张士玉小黑屋
一个关注IT技术分享,关注互联网的网站,爱分享网络资源,分享学到的知识,分享生活的乐趣。
当前位置:首页 - 第520页
【C++】详解运算符重载,赋值运算符重载,++运算符重载
发布 : xiaoniu | 分类 : 《关于电脑》 | 评论 : 0 | 浏览 : 185次

目录前言运算符重载概念目的写法调用注意事项详解注意事项运算符重载成全局性的弊端类中隐含的this指针赋值运算符重载赋值运算符重载格式注意点明晰赋值运算符重载函数的调用连续赋值传引用与传值返回默认赋值运算符重载前置++和后置++重载前言先梳理一下本篇的脉络,首先会讲解运算符重载的概念,这是本篇的基本概念。其次会讲解赋值运算符的重载,这是本篇的重点,最后是++运算符重载,只需明晰规则即可。此外,希望这篇文章能让大家有所收获,如有不足之处,还请指正,小编会虚心接受并改进质量。运算符重载概念C++引入了运算符重载。它和函数重载的概念类似,可以让一个符号有不同的功能,而具体的功能是由自己实现的。目的是为了增强代码的可读性。C++中有类这个概念。“
娇娇甜言蜜语,狂撩禁欲世子小说,娇娇甜言蜜语,狂撩禁欲世子在线阅读
发布 : xiaoniu | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 89次

《娇娇甜言蜜语,狂撩禁欲世子》是由作者“雪山岚”创作编写的一本连载中古代言情类型小说,苏棠是这本小说的主角,第94章:真面目是这本书的最新章节,已更新197161字。一、作品简介娇娇甜言蜜语,狂撩禁欲世子这本小说的作者是网络作者雪山岚,主角是苏棠。主要讲述了:“准备一桶凉水。”陆照寒哑声命令。书剑不敢耽搁,当即亲自去准备。等凉水拎进来,陆照寒直接兜头浇下。沁骨的冰寒熄灭了他身体里的邪火,勃发的昂扬缓缓恢复成常态。陆照寒发现身体变得正常,吐出一口浊气。一旁的……二、书友评论娇娇甜言蜜语,狂撩禁欲世子这本小说是我一直从头连着看到尾的书,好看,我喜欢看小说,看过很多,喜欢看完结的书。这本还是唯一一本每天追着看的,现在每天只能看一集实在是不过瘾。三、作品赏析“准备一桶凉水。”陆照寒哑
齐峰李欣瑶全文小说最新章节阅读齐峰李欣瑶
发布 : xiaoniu | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 104次

目录:《网游:重生获得BOSS天赋技能》小说介绍《网游:重生获得BOSS天赋技能》小说试读《网游:重生获得BOSS天赋技能》小说介绍《网游:重生获得BOSS天赋技能》是共享打火机的一部穿越重生小说,文章里的内容复杂,一环扣一环,发人深省,人事写的非常鲜明,耐人寻味!小说描述的是:前世就有一个非常牛逼的**魔导师,处心积虑多年,偷学到了龙族的龙语魔法,一跃成为了辉耀阵营十**远程英雄之一。……《网游:重生获得BOSS天赋技能》小说试读炼金是一个前期非常烧钱的生活职业,老宋正愁怎样找门路挤进一些公会,借用公会的平台来成长。可是公会都不傻,不会做亏本买卖,不但要求高,而且条件也非常苛刻。齐峰道:“老宋,你先不要急着高兴。人情归人情,生意归生意!你
(抖音小说)夏沐萧明谦小说全文阅读免费
发布 : xiaoniu | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 102次

