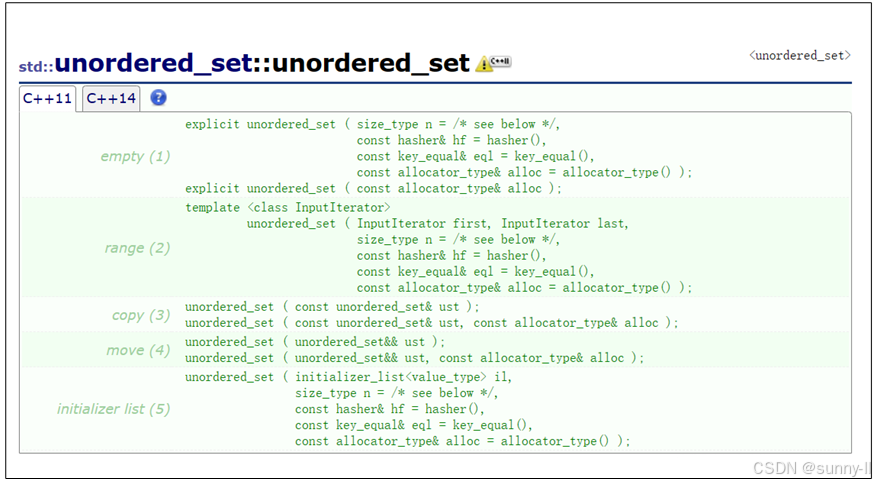
(1)构造一个某个类型的容器
unordered_set<int> s1; // 构造int类型的空容器(2)拷贝构造某个类型的容器
unordered_set<int> us2(us1); // 拷贝构造同类型容器us1的复制品(3)使用迭代器区间进行初始化构造
构造一个 unordered_set 对象,其中包含 【first ,last )中的每一个元素副本。string str("helloworld");unordered_set<char> us3(str.begin(), str.end()); // 构造string对象某段区间的复制品?unordered_set 的使用
unordered_set 的成员函数主要分为:迭代器,容量操作,修改操作。
需要注意的是,对于unordered_ set 而言,它存储的数据是无序的,并组它是一个单向迭代器。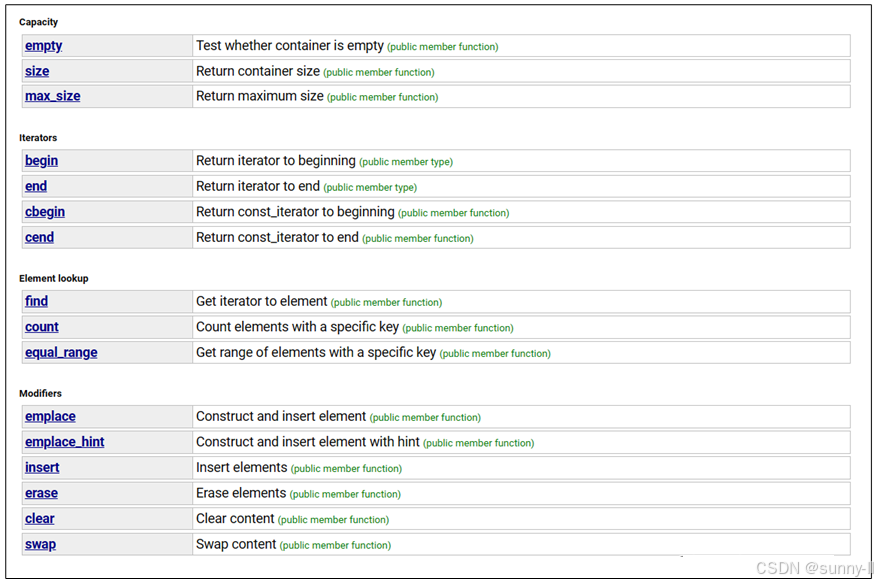
? insert
在unordered_ set 中插入新元素。
每个元素只有在它不等同于容器中已经存在的任何其他元素时才会被插入,也就是说unordered_ set 中的每个元素是唯一的。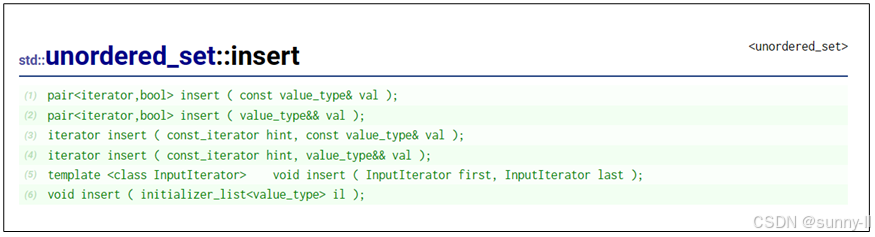
代码示例:
