Datawhale AI夏令营第四期 AIGC方向 task02学习笔记
探探前沿:了解一下 AI生图技术 的能力&局限
今天我们的任务是对baseline的代码有一个更加细致的理解,然后我们会学习如何借助AI来提升我们的自学习能力,从而帮助大家在后面的学习工作中如何从容迎接各种挑战。授人以鱼不如授人以渔,你可以从中学大模型的提问技巧来实现快速学习,学会如何制作一个话剧连环画。
‘自其不变者而观之,则物与我皆无尽也’,拥抱AI、学习AI、运用AI解决各种变化的问题,一起加油!!!
1.为什么要了解AI生图前沿?
有些同学可能对于AI可以生成什么样的图片、AI生图有哪些风险和挑战并不是很了解。
在这里我们想先给大家再补充一点背景知识,让大家了解其中的风险和难点。
另外,也将从技术视角拆解AI生图相关工具,让大家更清楚自己的预期场景,能否使用AI生图解决,或部分解决,以及追踪更多AI生图前沿的信息。
AIGC(AI-Generated Content)是通过人工智能技术自动生成内容的生产方式,很早就有专家指出,AIGC将是未来人工智能的重点方向,也将改造相关行业和领域生产内容的方式。
AI生图则是其中最早被大众所熟知并广泛被认可的AIGC领域。AI生成图片的快速发展,使诸多领域措手不及,如:摄影、美术等艺术领域正在面临前所未有的颠覆。我们所认为的“有图有真相”,甚至理解的现实也将不断被挑战...
插入一段小常识,提醒大家警惕Deepfake技术
Deepfake是一种使用人工智能技术生成的伪造媒体,特别是视频和音频,它们看起来或听起来非常真实,但实际上是由计算机生成的。这种技术通常涉及到深度学习算法,特别是生成对抗网络(GANs),它们能够学习真实数据的特征,并生成新的、逼真的数据。
Deepfake技术虽然在多个领域展现出其创新潜力,但其滥用也带来了一系列严重的危害。在政治领域,Deepfake可能被用来制造假新闻或操纵舆论,影响选举结果和政治稳定。经济上,它可能破坏企业形象,引发市场恐慌,甚至操纵股市。法律体系也面临挑战,因为伪造的证据可能误导司法判断。此外,深度伪造技术还可能加剧身份盗窃的风险,成为恐怖分子的新工具,煽动暴力和社会动荡,威胁国家安全。
由此衍生的Deepfake攻防技术,我们在今年夏令营的第二期中,有组织学习活动,具体可以查看:从零入门CV图像竞赛(Deepfake攻防)
对所有人来说,定期关注AI生图的最新能力情况都十分重要:
对于普通人来说,可以避免被常见的AI生图场景欺骗,偶尔也可以通过相关工具绘图
对于创作者来说,通过AI生图的工具可以提效,快速制作自己所需要的内容
对于技术人来说,了解AI生图的能力的玩法,可以更好地针对自己的业务进行开发和使用,甚至攻克难题开发更实用的工具。
2.再来从工具视角回顾一下AI生图的历史
最早的AI生图可追溯到20世纪70年代,当时由艺术家哈罗德·科恩(Harold Cohen)发明AARON,可通过机械臂输出作画。