目录:《夏沐萧明谦》小说介绍《夏沐萧明谦》小说试读《夏沐萧明谦》小说介绍主角是夏沐萧明谦的豪门总裁小说《夏沐萧明谦》,本书是由作者“夏沐”创作编写,书中精彩内容是:我去见了我姐姐最后一面,我姐姐的身体被折磨的没一块好肉了,上面全是被香烟烫出来的……《夏沐萧明谦》小说试读软腰堪堪一尺六,两边S型,美的像瓷花瓶口。小腹平坦无暇,才男人一巴掌那么大。我看到萧明谦的目光落在我的腰上,目光立刻暗沉炙烈了几分。我佯装不知,用小手指指了指腰间的青紫掐痕,“这里先生。”刚才商烟下了狠手,恨不得将我腰上的肉给拧下来。没关系,我自会在她老公这里讨回来。萧明谦坐在了我的床上,修长的食指抹了一点药膏,然后涂抹到了我的腰上。男人的手指带着清凉的药膏一碰到我的娇肌,我
《太子手握读心术,朝廷大瓜全在我手》小说大结局免费试读 朱标朱元璋小说
发布 : xiaoniu | 分类 : 《资源分享》 | 评论 : 0 | 浏览 : 96次

宫殿内,掌着数盏油灯,噼里啪啦的燃烧着。燃烧的似乎是某些人的命。朱元璋身穿皮弁服,皮弁帽,正坐高堂,满脸肃穆的看着这个年近花甲的老人。“皇上,圣福金安。”安进跪在地上,颤抖的说道。“朕安。”朱元璋:“起来吧。”“谢皇上。”“安进啊,你是前朝老人,在本朝跌爬滚打三十年,为大明付出了卓越的贡献。”“在这里,朕向你给予高度肯定。”安进:“谢皇上慈训,老臣感恩不尽。”朱元璋:“嗯,湖北布政使,去年的粮税,和茶税,少了一成半,朕本以为是天灾所致,没有细看。”“结果还是你老眼如火,发现了端倪,是那群王八蛋,欺上瞒下,最终难逃法网。”“你是咱们大明的功臣啊。”安进连忙作揖:“臣,不敢居功。”朱元璋:“对了,户部尚书杨靖多大了。”安进:“回皇上,六十有七了。”都六十七了啊。
Docker安装WebRTC下TURN服务
发布 : xiaoniu | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 182次
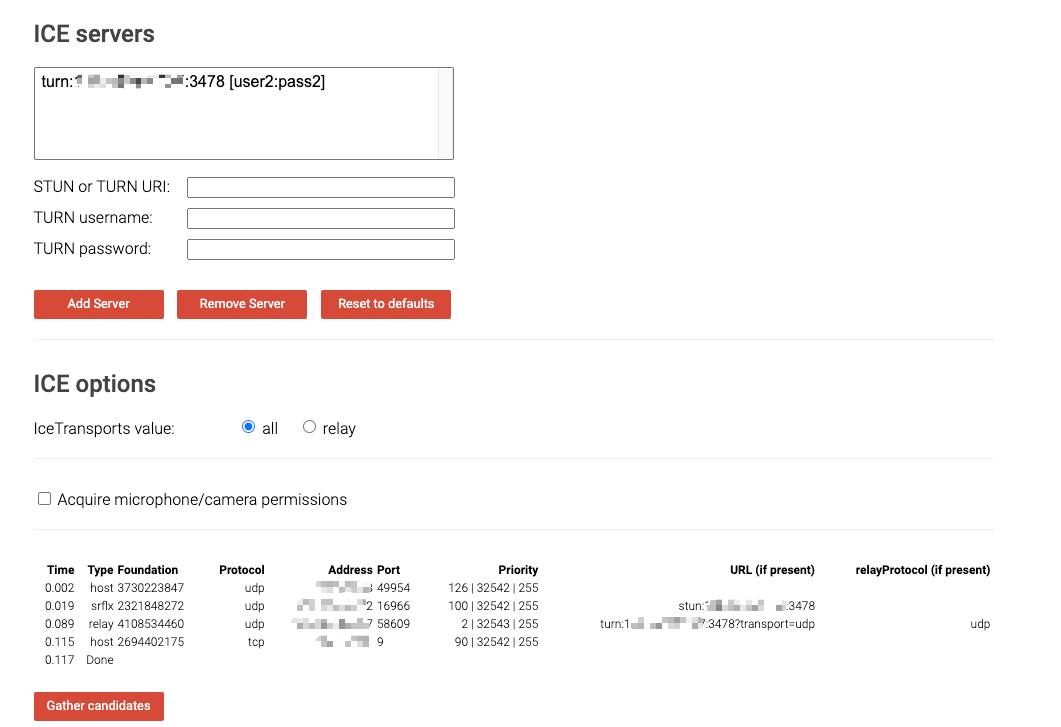
详细实现方式以及代码下载请前往 https://www.passerma.com/article/90实现效果一、手动构建镜像1.新建Dockerfile文件文件用于编译镜像以alpine为基础镜像添加coturn需要的依赖库获取coturn并进行编译通过start.sh启动turnserver服务DockerfileFROMalpineRUNapkaddmake\gcc\g++\wget\libevent-dev\openssl-dev\libffi-dev\curlRUNwgethttps://github.com/coturn/coturn/archive/4.5.1.3.tar.gz\&&
飒爽女医温暖暖季源泽,飒爽女医免费在线阅读
发布 : xiaoniu | 分类 : 《随便一记》 | 评论 : 0 | 浏览 : 96次