void test_unordered(){unordered_set<int> us1;// 插入元素us1.insert(4);us1.insert(5);us1.insert(2);us1.insert(2);us1.insert(1);us1.insert(3);us1.insert(3);// 遍历for (auto e : us1){cout << e << " ";}}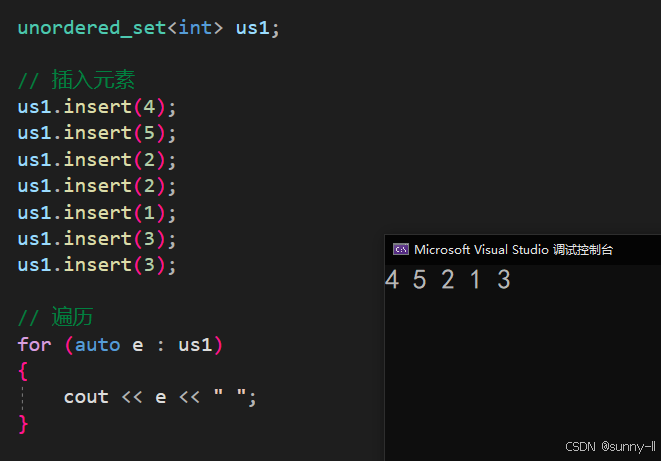
?find
在容器中搜索值为 k 的元素,如果找到它,则返回一个迭代器,否则返回unordered_ set::end (容器末端之 前的元素)的迭代器。

代码示例:
void test_unordered(){unordered_set<int> us;// 插入元素us.insert(4);us.insert(5);us.insert(2);us.insert(2);us.insert(1);us.insert(3);us.insert(3);unordered_set<int>::iterator pos = us.find(3);if (pos != us.end()){cout << "3存在" << endl;}}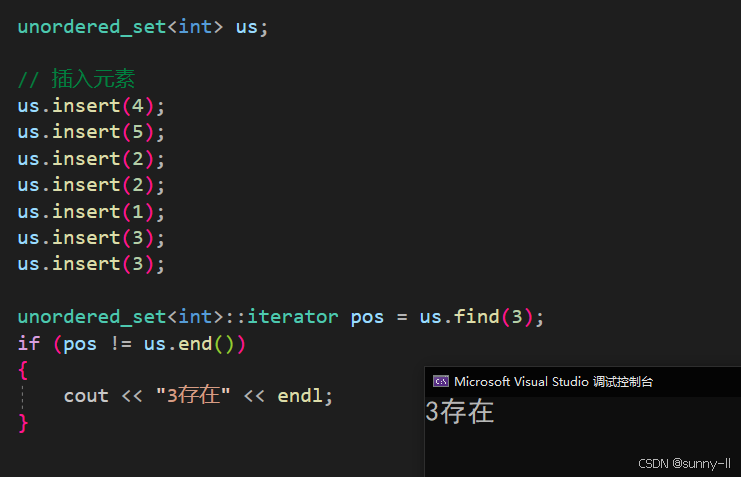
? erase
从 unordered_ set 容器中移除单个元素或一组元素( [first,last) )。
通过调用每个元素的析构函数,这有效地减少了容器的大小。
(1)从容器中删除单个元素(搭配find使用)