现代的AI生图模型大多基于深度神经网络基础上训练,最早可追溯到2012年吴恩达训练出的能生成“猫脸”的模型。
它使用卷积神经网络(CNN)训练,证明了深度学习模型能够学习到图像的复杂特征。
2015年,谷歌推出了“深梦”(Deep Dream)图像生成工具,类似一个高级滤镜,可以基于给定的图片生成梦幻版图片。
2021 年 1 月 OpenAI 推出DALL-E模型(一个深度学习算法模型,是GPT-3 语言处理模型的一个衍生版本),能直接从文本提示“按需创造”风格多样的图形设计。
在当时,就已经被一些媒体评价为:“ 秒杀50%的设计行业打工人应该是没有问题的,而且是质量和速度双重意义上的“秒杀” ”。
一般来说,AI生图模型属于多模态机器学习模型,通过海量的图库和文本描述的深度神经网络学习,最终的目标是可以根据输入的指示(不管是文本还是图片还是任何)生成符合语义的图片。
插入一个小八卦
AI生图在很长一段时间很难被人们所广泛接纳,一方面是生成的内容没有可用的生产场景,还有很大程度可能是由于“恐怖谷效应”——
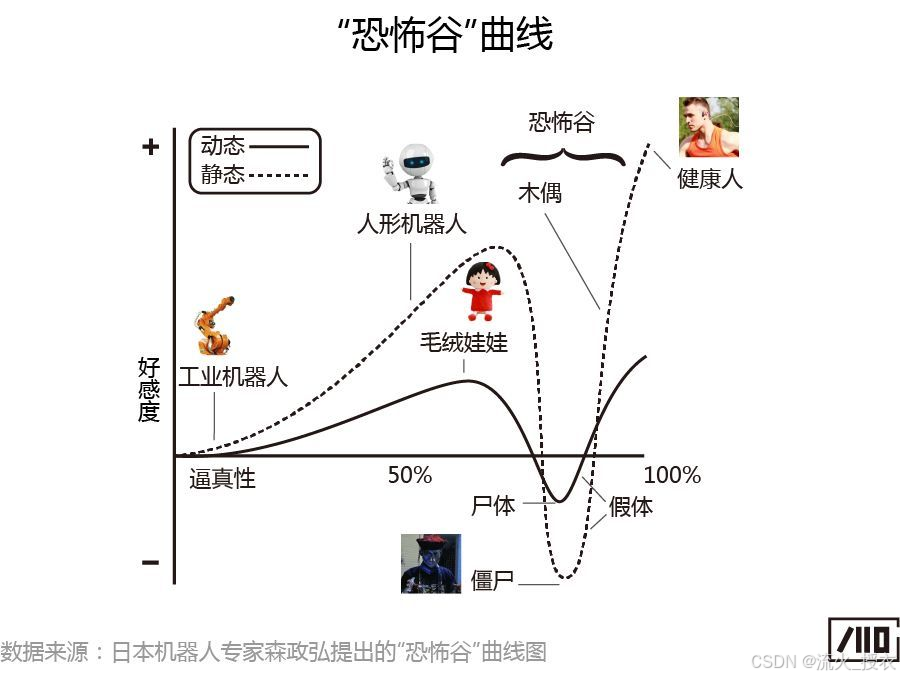
其核心观点是:随着仿真物(如机器人、玩偶等)模拟真实性程度的变化,人们对其亲和力也会产生变化,一般规律是亲和力随着仿真程度增高而增高,但当仿真程度达到一个临界点时,人的亲和反应会陡然跌入谷底,突然产生排斥、恐惧、困惑等负面心理。
通过学习大量画家的作品,AI生图模型 往往可以照猫画虎绘制出类似的画作,在2022年8月,AI生图真正走进了大众的视野,让各个领域无法忽视。
当时让AI生图破圈的是AI绘画作品《太空歌剧院》,该作品在美国科罗拉多州举办的新兴数字艺术家竞赛中获得了比赛“数字艺术/数字修饰照片”类别一等奖,引起了当时“艺术家们 Not Happy”的社会舆论。
3.AI生图的难点和挑战有哪些?
往前一年,AI绘画还不会画“手”。也因为当时这个情况,产生了很多解决这个问题的相关技术,如:给图片里的人手打上标记,像把手掌、拇指、食指啥的,都给清楚地标出来;
我们现在还可以经常在各类自媒体的文章中看到“AI翻车”的案例,那些往往也是需要解决的难点,某些“翻车”现象,也许在业界已有相关的解决方案。
通俗来说,AI生图模型获得图片生成能力主要是通过 学习 图片描述 以及 图片特征,尝试将这两者进行一一对应,存储在自己的记忆里。
在我们需要的时候,通过输入的文字,复现出来对应的图片特征,从而生成了我们需要的图片。
关于AI是否真正理解了图片背后所代表的世界的特征,是否理解了图片的含义,这个一直是科研界和产业界存在争议的话题,我们唯一可以确定的是
由于每个模型用于训练的数据是有限的且不一定相同的,它们能匹配的描述和特征也是有限的,所以在风格、具体事物上,不同的模型会有很大的生成差异,且可能存在诸多与现实不符的情况。
而这些问题,就是业界和科研界持续在想办法解决的问题。
目前已经应用AI生图的行业主要有电商、游戏、设计等,大家感兴趣可以去查看相关研报,下图是在
登录后可发表评论
点击登录