《飒爽女医》免费试读第24章这件事情也有林秀莲的份儿!郑娟见宋甜是真的打定主意不会原谅她,她立刻就变得疯癫起来。“宋甜,你凭什么怪我?我做这些也都是被你逼的!大家都是人,凭什么你就能轻轻松松地来下乡?你父母随便找找关系就能给你在卫生院安排一个工作,而我呢?我家里不仅帮不到我还要吸我的血!我也是为了能更好的活下去!我根本没想要你的命,只是想借机要你的工作而已!你之前不是说我们是好朋友,你会帮我的吗?我看你说的话根本就不算数!你宁愿把工作让给温暖暖都从来没有考虑过,你就别假惺惺的说把我当成好朋友了!”她瞪着宋甜,眼神凶恶,在喊完这些话之后竟然站起身直直的朝着宋甜扑了过去。看那样子像是想要宋甜的命。温暖暖反应很快,在她冲过来的时候就一脚踢了过去。这一脚正中郑娟的胸口。郑娟
Suno AI:国内能不能用吗官方网站打不开进不去终极解决办法?
发布 : xiaoniu | 分类 : 《关注互联网》 | 评论 : 0 | 浏览 : 272次
SunoAi:你知道在国内能不能用吗?HAO简单音乐网haojiandanbianqu.com 如果需要解决任何关于SUNOai您可以联系我们帮您解决AI音乐软件问题中文歌曲创作中的人工智能技术趋势当前人工智能在中文歌曲创作领域的应用现状当前,人工智能在中文歌曲创作领域已经展现出了巨大的潜力。通过AI技术,用户可以轻松地生成中文歌词、编曲和音乐制作,极大地提高了创作的效率和便利性。一些AI工具如SunoAI已经开始支持中文歌曲创作,并且拥有商用授权,为中文音乐创作者提供了全新的可能性。未来发展趋势和可能的挑战未来,随着人工智能技术的不断发展,中文歌曲创作领域也将迎来更多的机遇和挑战。其中可能的趋势包括:更加智能和个性化的创作辅助:AI将更加深入了解用户
岑诗珊裴奕【全章节】岑诗珊裴奕完结版免费阅读
发布 : xiaoniu | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 91次