void test_unordered(){unordered_set<int> us;// 插入元素us.insert(4);us.insert(5);us.insert(2);us.insert(2);us.insert(1);us.insert(3);us.insert(3);unordered_set<int>::iterator pos = us.find(3);if (pos != us.end()){us.erase(pos); // 删除元素3cout << "删除成功" << endl;}else{cout << "删除失败" << endl;}// 遍历for (auto e : us){cout << e << " ";}}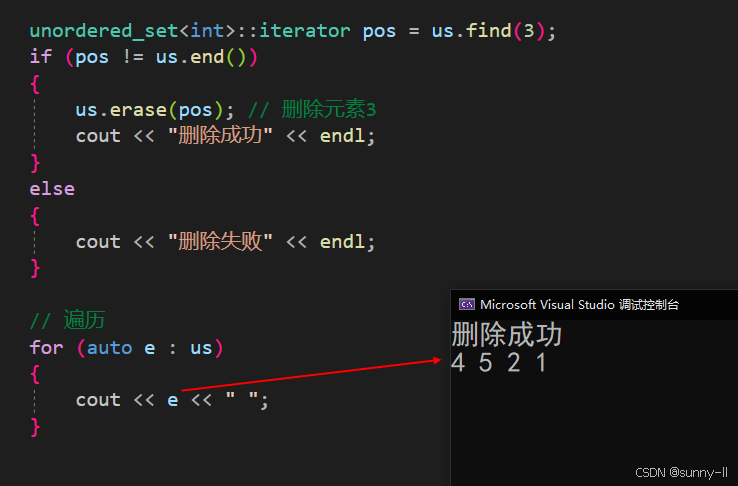
(2)从容器中删除单个元素(直接传要删除的元素)
void test_unordered(){unordered_set<int> us;// 插入元素us.insert(4);us.insert(5);us.insert(2);us.insert(2);us.insert(1);us.insert(3);us.insert(3);us.erase(5); // 删除元素5// 遍历for (auto e : us){cout << e << " ";}}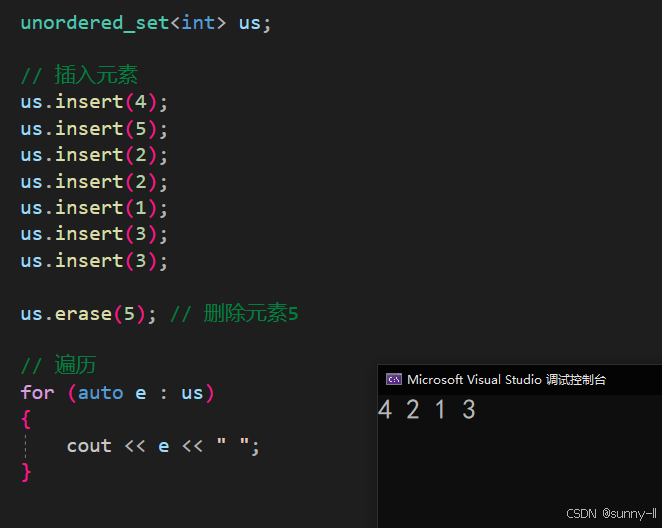
那么它和第 1 种的区别是什么呢?
erase(x) :如果 x 存在就删除;如果不存在,不做任何改变erase(pos):如果 x 存在就删除;如果不存在,此时 pos 位置指向 set::end 的迭代器,那么程序就会报错。其实这种方法本质上可以理解为 erase 去调用了 迭代器 和 find
?size
返回 unordered_set 容器中的元素数量

代码示例:
void test_unordered(){unordered_set<string> us;// 构造元素us = { "milk", "potatoes", "eggs" };cout << "size: " << us.size() << endl;// 插入元素us.insert("pineapple");cout << "size: " << us.size() << endl;// 插入重复元素us.insert("milk");cout << "size: " << us.size() << endl;}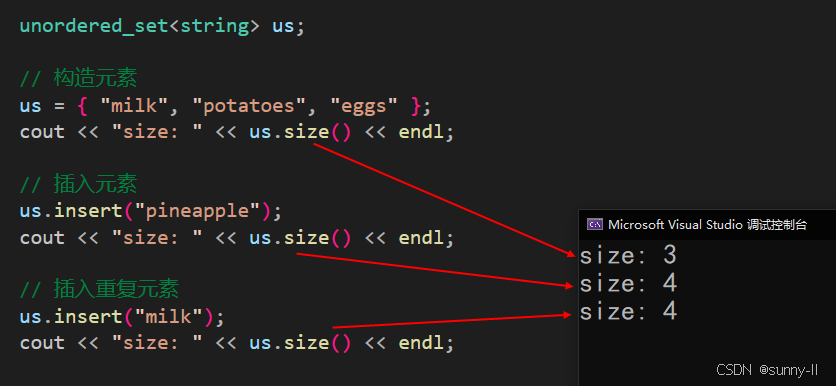
?empty
返回一个bool值,指示unordered_ set 容器是否为空,即其大小是否为0。
这个函数不会以任何方式修改数组的内容。
代码示例:
void test_unordered(){// us1构造3个元素unordered_set<string> us1 = { "milk", "potatoes", "eggs" };// us2构造一个空容器unordered_set<string> us2;cout << "us1 " << (us1.empty() ? "is empty" : "is not empty") << endl;cout << "us2 " << (us2.empty() ? "is empty" : "is not empty") << endl;}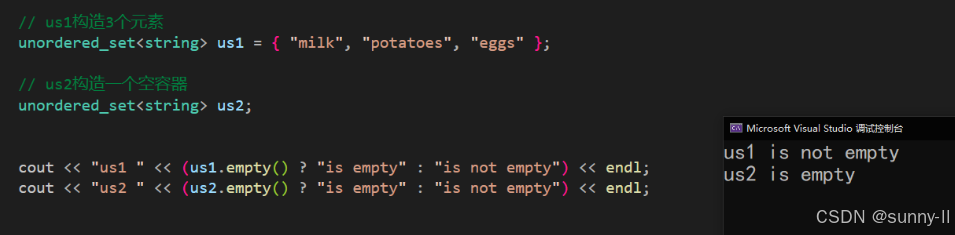
?swap
通过 ust 的内容交换容器的内容, ust 另一个包含相同类型元素的 unordered_ set 对象。大小可能不同。
这个函数在容器之间交换指向数据的内部指针,而不实际对单个元素执行任何复制或移动,允许常量时间执行,无论大小如何。
代码示例:
void test_unordered(){unordered_set<string> us1 = { "iron","copper","oil" };unordered_set<string> us2 = { "wood","corn","milk" };// 交换容器的内容us1.swap(us2);// 遍历us1for (const string& x1 : us1){cout << x1 << " ";}cout << endl;// 遍历us2for (const string& x2 : us2){cout << x2 << " ";}}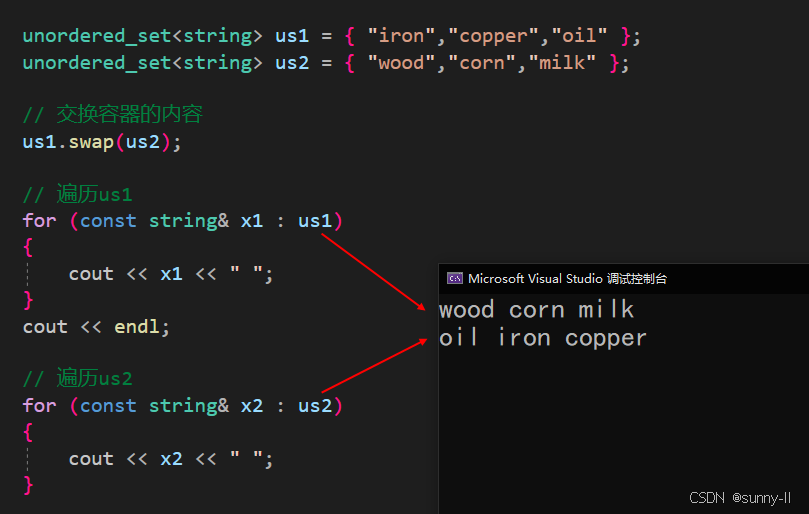
?count
在容器中搜索值为 k 的元素,并返回找到的元素数。
因为 unordered_ set 容器不允许重复值,这意味着如果容器中存在具有该值的元素,则函数实际返回1,否则返回 0。
代码示例:
void test_unordered(){unordered_set<string> us = { "hat", "umbrella", "suit" };// 容器中值为"hat"的元素个数cout << us.count("hat") << endl;// 容器中值为"red"的元素个数cout << us.count("red") << endl;}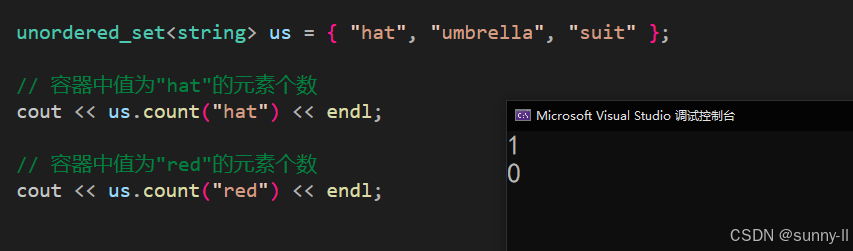
?迭代器
unordered_set 当中迭代器相关函数如下:

注意: set 是双向迭代器,而unordered_ set 是单向迭代器
?set 和 unordered_set 的区别
set 和 unordered_set 是 C++ 标准模板库(STL)中的两种关联容器,它们都有存储唯一元素的特性,但它们在底层实现、元素存储顺序、查找和插入的性能上存在显著的区别。
set:使用自平衡二叉搜索树实现,元素是有序的,适合需要有序存储的场景,操作的时间复杂度是 O(logn)。 unordered_set:使用哈希表实现,元素是无序的,适合只关心元素存在性而不关心顺序的场景,操作的时间复杂度在理想情况下是 O(1)。 ?性能测试
下面是性能测试代码,包含 大量重复、部分重复、完全有序 三组测试用例,分别从 插入、查找、删除 三个维度进行对比
注:测试性能用的是Release 版,这里的基础数据量为 100 w #include <iostream>#include <vector>#include <set>#include <unordered_set>using namespace std;int main(){const size_t N = 1000000;unordered_set<int> us;set<int> s;vector<int> v;v.reserve(N);srand(time(0));for (size_t i = 0; i < N; ++i){//v.push_back(rand());//大量重复//v.push_back(rand()+i);//部分重复//v.push_back(i);//完全有序}size_t begin1 = clock();for (auto e : v){s.insert(e);}size_t end1 = clock();cout << "set insert:" << end1 - begin1 << endl;size_t begin2 = clock();for (auto e : v){us.insert(e);}size_t end2 = clock();cout << "unordered_set insert:" << end2 - begin2 << endl;size_t begin3 = clock();for (auto e : v){s.find(e);}size_t end3 = clock();cout << "set find:" << end3 - begin3 << endl;size_t begin4 = clock();for (auto e : v){us.find(e);}size_t end4 = clock();cout << "unordered_set find:" << end4 - begin4 << endl << endl;cout << s.size() << endl;cout << us.size() << endl << endl;;size_t begin5 = clock();for (auto e : v){s.erase(e);}size_t end5 = clock();cout << "set erase:" << end5 - begin5 << endl;size_t begin6 = clock();for (auto e : v){us.erase(e);}size_t end6 = clock();cout << "unordered_set erase:" << end6 - begin6 << endl << endl;return 0;}插入大量重复数据
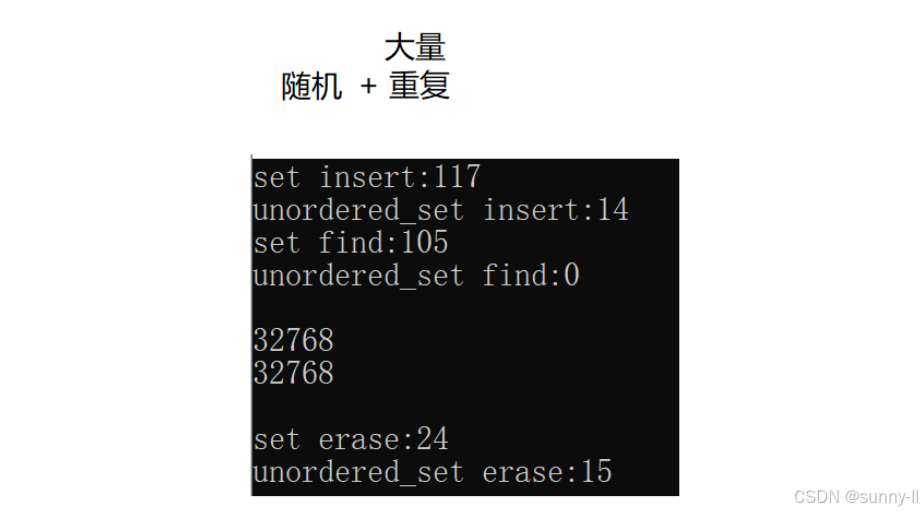
插入数据 大量重复 ---- 结果:
插入:哈希 比 红黑 快88%查找:哈希 比 红黑 快 100%删除:哈希 比 红黑 快 37% 总的来说,在数据 随机 的情况下,哈希各方面都比红黑强,在数据 有序 的情况下,红黑更胜一筹
单就 查找 这一个方面来说:哈希 一骑绝尘,远远的将红黑甩在了身后
四、常考面试题
题目:最长连续序列
链接:128. 最长连续序列 - 力扣(LeetCode)

题目分析:
对于数组中存在的连续序列,为了统计每个连续序列的长度,我们希望直接定位到每个连续序列的起点,从起点开始遍历每个连续序列,从而获得长度。
那么如何获取到每个连续序列的起点呢,或者说什么样的数才是一个连续序列的起点?
答案是这个数的前一个数不存在于数组中,因为我们需要能够快速判断当前数num的前一个数num - 1是否存在于数组中。同时当我们定位到起点后,我们就要遍历这个连续序列,什么时候是终点呢?
答案是当前数num的后一个数nunm + 1不存在于数组中,因此我们需要能够快速判断当前数num的后一个数num + 1是否存在于数组中。为了实现上述需求,我们使用哈希表来记录数组中的所有数,以实现对数值的快速查找。
class Solution {public: int longestConsecutive(vector<int>& nums) { // 记录最长连续序列的长度 int res = 0; unordered_set<int> num_set(nums.begin(),nums.end()); int seqlen; for(auto ch : num_set) { // 如果当前的数是一个连续序列的起点,统计这个连续序列的长度 // 如果 ch - 1 不在 num_set 中,则返回 true;如果 ch - 1 在 num_set 中,则返回 false。 if(!num_set.count(ch-1)) { seqlen = 1; // 连续序列的长度,初始为1 while(num_set.count(++ch)) { seqlen++; // 不断查找连续序列,直到num的下一个数不存在于数组中 } res = max(res,seqlen); } } return res; } };五、共勉
以下就是我对 【C++】unordered_set 容器 的理解,如果有不懂和发现问题的小伙伴,请在评论区说出来哦,同时我还会继续更新【C++】,请持续关注我哦!!!

登录后可发表评论
点击登录