目录:《岑诗珊裴奕》小说介绍《岑诗珊裴奕》小说试读《岑诗珊裴奕》小说介绍《岑诗珊裴奕》这部现代言情类型的小说很吸引人,是由作者岑诗珊写的!主角为岑诗珊裴奕小说描述的是:那张俊美如神祇的脸出现在聚光灯下时,观众的声音几乎掀翻顶棚。其他嘉宾纷纷惊叹:“裴影……《岑诗珊裴奕》小说试读现场,所有人更是屏气凝神。裴奕抬起头看向我,眸中一片冷然。那目光让我的手轻颤起来,手机几乎就要坠落下去。我从未想过掉马甲会是这样的场景。曾经心心念念的人近在咫尺,可我却连承认我是谁的资格都没有。一旁,好事的女嘉宾故作惊讶:“天哪,没想到诗珊你竟然玩过这个游戏,级别还这么高,看来今天要靠诗珊带我们飞了。”裴奕大火后,曾经游戏的视频也被扒出来,我们的情侣头像更是引起一众网
瞎编功法徒弟直接成圣李玄许炎小说阅读,瞎编功法徒弟直接成圣无删减版
发布 : xiaoniu | 分类 : 《休闲阅读》 | 评论 : 0 | 浏览 : 85次

男女主角是李玄许炎的小说瞎编功法徒弟直接成圣推荐给大家阅读,故事精彩纷呈,引人入胜,主要讲述了:云山县令闻言点头道:“可以,都发动教众,去找宝药,不过我们也要藏一点,这宝药说不定,对修炼武道有用处。”麻衣老者也频频点头认可。石二接着又道:“另外,高人想要见一见天母。”“那就把消息传给天母,让天母…《瞎编功法徒弟直接成圣》免费试读第五十九章去皇宫磨练心境的许炎云山县令闻言点头道:“可以,都发动教众,去找宝药,不过我们也要藏一点,这宝药说不定,对修炼武道有用处。”麻衣老者也频频点头认可。石二接着又道:“另外,高人想要见一见天母。”“那就把消息传给天母,让天母自己做决定。”麻衣老者拍板道。“另外,高人在云山县的消息,不得泄露出去,否则郡城、乃至京城的人,都会跑来打扰了高人!”云山
search zhannei
最新文章
-
- (书荒必看)陆绍霆宋息息(七零换亲当后妈,冷面硬汉夜夜都回家)无删减在线下载阅读最终终章
- 权姈珃封昱珩:结局+番外新上热文新章速递封昱珩权姈珃:结局+番外评价五颗星
- 转正名额被换后,男友护着的实习生悔不当初章节目录_沈悠悠思琪姐方庭宇续集_小说后续在线阅读_无删减免费完结_
- 裴浔州叶粟续集(叶粟裴浔州)全本完整免费版_起点章节+后续(裴浔州叶粟)
- 老公装瞎两年,只为给我赎罪的机会续集_邓丛婆婆尹一夏知乎热门_小说后续在线阅读_无删减免费完结_
- 终章小说重生七零,彪悍军嫂是朵黑莲花完结篇(武天娇傅长卿)已更新+延伸(重生七零,彪悍军嫂是朵黑莲花)清爽版
- 作精丈夫第一百次提离婚后我搞垮了他的公司未删减_顾辞周言小姑娘免费赏析_小说后续在线阅读_无删减免费完结_
- 独家苏玉宁闻君尧:结局+番外精编之作(闻君尧苏玉宁)电子书畅享阅读
- 因为我家猫出车祸,我将北大改成大专后续+完结_夏夏黄知夏爸爸妈妈独家番外_小说后续在线阅读_无删减免费完结_
- 顾北域慕嬨小说完本(顾北域慕嬨)(慕嬨顾北域)前传+整本阅读全新作品预订
- 我五感尽失后,自称与动物共感的男友青梅慌了新书_橙橙青梅陈奕内容精选_小说后续在线阅读_无删减免费完结_
- 闻君尧苏玉宁彩蛋小说结尾+附加(苏玉宁闻君尧)清爽版阅读
Copyright © 2020-2022 ZhangShiYu.com Rights Reserved.豫ICP备2022013469号-1